 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMINTY: Rule-based Models that Minimize the Need for Imputing Features with Missing Values
Nov 23, 2023



Rule models are often preferred in prediction tasks with tabular inputs as they can be easily interpreted using natural language and provide predictive performance on par with more complex models. However, most rule models' predictions are undefined or ambiguous when some inputs are missing, forcing users to rely on statistical imputation models or heuristics like zero imputation, undermining the interpretability of the models. In this work, we propose fitting concise yet precise rule models that learn to avoid relying on features with missing values and, therefore, limit their reliance on imputation at test time. We develop MINTY, a method that learns rules in the form of disjunctions between variables that act as replacements for each other when one or more is missing. This results in a sparse linear rule model, regularized to have small dependence on features with missing values, that allows a trade-off between goodness of fit, interpretability, and robustness to missing values at test time. We demonstrate the value of MINTY in experiments using synthetic and real-world data sets and find its predictive performance comparable or favorable to baselines, with smaller reliance on features with missing values.
Pure Exploration in Bandits with Linear Constraints
Jun 22, 2023We address the problem of identifying the optimal policy with a fixed confidence level in a multi-armed bandit setup, when \emph{the arms are subject to linear constraints}. Unlike the standard best-arm identification problem which is well studied, the optimal policy in this case may not be deterministic and could mix between several arms. This changes the geometry of the problem which we characterize via an information-theoretic lower bound. We introduce two asymptotically optimal algorithms for this setting, one based on the Track-and-Stop method and the other based on a game-theoretic approach. Both these algorithms try to track an optimal allocation based on the lower bound and computed by a weighted projection onto the boundary of a normal cone. Finally, we provide empirical results that validate our bounds and visualize how constraints change the hardness of the problem.
Unsupervised domain adaptation by learning using privileged information
Mar 17, 2023



Successful unsupervised domain adaptation (UDA) is guaranteed only under strong assumptions such as covariate shift and overlap between input domains. The latter is often violated in high-dimensional applications such as image classification which, despite this challenge, continues to serve as inspiration and benchmark for algorithm development. In this work, we show that access to side information about examples from the source and target domains can help relax these assumptions and increase sample efficiency in learning, at the cost of collecting a richer variable set. We call this domain adaptation by learning using privileged information (DALUPI). Tailored for this task, we propose a simple two-stage learning algorithm inspired by our analysis and a practical end-to-end algorithm for multi-label image classification. In a suite of experiments, including an application to medical image analysis, we demonstrate that incorporating privileged information in learning can reduce errors in domain transfer compared to classical learning.
Practicality of generalization guarantees for unsupervised domain adaptation with neural networks
Mar 15, 2023Understanding generalization is crucial to confidently engineer and deploy machine learning models, especially when deployment implies a shift in the data domain. For such domain adaptation problems, we seek generalization bounds which are tractably computable and tight. If these desiderata can be reached, the bounds can serve as guarantees for adequate performance in deployment. However, in applications where deep neural networks are the models of choice, deriving results which fulfill these remains an unresolved challenge; most existing bounds are either vacuous or has non-estimable terms, even in favorable conditions. In this work, we evaluate existing bounds from the literature with potential to satisfy our desiderata on domain adaptation image classification tasks, where deep neural networks are preferred. We find that all bounds are vacuous and that sample generalization terms account for much of the observed looseness, especially when these terms interact with measures of domain shift. To overcome this and arrive at the tightest possible results, we combine each bound with recent data-dependent PAC-Bayes analysis, greatly improving the guarantees. We find that, when domain overlap can be assumed, a simple importance weighting extension of previous work provides the tightest estimable bound. Finally, we study which terms dominate the bounds and identify possible directions for further improvement.
