 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Zipf's Law to Neural Scaling through Heaps' Law and Hilberg's Hypothesis
Dec 20, 2025We inspect the deductive connection between the neural scaling law and Zipf's law -- two statements discussed in machine learning and quantitative linguistics. The neural scaling law describes how the cross entropy rate of a foundation model -- such as a large language model -- changes with respect to the amount of training tokens, parameters, and compute. By contrast, Zipf's law posits that the distribution of tokens exhibits a power law tail. Whereas similar claims have been made in more specific settings, we show that the neural scaling law is a consequence of Zipf's law under certain broad assumptions that we reveal systematically. The derivation steps are as follows: We derive Heaps' law on the vocabulary growth from Zipf's law, Hilberg's hypothesis on the entropy scaling from Heaps' law, and the neural scaling from Hilberg's hypothesis. We illustrate these inference steps by a toy example of the Santa Fe process that satisfies all the four statistical laws.
Corrections of Zipf's and Heaps' Laws Derived from Hapax Rate Models
Jul 25, 2023The article introduces corrections to Zipf's and Heaps' laws based on systematic models of the hapax rate. The derivation rests on two assumptions: The first one is the standard urn model which predicts that marginal frequency distributions for shorter texts look as if word tokens were sampled blindly from a given longer text. The second assumption posits that the rate of hapaxes is a simple function of the text size. Four such functions are discussed: the constant model, the Davis model, the linear model, and the logistic model. It is shown that the logistic model yields the best fit.
A Simplistic Model of Neural Scaling Laws: Multiperiodic Santa Fe Processes
Feb 17, 2023
It was observed that large language models exhibit a power-law decay of cross entropy with respect to the number of parameters and training tokens. When extrapolated literally, this decay implies that the entropy rate of natural language is zero. To understand this phenomenon -- or an artifact -- better, we construct a simple stationary stochastic process and its memory-based predictor that exhibit a power-law decay of cross entropy with the vanishing entropy rate. Our example is based on previously discussed Santa Fe processes, which decompose a random text into a process of narration and time-independent knowledge. Previous discussions assumed that narration is a memoryless source with Zipf's distribution. In this paper, we propose a model of narration that has the vanishing entropy rate and applies a randomly chosen deterministic sequence called a multiperiodic sequence. Under a suitable parameterization, multiperiodic sequences exhibit asymptotic relative frequencies given by Zipf's law. Remaining agnostic about the value of the entropy rate of natural language, we discuss relevance of similar constructions for language modeling.
Local Grammar-Based Coding Revisited
Sep 27, 2022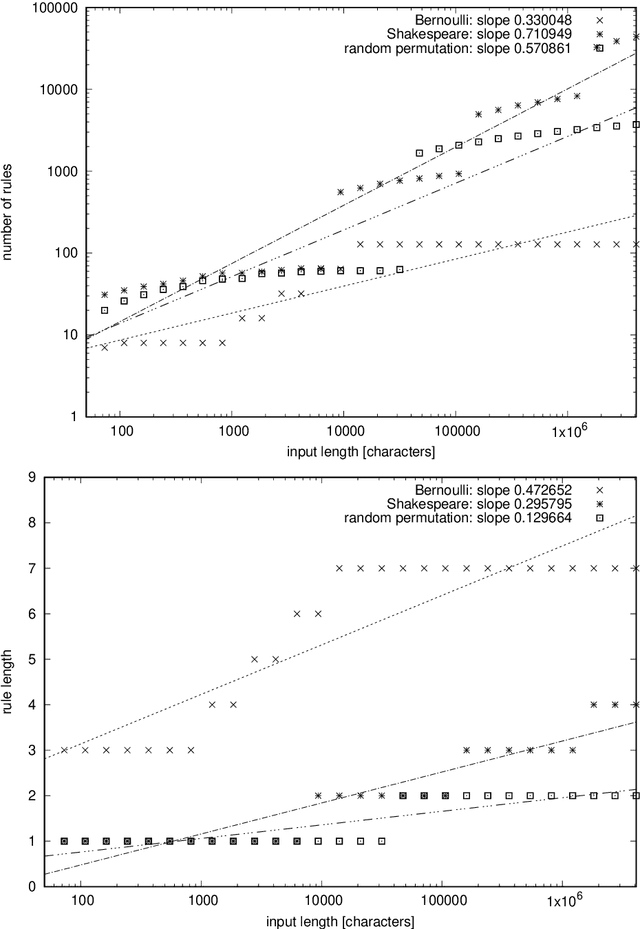
We revisit the problem of minimal local grammar-based coding. In this setting, the local grammar encoder encodes grammars symbol by symbol, whereas the minimal grammar transform minimizes the grammar length in a preset class of grammars as given by the length of local grammar encoding. It is known that such minimal codes are strongly universal for a strictly positive entropy rate, whereas the number of rules in the minimal grammar constitutes an upper bound for the mutual information of the source. Whereas the fully minimal code is likely intractable, the constrained minimal block code can be efficiently computed. In this note, we present a new, simpler, and more general proof of strong universality of the minimal block code, regardless of the entropy rate. The proof is based on a simple Zipfian bound for ranked probabilities. By the way, we also show empirically that the number of rules in the minimal block code cannot clearly discriminate between long-memory and memoryless sources, such as a text in English and a random permutation of its characters. This contradicts our previous expectations.
