 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMULTICAST: MULTI Confirmation-level Alarm SysTem based on CNN and LSTM to mitigate false alarms for handgun detection in video-surveillance
May 03, 2021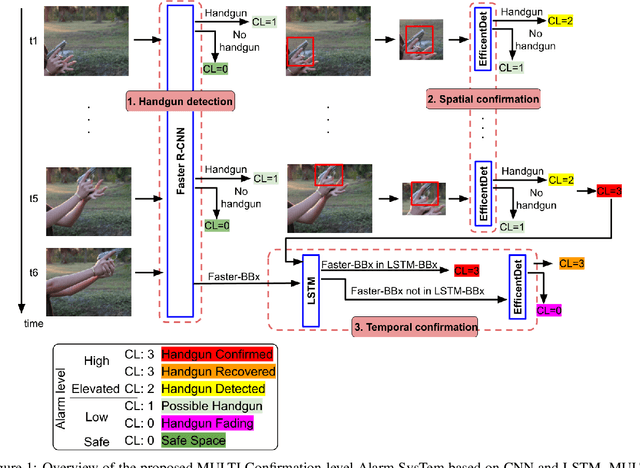
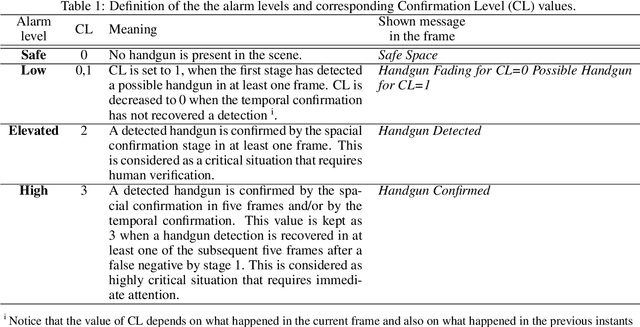
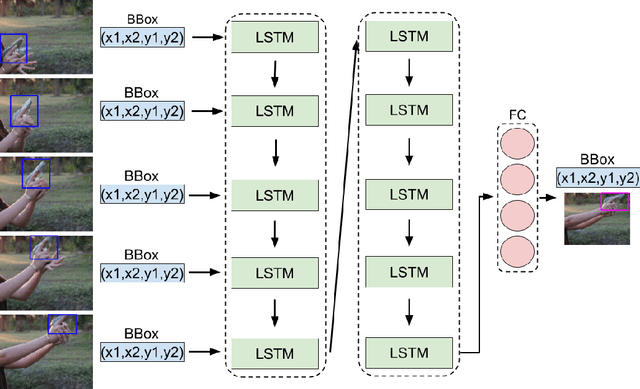
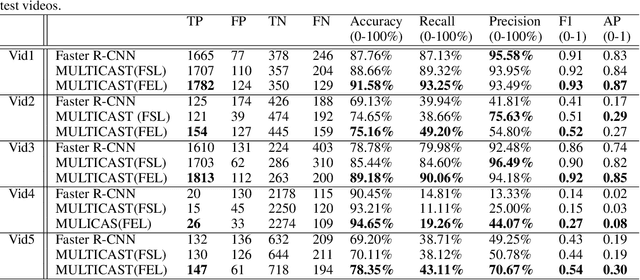
Despite the constant advances in computer vision, integrating modern single-image detectors in real-time handgun alarm systems in video-surveillance is still debatable. Using such detectors still implies a high number of false alarms and false negatives. In this context, most existent studies select one of the latest single-image detectors and train it on a better dataset or use some pre-processing, post-processing or data-fusion approach to further reduce false alarms. However, none of these works tried to exploit the temporal information present in the videos to mitigate false detections. This paper presents a new system, called MULTI Confirmation-level Alarm SysTem based on Convolutional Neural Networks (CNN) and Long Short Term Memory networks (LSTM) (MULTICAST), that leverages not only the spacial information but also the temporal information existent in the videos for a more reliable handgun detection. MULTICAST consists of three stages, i) a handgun detection stage, ii) a CNN-based spacial confirmation stage and iii) LSTM-based temporal confirmation stage. The temporal confirmation stage uses the positions of the detected handgun in previous instants to predict its trajectory in the next frame. Our experiments show that MULTICAST reduces by 80% the number of false alarms with respect to Faster R-CNN based-single-image detector, which makes it more useful in providing more effective and rapid security responses.