Case-based off-policy policy evaluation using prototype learning
Nov 22, 2021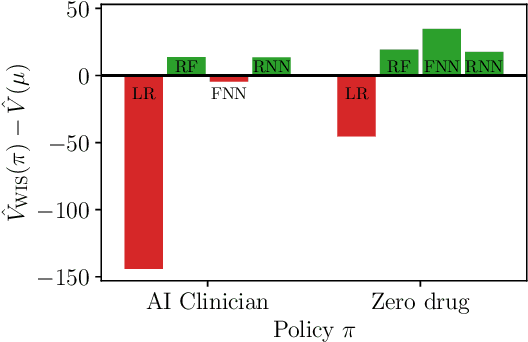
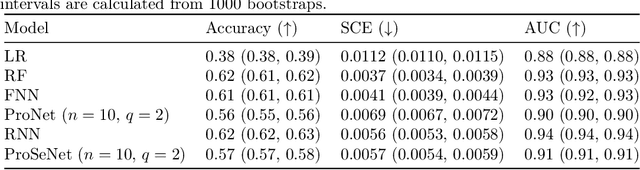
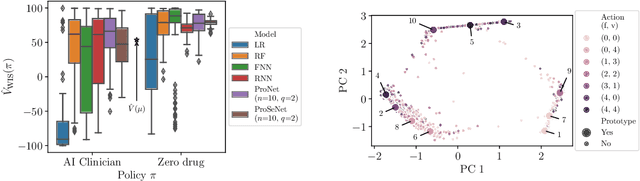
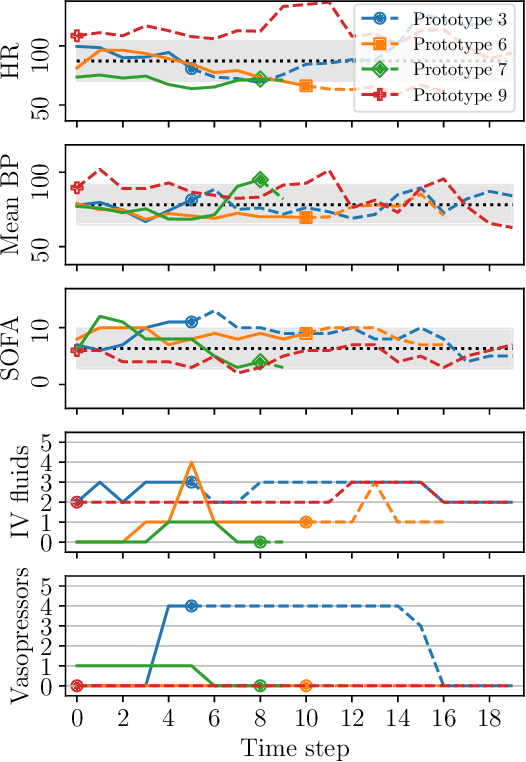
Importance sampling (IS) is often used to perform off-policy policy evaluation but is prone to several issues, especially when the behavior policy is unknown and must be estimated from data. Significant differences between the target and behavior policies can result in uncertain value estimates due to, for example, high variance and non-evaluated actions. If the behavior policy is estimated using black-box models, it can be hard to diagnose potential problems and to determine for which inputs the policies differ in their suggested actions and resulting values. To address this, we propose estimating the behavior policy for IS using prototype learning. We apply this approach in the evaluation of policies for sepsis treatment, demonstrating how the prototypes give a condensed summary of differences between the target and behavior policies while retaining an accuracy comparable to baseline estimators. We also describe estimated values in terms of the prototypes to better understand which parts of the target policies have the most impact on the estimates. Using a simulator, we study the bias resulting from restricting models to use prototypes.
