 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMobile Keyboard Input Decoding with Finite-State Transducers
Apr 13, 2017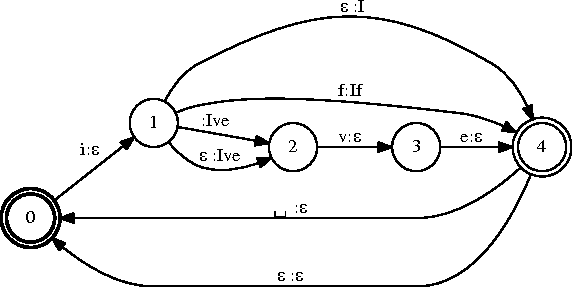
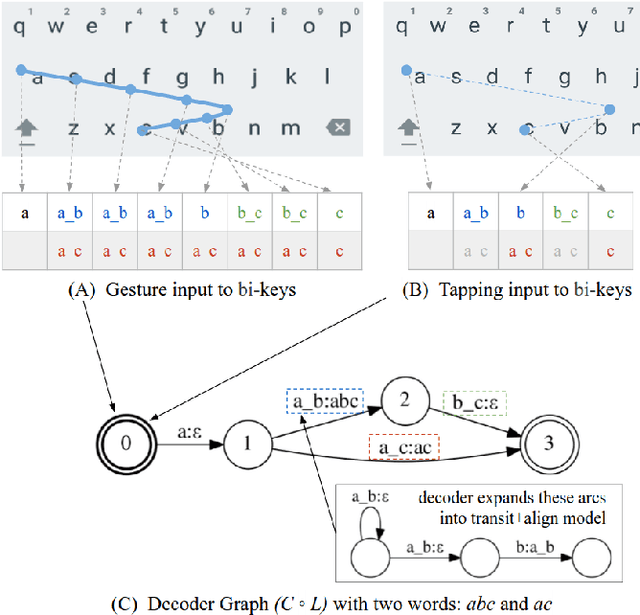
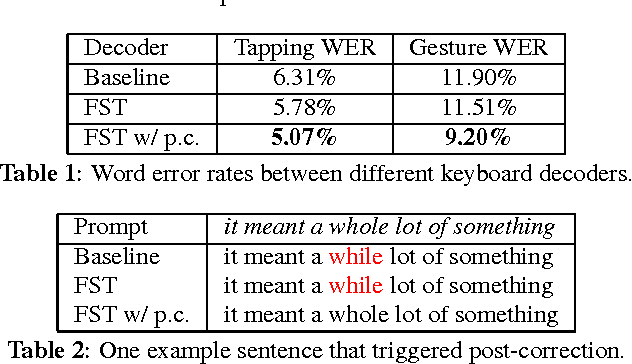
We propose a finite-state transducer (FST) representation for the models used to decode keyboard inputs on mobile devices. Drawing from learnings from the field of speech recognition, we describe a decoding framework that can satisfy the strict memory and latency constraints of keyboard input. We extend this framework to support functionalities typically not present in speech recognition, such as literal decoding, autocorrections, word completions, and next word predictions. We describe the general framework of what we call for short the keyboard "FST decoder" as well as the implementation details that are new compared to a speech FST decoder. We demonstrate that the FST decoder enables new UX features such as post-corrections. Finally, we sketch how this decoder can support advanced features such as personalization and contextualization.
Fast and Accurate Recurrent Neural Network Acoustic Models for Speech Recognition
Jul 24, 2015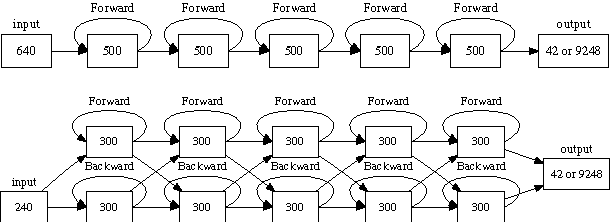
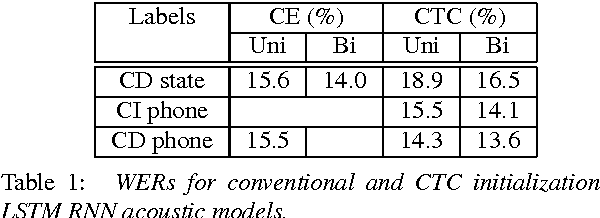
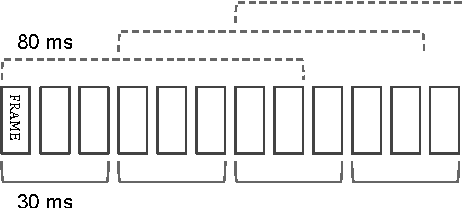
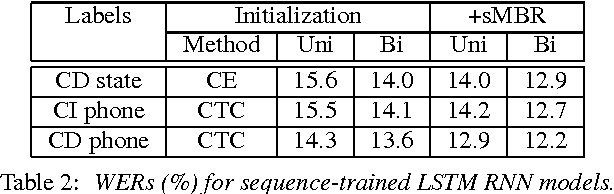
We have recently shown that deep Long Short-Term Memory (LSTM) recurrent neural networks (RNNs) outperform feed forward deep neural networks (DNNs) as acoustic models for speech recognition. More recently, we have shown that the performance of sequence trained context dependent (CD) hidden Markov model (HMM) acoustic models using such LSTM RNNs can be equaled by sequence trained phone models initialized with connectionist temporal classification (CTC). In this paper, we present techniques that further improve performance of LSTM RNN acoustic models for large vocabulary speech recognition. We show that frame stacking and reduced frame rate lead to more accurate models and faster decoding. CD phone modeling leads to further improvements. We also present initial results for LSTM RNN models outputting words directly.