EXplainable Neural-Symbolic Learning (X-NeSyL) methodology to fuse deep learning representations with expert knowledge graphs: the MonuMAI cultural heritage use case
Apr 24, 2021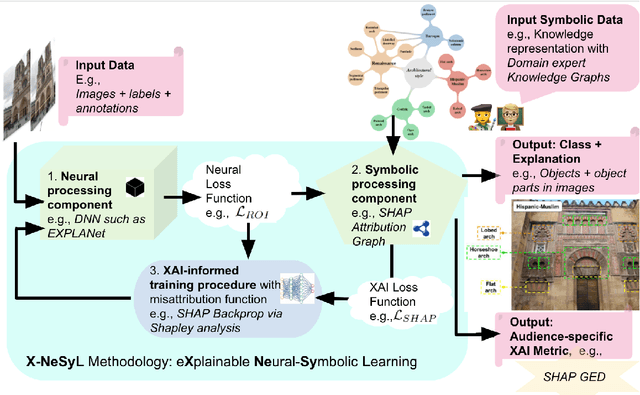
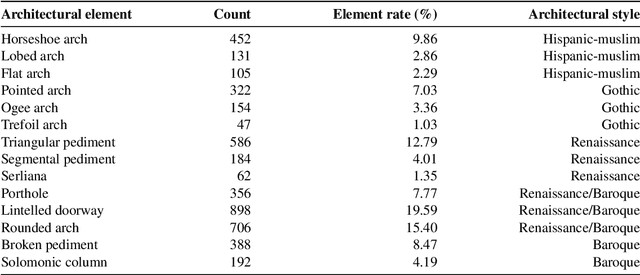


The latest Deep Learning (DL) models for detection and classification have achieved an unprecedented performance over classical machine learning algorithms. However, DL models are black-box methods hard to debug, interpret, and certify. DL alone cannot provide explanations that can be validated by a non technical audience. In contrast, symbolic AI systems that convert concepts into rules or symbols -- such as knowledge graphs -- are easier to explain. However, they present lower generalisation and scaling capabilities. A very important challenge is to fuse DL representations with expert knowledge. One way to address this challenge, as well as the performance-explainability trade-off is by leveraging the best of both streams without obviating domain expert knowledge. We tackle such problem by considering the symbolic knowledge is expressed in form of a domain expert knowledge graph. We present the eXplainable Neural-symbolic learning (X-NeSyL) methodology, designed to learn both symbolic and deep representations, together with an explainability metric to assess the level of alignment of machine and human expert explanations. The ultimate objective is to fuse DL representations with expert domain knowledge during the learning process to serve as a sound basis for explainability. X-NeSyL methodology involves the concrete use of two notions of explanation at inference and training time respectively: 1) EXPLANet: Expert-aligned eXplainable Part-based cLAssifier NETwork Architecture, a compositional CNN that makes use of symbolic representations, and 2) SHAP-Backprop, an explainable AI-informed training procedure that guides the DL process to align with such symbolic representations in form of knowledge graphs. We showcase X-NeSyL methodology using MonuMAI dataset for monument facade image classification, and demonstrate that our approach improves explainability and performance.