ADCB: An Alzheimer's disease benchmark for evaluating observational estimators of causal effects
Nov 12, 2021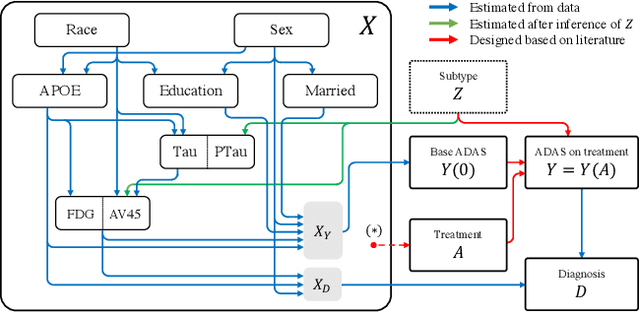
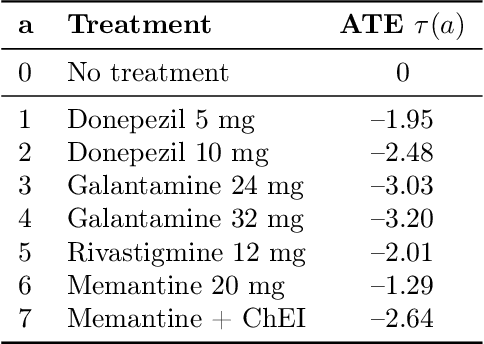
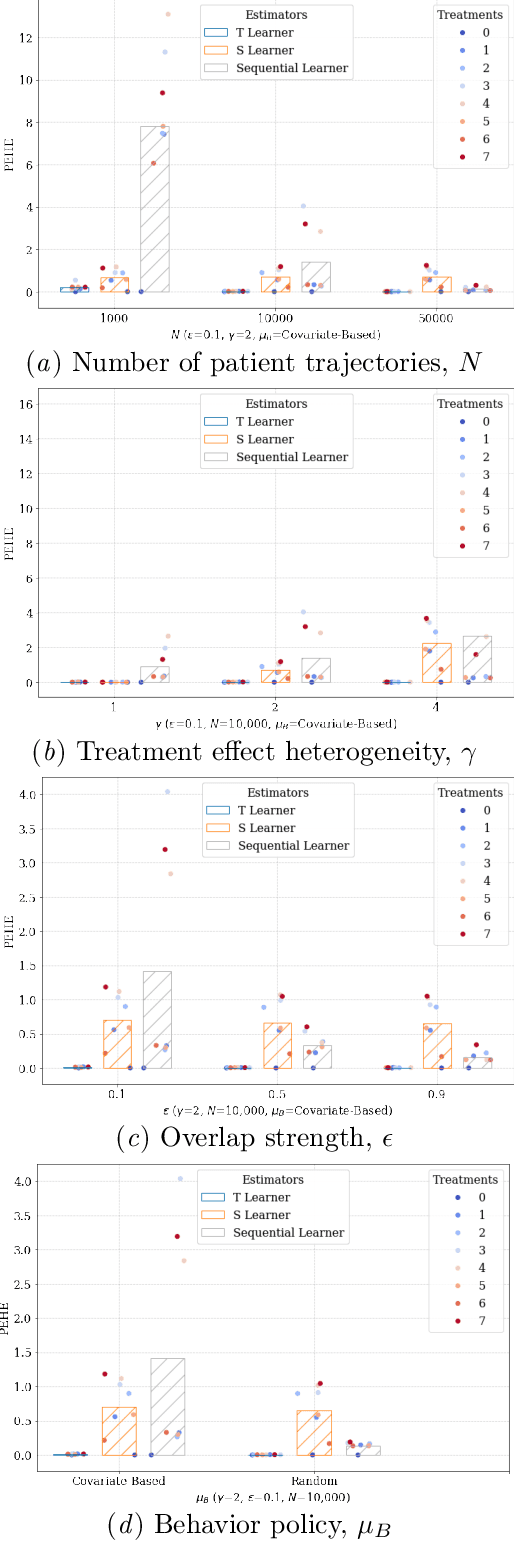
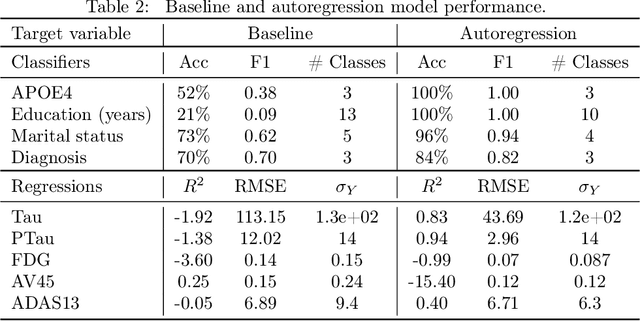
Simulators make unique benchmarks for causal effect estimation since they do not rely on unverifiable assumptions or the ability to intervene on real-world systems, but are often too simple to capture important aspects of real applications. We propose a simulator of Alzheimer's disease aimed at modeling intricacies of healthcare data while enabling benchmarking of causal effect and policy estimators. We fit the system to the Alzheimer's Disease Neuroimaging Initiative (ADNI) dataset and ground hand-crafted components in results from comparative treatment trials and observational treatment patterns. The simulator includes parameters which alter the nature and difficulty of the causal inference tasks, such as latent variables, effect heterogeneity, length of observed history, behavior policy and sample size. We use the simulator to compare estimators of average and conditional treatment effects.