Long Short-Term Memory Based Recurrent Neural Network Architectures for Large Vocabulary Speech Recognition
Feb 05, 2014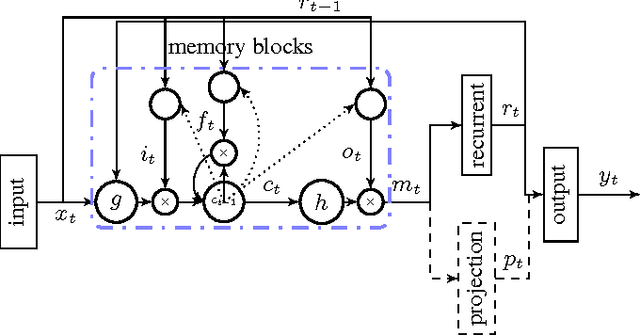
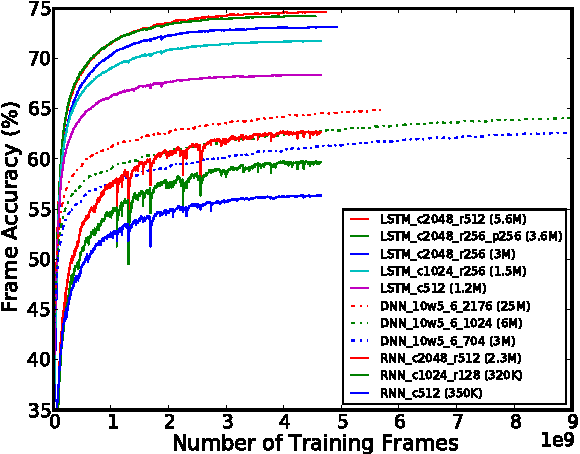
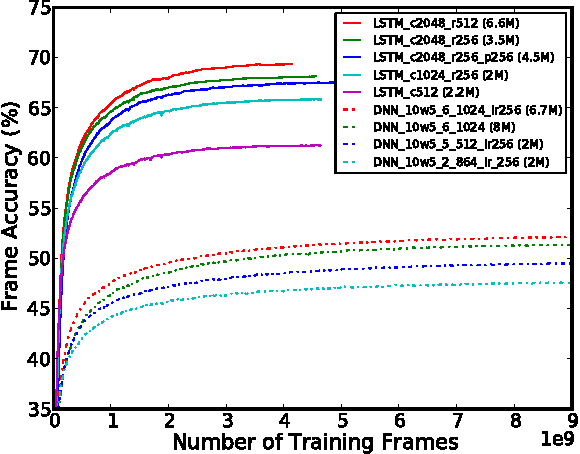
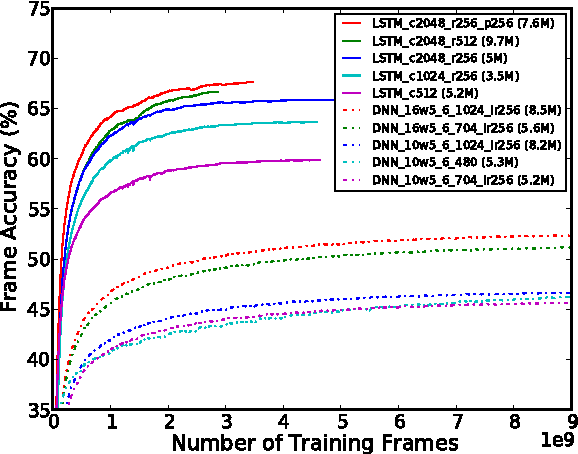
Long Short-Term Memory (LSTM) is a recurrent neural network (RNN) architecture that has been designed to address the vanishing and exploding gradient problems of conventional RNNs. Unlike feedforward neural networks, RNNs have cyclic connections making them powerful for modeling sequences. They have been successfully used for sequence labeling and sequence prediction tasks, such as handwriting recognition, language modeling, phonetic labeling of acoustic frames. However, in contrast to the deep neural networks, the use of RNNs in speech recognition has been limited to phone recognition in small scale tasks. In this paper, we present novel LSTM based RNN architectures which make more effective use of model parameters to train acoustic models for large vocabulary speech recognition. We train and compare LSTM, RNN and DNN models at various numbers of parameters and configurations. We show that LSTM models converge quickly and give state of the art speech recognition performance for relatively small sized models.