AT-MFCGA: An Adaptive Transfer-guided Multifactorial Cellular Genetic Algorithm for Evolutionary Multitasking
Oct 08, 2020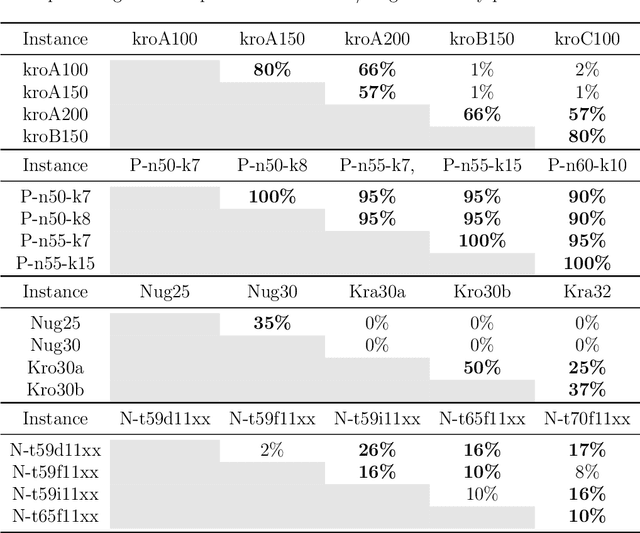
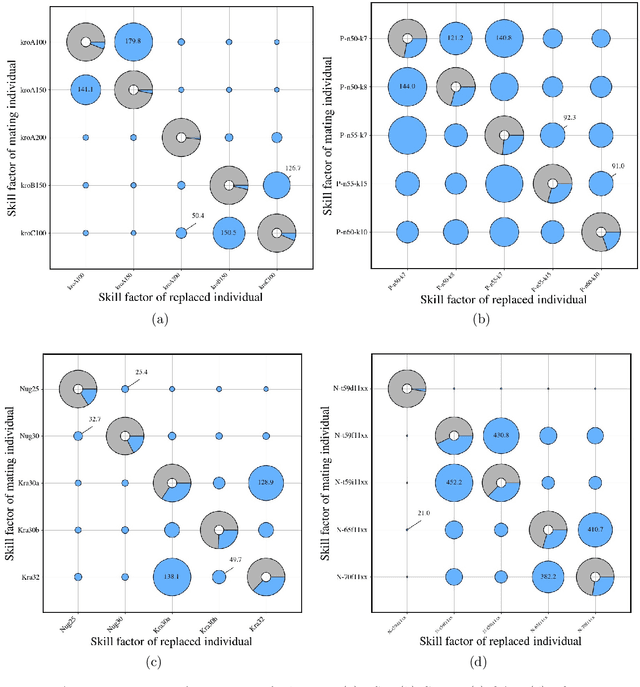

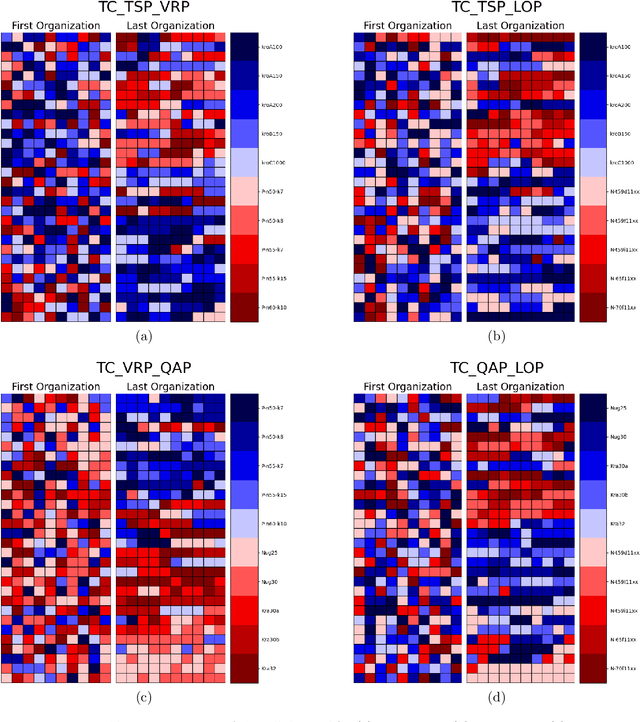
Transfer Optimization is an incipient research area dedicated to the simultaneous solving of multiple optimization tasks. Among the different approaches that can address this problem effectively, Evolutionary Multitasking resorts to concepts from Evolutionary Computation to solve multiple problems within a single search process. In this paper we introduce a novel adaptive metaheuristic algorithm for dealing with Evolutionary Multitasking environments coined as Adaptive Transfer-guided Multifactorial Cellular Genetic Algorithm (AT-MFCGA). AT-MFCGA relies on cellular automata to implement mechanisms for exchanging knowledge among the optimization problems under consideration. Furthermore, our approach is able to explain by itself the synergies among tasks that were encountered and exploited during the search, which helps understand interactions between related optimization tasks. A comprehensive experimental setup is designed for assessing and comparing the performance of AT-MFCGA to that of other renowned evolutionary multitasking alternatives (MFEA and MFEA-II). Experiments comprise 11 multitasking scenarios composed by 20 instances of 4 combinatorial optimization problems, yielding the largest discrete multitasking environment solved to date. Results are