 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnticipating Object State Changes
May 21, 2024Anticipating object state changes in images and videos is a challenging problem whose solution has important implications in vision-based scene understanding, automated monitoring systems, and action planning. In this work, we propose the first method for solving this problem. The proposed method predicts object state changes that will occur in the near future as a result of yet unseen human actions. To address this new problem, we propose a novel framework that integrates learnt visual features that represent the recent visual information, with natural language (NLP) features that represent past object state changes and actions. Leveraging the extensive and challenging Ego4D dataset which provides a large-scale collection of first-person perspective videos across numerous interaction scenarios, we introduce new curated annotation data for the object state change anticipation task (OSCA), noted as Ego4D-OSCA. An extensive experimental evaluation was conducted that demonstrates the efficacy of the proposed method in predicting object state changes in dynamic scenarios. The proposed work underscores the potential of integrating video and linguistic cues to enhance the predictive performance of video understanding systems. Moreover, it lays the groundwork for future research on the new task of object state change anticipation. The source code and the new annotation data (Ego4D-OSCA) will be made publicly available.
Fusing Domain-Specific Content from Large Language Models into Knowledge Graphs for Enhanced Zero Shot Object State Classification
Mar 25, 2024



Domain-specific knowledge can significantly contribute to addressing a wide variety of vision tasks. However, the generation of such knowledge entails considerable human labor and time costs. This study investigates the potential of Large Language Models (LLMs) in generating and providing domain-specific information through semantic embeddings. To achieve this, an LLM is integrated into a pipeline that utilizes Knowledge Graphs and pre-trained semantic vectors in the context of the Vision-based Zero-shot Object State Classification task. We thoroughly examine the behavior of the LLM through an extensive ablation study. Our findings reveal that the integration of LLM-based embeddings, in combination with general-purpose pre-trained embeddings, leads to substantial performance improvements. Drawing insights from this ablation study, we conduct a comparative analysis against competing models, thereby highlighting the state-of-the-art performance achieved by the proposed approach.
Detecting Object States vs Detecting Objects: A New Dataset and a Quantitative Experimental Study
Dec 15, 2021
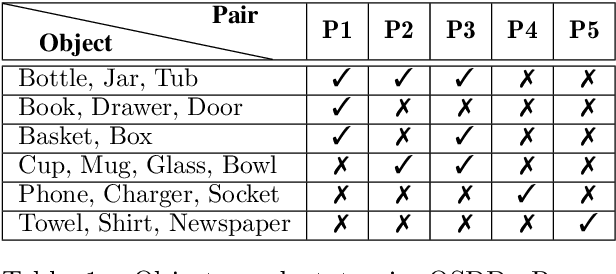