Using Time-Series Privileged Information for Provably Efficient Learning of Prediction Models
Oct 28, 2021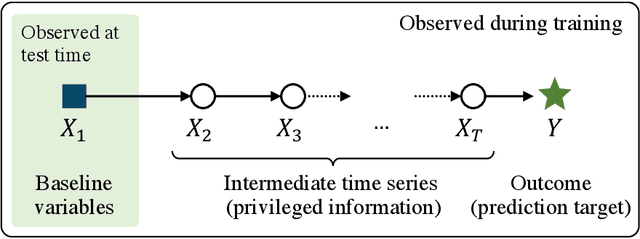
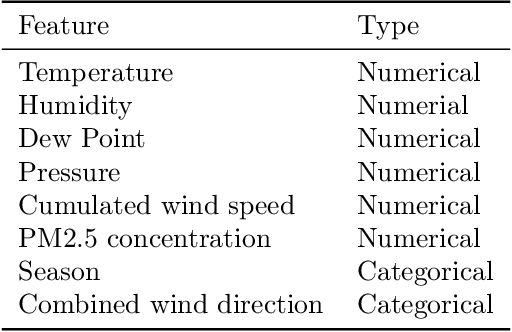
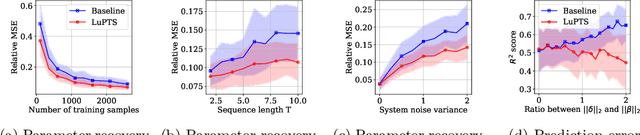
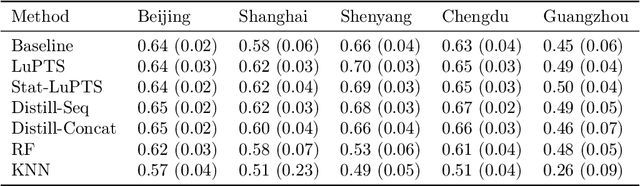
We study prediction of future outcomes with supervised models that use privileged information during learning. The privileged information comprises samples of time series observed between the baseline time of prediction and the future outcome; this information is only available at training time which differs from the traditional supervised learning. Our question is when using this privileged data leads to more sample-efficient learning of models that use only baseline data for predictions at test time. We give an algorithm for this setting and prove that when the time series are drawn from a non-stationary Gaussian-linear dynamical system of fixed horizon, learning with privileged information is more efficient than learning without it. On synthetic data, we test the limits of our algorithm and theory, both when our assumptions hold and when they are violated. On three diverse real-world datasets, we show that our approach is generally preferable to classical learning, particularly when data is scarce. Finally, we relate our estimator to a distillation approach both theoretically and empirically.
Thompson Sampling for Bandits with Clustered Arms
Sep 06, 2021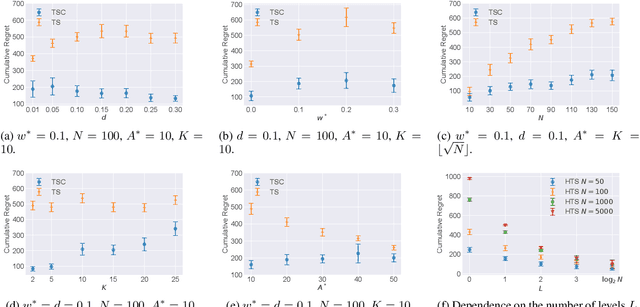
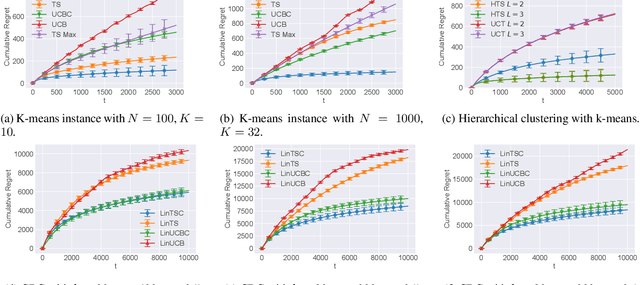
We propose algorithms based on a multi-level Thompson sampling scheme, for the stochastic multi-armed bandit and its contextual variant with linear expected rewards, in the setting where arms are clustered. We show, both theoretically and empirically, how exploiting a given cluster structure can significantly improve the regret and computational cost compared to using standard Thompson sampling. In the case of the stochastic multi-armed bandit we give upper bounds on the expected cumulative regret showing how it depends on the quality of the clustering. Finally, we perform an empirical evaluation showing that our algorithms perform well compared to previously proposed algorithms for bandits with clustered arms.