conclusive in regards to the superior quality of solutions provided by AT-MFCGA with respect to the rest of methods, which are complemented by a quantitative examination of the genetic transferability among tasks along the search process.
CURIE: A Cellular Automaton for Concept Drift Detection
Sep 21, 2020
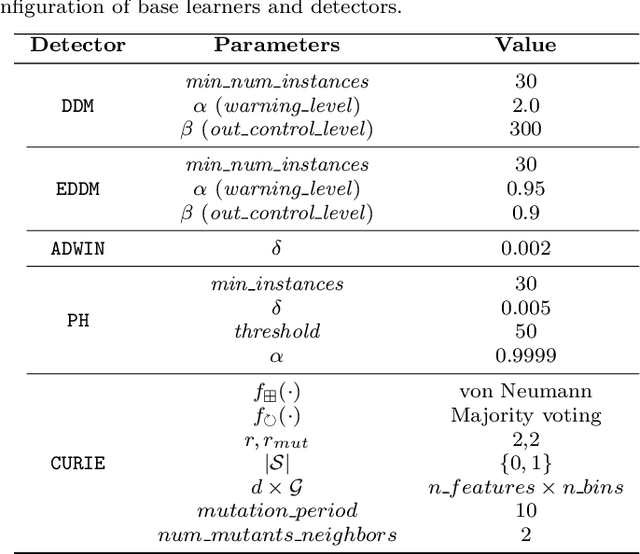
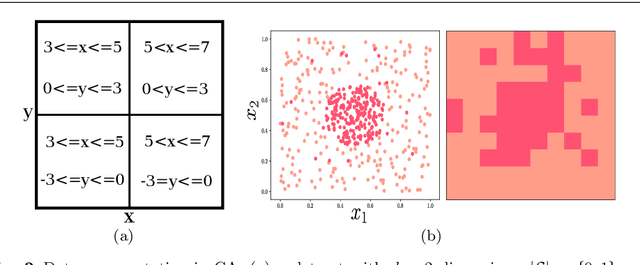
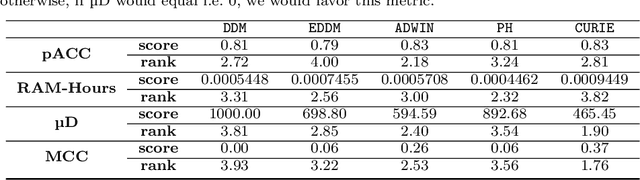
Data stream mining extracts information from large quantities of data flowing fast and continuously (data streams). They are usually affected by changes in the data distribution, giving rise to a phenomenon referred to as concept drift. Thus, learning models must detect and adapt to such changes, so as to exhibit a good predictive performance after a drift has occurred. In this regard, the development of effective drift detection algorithms becomes a key factor in data stream mining. In this work we propose CU RIE, a drift detector relying on cellular automata. Specifically, in CU RIE the distribution of the data stream is represented in the grid of a cellular automata, whose neighborhood rule can then be utilized to detect possible distribution changes over the stream. Computer simulations are presented and discussed to show that CU RIE, when hybridized with other base learners, renders a competitive behavior in terms of detection metrics and classification accuracy. CU RIE is compared with well-established drift detectors over synthetic datasets with varying drift characteristics.
