 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModelling the Diachronic Emergence of Phoneme Frequency Distributions
Mar 10, 2026Phoneme frequency distributions exhibit robust statistical regularities across languages, including exponential-tailed rank-frequency patterns and a negative relationship between phonemic inventory size and the relative entropy of the distribution. The origin of these patterns remains largely unexplained. In this paper, we investigate whether they can arise as consequences of the historical processes that shape phonological systems. We introduce a stochastic model of phonological change and simulate the diachronic evolution of phoneme inventories. A naïve version of the model reproduces the general shape of phoneme rank-frequency distributions but fails to capture other empirical properties. Extending the model with two additional assumptions -- an effect related to functional load and a stabilising tendency toward a preferred inventory size -- yields simulations that match both the observed distributions and the negative relationship between inventory size and relative entropy. These results suggest that some statistical regularities of phonological systems may arise as natural consequences of diachronic sound change rather than from explicit optimisation or compensatory mechanisms.
The Distribution of Phoneme Frequencies across the World's Languages: Macroscopic and Microscopic Information-Theoretic Models
Mar 03, 2026We demonstrate that the frequency distribution of phonemes across languages can be explained at both macroscopic and microscopic levels. Macroscopically, phoneme rank-frequency distributions closely follow the order statistics of a symmetric Dirichlet distribution whose single concentration parameter scales systematically with phonemic inventory size, revealing a robust compensation effect whereby larger inventories exhibit lower relative entropy. Microscopically, a Maximum Entropy model incorporating constraints from articulatory, phonotactic, and lexical structure accurately predicts language-specific phoneme probabilities. Together, these findings provide a unified information-theoretic account of phoneme frequency structure.
Universal Topological Regularities of Syntactic Structures: Decoupling Efficiency from Optimization
Jan 31, 2023Human syntactic structures are usually represented as graphs. Much research has focused on the mapping between such graphs and linguistic sequences, but less attention has been paid to the shapes of the graphs themselves: their topologies. This study investigates how the topologies of syntactic graphs reveal traces of the processes that led to their emergence. I report a new universal regularity in syntactic structures: Their topology is communicatively efficient above chance. The pattern holds, without exception, for all 124 languages studied, across linguistic families and modalities (spoken, written, and signed). This pattern can arise from a process optimizing for communicative efficiency or, alternatively, by construction, as a by-effect of a sublinear preferential attachment process reflecting language production mechanisms known from psycholinguistics. This dual explanation shows how communicative efficiency, per se, does not require optimization. Among the two options, efficiency without optimization offers the better explanation for the new pattern.
Constant conditional entropy and related hypotheses
May 23, 2013Constant entropy rate (conditional entropies must remain constant as the sequence length increases) and uniform information density (conditional probabilities must remain constant as the sequence length increases) are two information theoretic principles that are argued to underlie a wide range of linguistic phenomena. Here we revise the predictions of these principles to the light of Hilberg's law on the scaling of conditional entropy in language and related laws. We show that constant entropy rate (CER) and two interpretations for uniform information density (UID), full UID and strong UID, are inconsistent with these laws. Strong UID implies CER but the reverse is not true. Full UID, a particular case of UID, leads to costly uncorrelated sequences that are totally unrealistic. We conclude that CER and its particular cases are incomplete hypotheses about the scaling of conditional entropies.
* introduction improved; typos corrected
Information content versus word length in random typing
Sep 08, 2012
Recently, it has been claimed that a linear relationship between a measure of information content and word length is expected from word length optimization and it has been shown that this linearity is supported by a strong correlation between information content and word length in many languages (Piantadosi et al. 2011, PNAS 108, 3825-3826). Here, we study in detail some connections between this measure and standard information theory. The relationship between the measure and word length is studied for the popular random typing process where a text is constructed by pressing keys at random from a keyboard containing letters and a space behaving as a word delimiter. Although this random process does not optimize word lengths according to information content, it exhibits a linear relationship between information content and word length. The exact slope and intercept are presented for three major variants of the random typing process. A strong correlation between information content and word length can simply arise from the units making a word (e.g., letters) and not necessarily from the interplay between a word and its context as proposed by Piantadosi et al. In itself, the linear relation does not entail the results of any optimization process.
Analytical Determination of Fractal Structure in Stochastic Time Series
Nov 12, 2009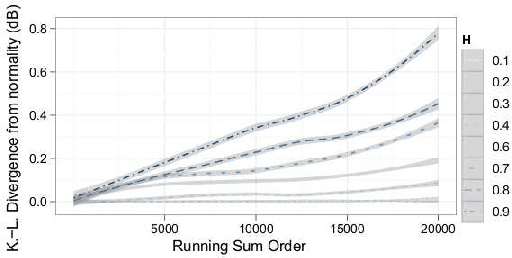



Current methods for determining whether a time series exhibits fractal structure (FS) rely on subjective assessments on estimators of the Hurst exponent (H). Here, I introduce the Bayesian Assessment of Scaling, an analytical framework for drawing objective and accurate inferences on the FS of time series. The technique exploits the scaling property of the diffusion associated to a time series. The resulting criterion is simple to compute and represents an accurate characterization of the evidence supporting different hypotheses on the scaling regime of a time series. Additionally, a closed-form Maximum Likelihood estimator of H is derived from the criterion, and this estimator outperforms the best available estimators.