Learning Approximate and Exact Numeral Systems via Reinforcement Learning
May 28, 2021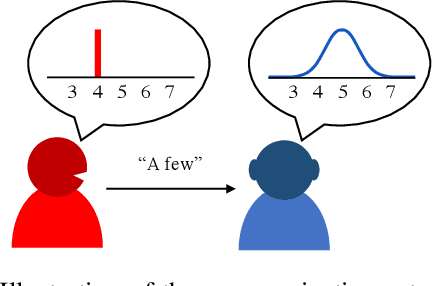

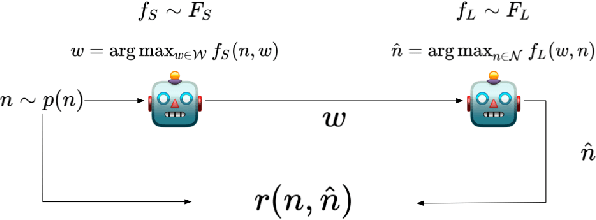
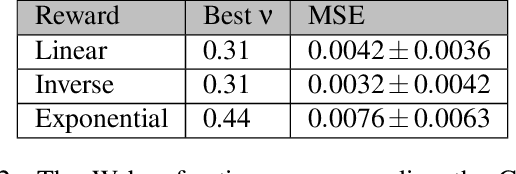
Recent work (Xu et al., 2020) has suggested that numeral systems in different languages are shaped by a functional need for efficient communication in an information-theoretic sense. Here we take a learning-theoretic approach and show how efficient communication emerges via reinforcement learning. In our framework, two artificial agents play a Lewis signaling game where the goal is to convey a numeral concept. The agents gradually learn to communicate using reinforcement learning and the resulting numeral systems are shown to be efficient in the information-theoretic framework of Regier et al. (2015); Gibson et al. (2017). They are also shown to be similar to human numeral systems of same type. Our results thus provide a mechanistic explanation via reinforcement learning of the recent results in Xu et al. (2020) and can potentially be generalized to other semantic domains.
Learning to search efficiently for causally near-optimal treatments
Jul 02, 2020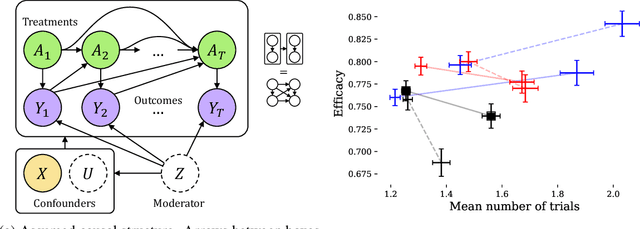
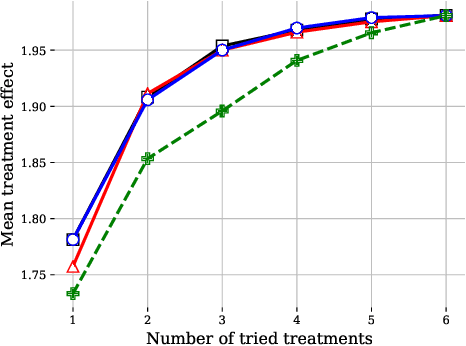
Finding an effective medical treatment often requires a search by trial and error. Making this search more efficient by minimizing the number of unnecessary trials could lower both costs and patient suffering. We formalize this problem as learning a policy for finding a near-optimal treatment in a minimum number of trials using a causal inference framework. We give a model-based dynamic programming algorithm which learns from observational data while being robust to unmeasured confounding. To reduce time complexity, we suggest a greedy algorithm which bounds the near-optimality constraint. The methods are evaluated on synthetic and real-world healthcare data and compared to model-free reinforcement learning. We find that our methods compare favorably to the model-free baseline while offering a more transparent trade-off between search time and treatment efficacy.