Lights and Shadows in Evolutionary Deep Learning: Taxonomy, Critical Methodological Analysis, Cases of Study, Learned Lessons, Recommendations and Challenges
Aug 09, 2020
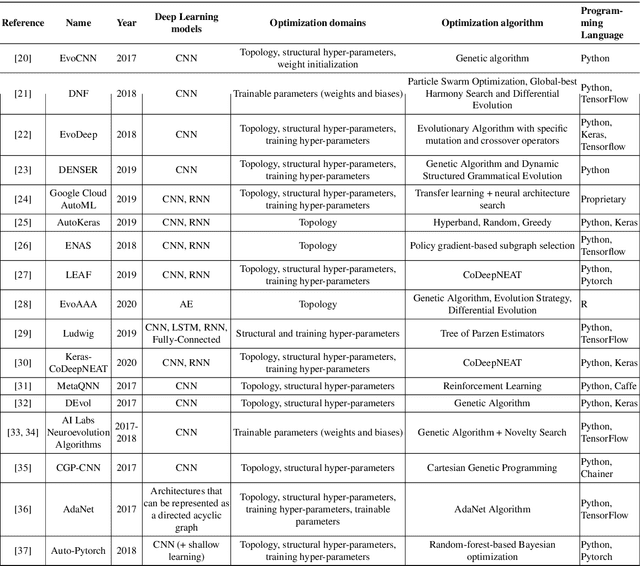
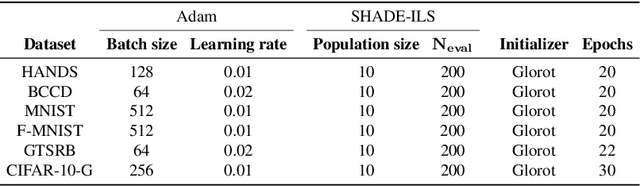
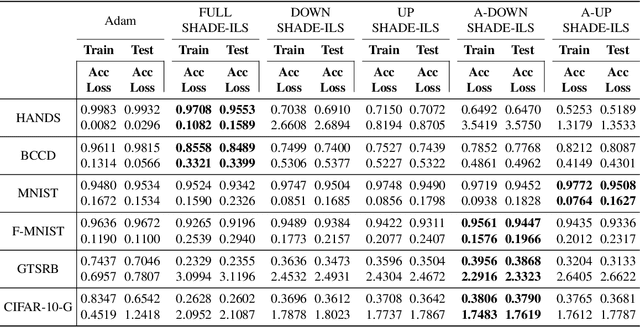
Much has been said about the fusion of bio-inspired optimization algorithms and Deep Learning models for several purposes: from the discovery of network topologies and hyper-parametric configurations with improved performance for a given task, to the optimization of the model's parameters as a replacement for gradient-based solvers. Indeed, the literature is rich in proposals showcasing the application of assorted nature-inspired approaches for these tasks. In this work we comprehensively review and critically examine contributions made so far based on three axes, each addressing a fundamental question in this research avenue: a) optimization and taxonomy (Why?), including a historical perspective, definitions of optimization problems in Deep Learning, and a taxonomy associated with an in-depth analysis of the literature, b) critical methodological analysis (How?), which together with two case studies, allows us to address learned lessons and recommendations for good practices following the analysis of the literature, and c) challenges and new directions of research (What can be done, and what for?). In summary, three axes - optimization and taxonomy, critical analysis, and challenges - which outline a complete vision of a merger of two technologies drawing up an exciting future for this area of fusion research.