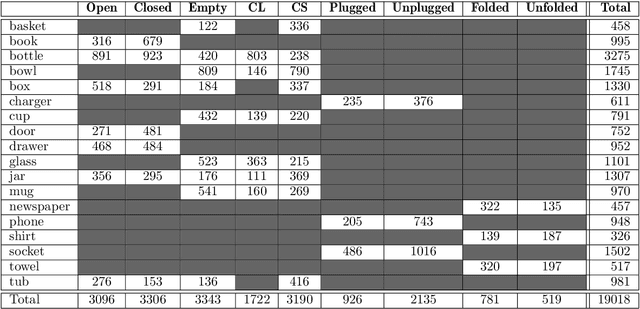
The detection of object states in images (State Detection - SD) is a problem of both theoretical and practical importance and it is tightly interwoven with other important computer vision problems, such as action recognition and affordance detection. It is also highly relevant to any entity that needs to reason and act in dynamic domains, such as robotic systems and intelligent agents. Despite its importance, up to now, the research on this problem has been limited. In this paper, we attempt a systematic study of the SD problem. First, we introduce the Object State Detection Dataset (OSDD), a new publicly available dataset consisting of more than 19,000 annotations for 18 object categories and 9 state classes. Second, using a standard deep learning framework used for Object Detection (OD), we conduct a number of appropriately designed experiments, towards an in-depth study of the behavior of the SD problem. This study enables the setup of a baseline on the performance of SD, as well as its relative performance in comparison to OD, in a variety of scenarios. Overall, the experimental outcomes confirm that SD is harder than OD and that tailored SD methods need to be developed for addressing effectively this significant problem.
A Review on Intelligent Object Perception Methods Combining Knowledge-based Reasoning and Machine Learning
Dec 26, 2019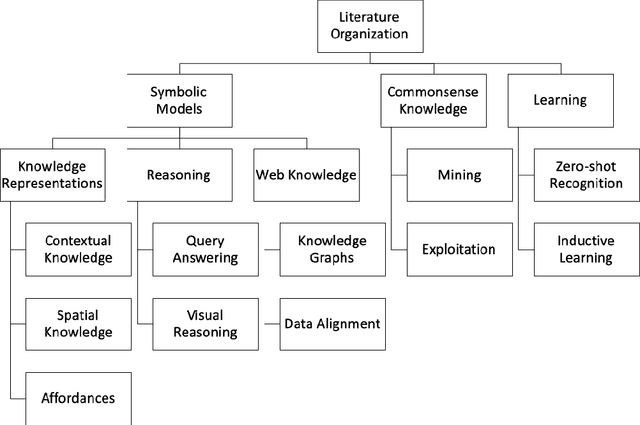
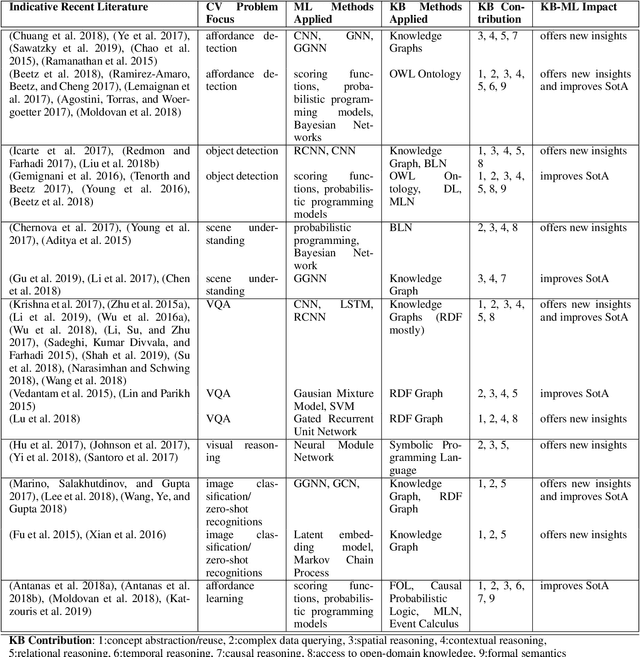
Object perception is a fundamental sub-field of Computer Vision, covering a multitude of individual areas and having contributed high-impact results. While Machine Learning has been traditionally applied to address related problems, recent works also seek ways to integrate knowledge engineering in order to expand the level of intelligence of the visual interpretation of objects, their properties and their relations with their environment. In this paper, we attempt a systematic investigation of how knowledge-based methods contribute to diverse object perception tasks. We review the latest achievements and identify prominent research directions.
Accurate Hand Keypoint Localization on Mobile Devices
Dec 19, 2018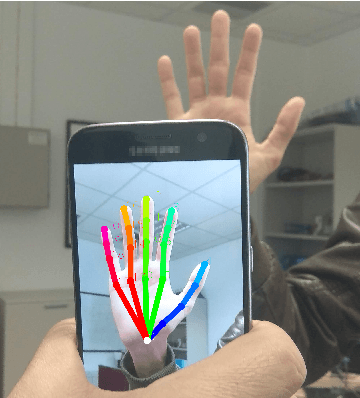
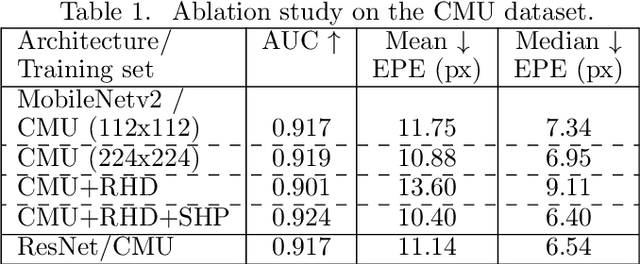
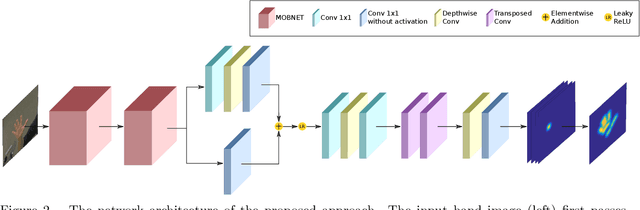

We present a novel approach for 2D hand keypoint localization from regular color input. The proposed approach relies on an appropriately designed Convolutional Neural Network (CNN) that computes a set of heatmaps, one per hand keypoint of interest. Extensive experiments with the proposed method compare it against state of the art approaches and demonstrate its accuracy and computational performance on standard, publicly available datasets. The obtained results demonstrate that the proposed method matches or outperforms the competing methods in accuracy, but clearly outperforms them in computational efficiency, making it a suitable building block for applications that require hand keypoint estimation on mobile devices.