 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Debunking of Climate Misinformation
Jul 08, 2024



Misinformation about climate change causes numerous negative impacts, necessitating corrective responses. Psychological research has offered various strategies for reducing the influence of climate misinformation, such as the fact-myth-fallacy-fact-structure. However, practically implementing corrective interventions at scale represents a challenge. Automatic detection and correction of misinformation offers a solution to the misinformation problem. This study documents the development of large language models that accept as input a climate myth and produce a debunking that adheres to the fact-myth-fallacy-fact (``truth sandwich'') structure, by incorporating contrarian claim classification and fallacy detection into an LLM prompting framework. We combine open (Mixtral, Palm2) and proprietary (GPT-4) LLMs with prompting strategies of varying complexity. Experiments reveal promising performance of GPT-4 and Mixtral if combined with structured prompts. We identify specific challenges of debunking generation and human evaluation, and map out avenues for future work. We release a dataset of high-quality truth-sandwich debunkings, source code and a demo of the debunking system.
Detecting Fallacies in Climate Misinformation: A Technocognitive Approach to Identifying Misleading Argumentation
May 14, 2024Misinformation about climate change is a complex societal issue requiring holistic, interdisciplinary solutions at the intersection between technology and psychology. One proposed solution is a "technocognitive" approach, involving the synthesis of psychological and computer science research. Psychological research has identified that interventions in response to misinformation require both fact-based (e.g., factual explanations) and technique-based (e.g., explanations of misleading techniques) content. However, little progress has been made on documenting and detecting fallacies in climate misinformation. In this study, we apply a previously developed critical thinking methodology for deconstructing climate misinformation, in order to develop a dataset mapping different types of climate misinformation to reasoning fallacies. This dataset is used to train a model to detect fallacies in climate misinformation. Our study shows F1 scores that are 2.5 to 3.5 better than previous works. The fallacies that are easiest to detect include fake experts and anecdotal arguments, while fallacies that require background knowledge, such as oversimplification, misrepresentation, and slothful induction, are relatively more difficult to detect. This research lays the groundwork for development of solutions where automatically detected climate misinformation can be countered with generative technique-based corrections.
Socialz: Multi-Feature Social Fuzz Testing
Feb 17, 2023



Online social networks have become an integral aspect of our daily lives and play a crucial role in shaping our relationships with others. However, bugs and glitches, even minor ones, can cause anything from frustrating problems to serious data leaks that can have far-reaching impacts on millions of users. To mitigate these risks, fuzz testing, a method of testing with randomised inputs, can provide increased confidence in the correct functioning of a social network. However, implementing traditional fuzz testing methods can be prohibitively difficult or impractical for programmers outside of the network's development team. To tackle this challenge, we present Socialz, a novel approach to social fuzz testing that (1) characterises real users of a social network, (2) diversifies their interaction using evolutionary computation across multiple, non-trivial features, and (3) collects performance data as these interactions are executed. With Socialz, we aim to provide anyone with the capability to perform comprehensive social testing, thereby improving the reliability and security of online social networks used around the world.
Automatically Categorising GitHub Repositories by Application Domain
Jul 30, 2022

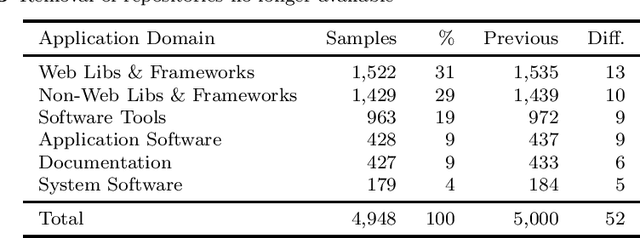
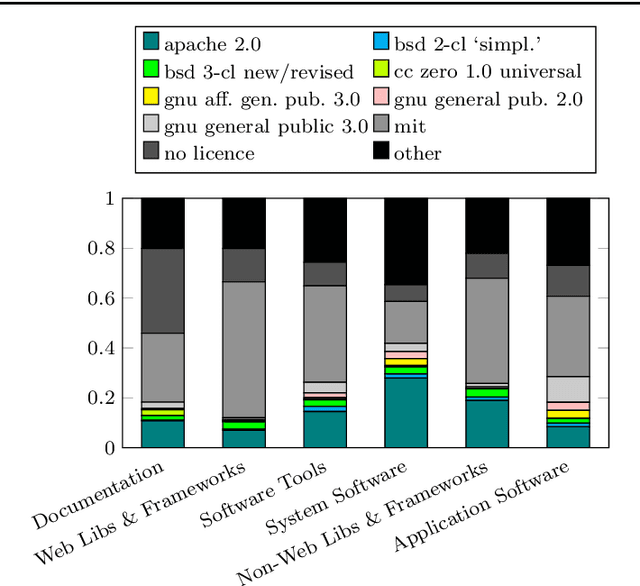
GitHub is the largest host of open source software on the Internet. This large, freely accessible database has attracted the attention of practitioners and researchers alike. But as GitHub's growth continues, it is becoming increasingly hard to navigate the plethora of repositories which span a wide range of domains. Past work has shown that taking the application domain into account is crucial for tasks such as predicting the popularity of a repository and reasoning about project quality. In this work, we build on a previously annotated dataset of 5,000 GitHub repositories to design an automated classifier for categorising repositories by their application domain. The classifier uses state-of-the-art natural language processing techniques and machine learning to learn from multiple data sources and catalogue repositories according to five application domains. We contribute with (1) an automated classifier that can assign popular repositories to each application domain with at least 70% precision, (2) an investigation of the approach's performance on less popular repositories, and (3) a practical application of this approach to answer how the adoption of software engineering practices differs across application domains. Our work aims to help the GitHub community identify repositories of interest and opens promising avenues for future work investigating differences between repositories from different application domains.