Distributed Linguistic Representations in Decision Making: Taxonomy, Key Elements and Applications, and Challenges in Data Science and Explainable Artificial Intelligence
Aug 07, 2020
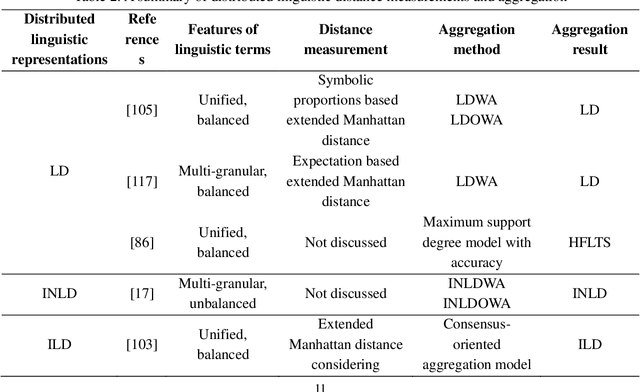
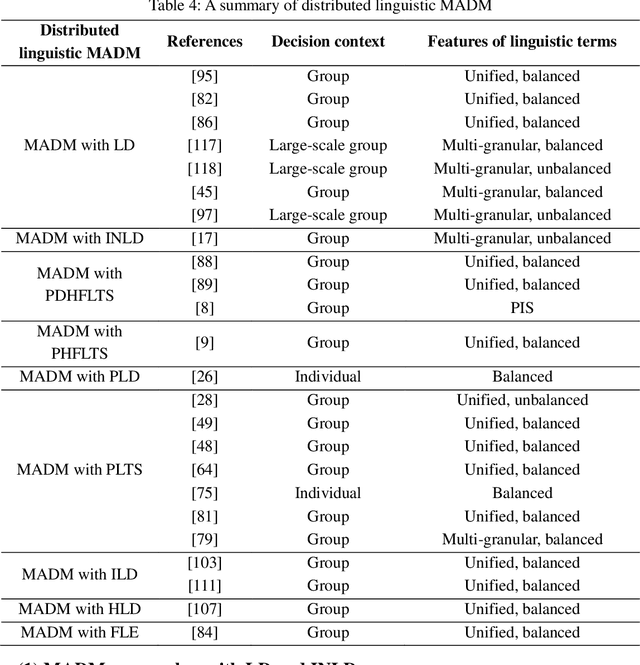
Distributed linguistic representations are powerful tools for modelling the uncertainty and complexity of preference information in linguistic decision making. To provide a comprehensive perspective on the development of distributed linguistic representations in decision making, we present the taxonomy of existing distributed linguistic representations. Then, we review the key elements of distributed linguistic information processing in decision making, including the distance measurement, aggregation methods, distributed linguistic preference relations, and distributed linguistic multiple attribute decision making models. Next, we provide a discussion on ongoing challenges and future research directions from the perspective of data science and explainable artificial intelligence.
Sentiment Analysis based Multi-person Multi-criteria Decision Making Methodology: Using Natural Language Processing and Deep Learning for Decision Aid
Jul 31, 2020
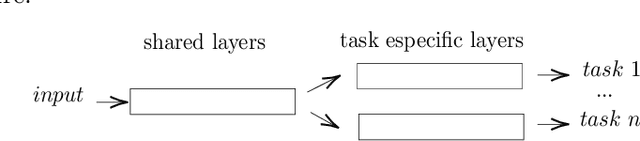

Decision making models are constrained by taking the expert evaluations with pre-defined numerical or linguistic terms. We claim that the use of sentiment analysis will allow decision making models to consider expert evaluations in natural language. Accordingly, we propose the Sentiment Analysis based Multi-person Multi-criteria Decision Making (SA-MpMcDM) methodology, which builds the expert evaluations from their natural language reviews, and even from their numerical ratings if they are available. The SA-MpMcDM methodology incorporates an end-to-end multi-task deep learning model for aspect based sentiment analysis, named DMuABSA model, able to identify the aspect categories mentioned in an expert review, and to distill their opinions and criteria. The individual expert evaluations are aggregated via a criteria weighting through the attention of the experts. We evaluate the methodology in a restaurant decision problem, hence we build the TripR-2020 dataset of restaurant reviews, which we manually annotate and release. We analyze the SA-MpMcDM methodology in different scenarios using and not using natural language and numerical evaluations. The analysis shows that the combination of both sources of information results in a higher quality preference vector.
Dynamic Federated Learning Model for Identifying Adversarial Clients
Jul 29, 2020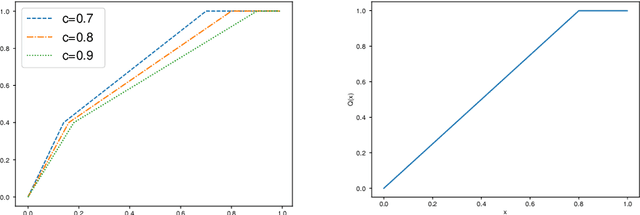
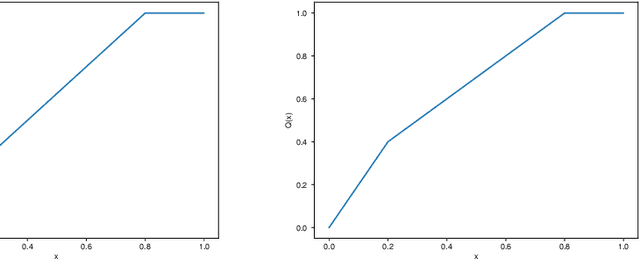
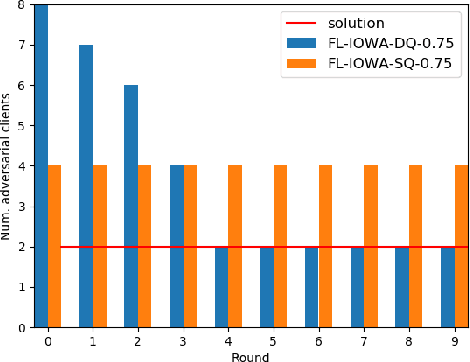
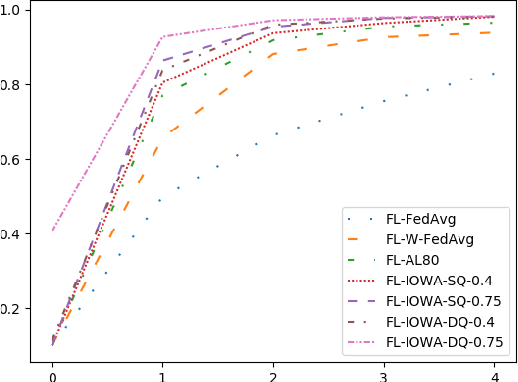
Federated learning, as a distributed learning that conducts the training on the local devices without accessing to the training data, is vulnerable to dirty-label data poisoning adversarial attacks. We claim that the federated learning model has to avoid those kind of adversarial attacks through filtering out the clients that manipulate the local data. We propose a dynamic federated learning model that dynamically discards those adversarial clients, which allows to prevent the corruption of the global learning model. We evaluate the dynamic discarding of adversarial clients deploying a deep learning classification model in a federated learning setting, and using the EMNIST Digits and Fashion MNIST image classification datasets. Likewise, we analyse the capacity of detecting clients with poor data distribution and reducing the number of rounds of learning by selecting the clients to aggregate. The results show that the dynamic selection of the clients to aggregate enhances the performance of the global learning model, discards the adversarial and poor clients and reduces the rounds of learning.
Revisiting Data Complexity Metrics Based on Morphology for Overlap and Imbalance: Snapshot, New Overlap Number of Balls Metrics and Singular Problems Prospect
Jul 15, 2020
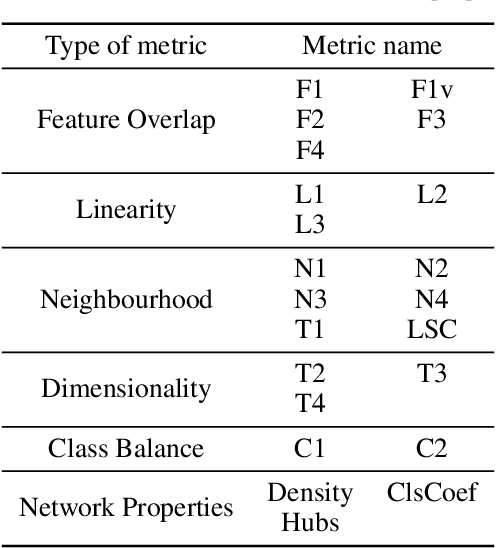
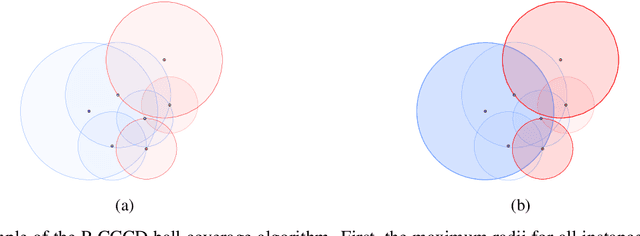
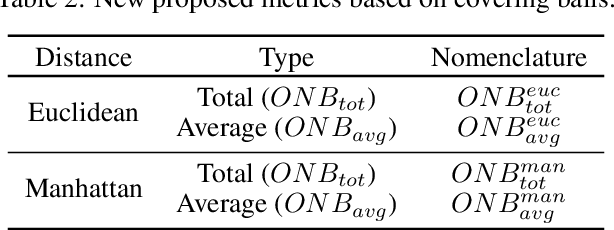
Data Science and Machine Learning have become fundamental assets for companies and research institutions alike. As one of its fields, supervised classification allows for class prediction of new samples, learning from given training data. However, some properties can cause datasets to be problematic to classify. In order to evaluate a dataset a priori, data complexity metrics have been used extensively. They provide information regarding different intrinsic characteristics of the data, which serve to evaluate classifier compatibility and a course of action that improves performance. However, most complexity metrics focus on just one characteristic of the data, which can be insufficient to properly evaluate the dataset towards the classifiers' performance. In fact, class overlap, a very detrimental feature for the classification process (especially when imbalance among class labels is also present) is hard to assess. This research work focuses on revisiting complexity metrics based on data morphology. In accordance to their nature, the premise is that they provide both good estimates for class overlap, and great correlations with the classification performance. For that purpose, a novel family of metrics have been developed. Being based on ball coverage by classes, they are named after Overlap Number of Balls. Finally, some prospects for the adaptation of the former family of metrics to singular (more complex) problems are discussed.
Federated Learning and Differential Privacy: Software tools analysis, the Sherpa.ai FL framework and methodological guidelines for preserving data privacy
Jul 02, 2020The high demand of artificial intelligence services at the edges that also preserve data privacy has pushed the research on novel machine learning paradigms that fit those requirements. Federated learning has the ambition to protect data privacy through distributed learning methods that keep the data in their data silos. Likewise, differential privacy attains to improve the protection of data privacy by measuring the privacy loss in the communication among the elements of federated learning. The prospective matching of federated learning and differential privacy to the challenges of data privacy protection has caused the release of several software tools that support their functionalities, but they lack of the needed unified vision for those techniques, and a methodological workflow that support their use. Hence, we present the Sherpa.ai Federated Learning framework that is built upon an holistic view of federated learning and differential privacy. It results from the study of how to adapt the machine learning paradigm to federated learning, and the definition of methodological guidelines for developing artificial intelligence services based on federated learning and differential privacy. We show how to follow the methodological guidelines with the Sherpa.ai Federated Learning framework by means of a classification and a regression use cases.