Is Natural Language a Perigraphic Process? The Theorem about Facts and Words Revisited
Nov 21, 2017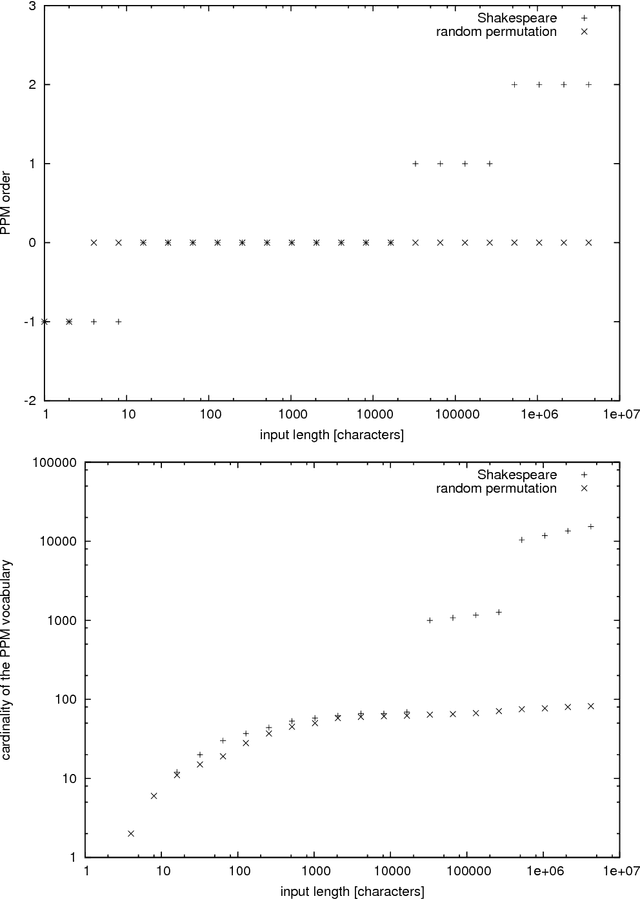
As we discuss, a stationary stochastic process is nonergodic when a random persistent topic can be detected in the infinite random text sampled from the process, whereas we call the process strongly nonergodic when an infinite sequence of independent random bits, called probabilistic facts, is needed to describe this topic completely. Replacing probabilistic facts with an algorithmically random sequence of bits, called algorithmic facts, we adapt this property back to ergodic processes. Subsequently, we call a process perigraphic if the number of algorithmic facts which can be inferred from a finite text sampled from the process grows like a power of the text length. We present a simple example of such a process. Moreover, we demonstrate an assertion which we call the theorem about facts and words. This proposition states that the number of probabilistic or algorithmic facts which can be inferred from a text drawn from a process must be roughly smaller than the number of distinct word-like strings detected in this text by means of the PPM compression algorithm. We also observe that the number of the word-like strings for a sample of plays by Shakespeare follows an empirical stepwise power law, in a stark contrast to Markov processes. Hence we suppose that natural language considered as a process is not only non-Markov but also perigraphic.
A Preadapted Universal Switch Distribution for Testing Hilberg's Conjecture
Mar 06, 2015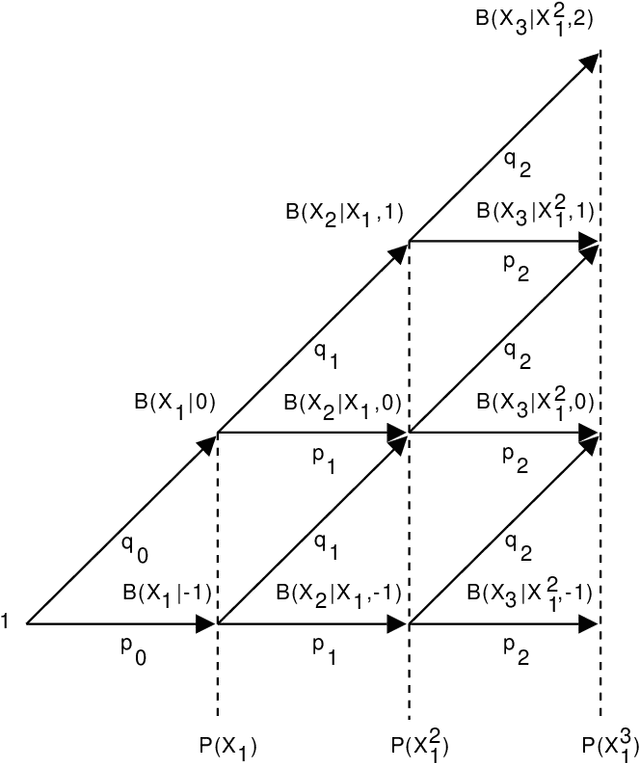
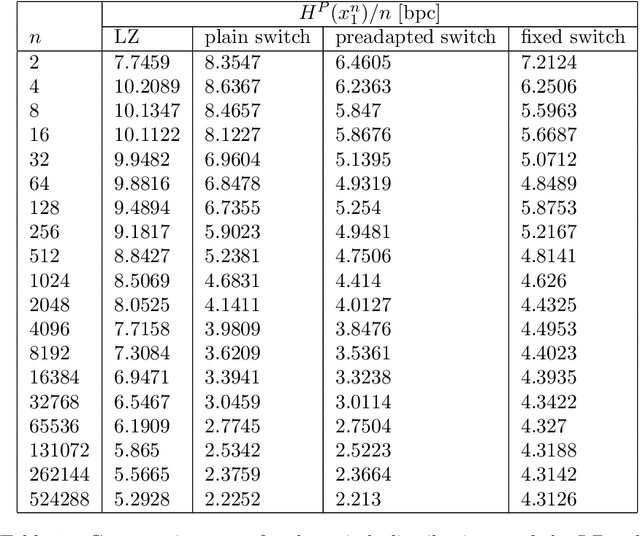
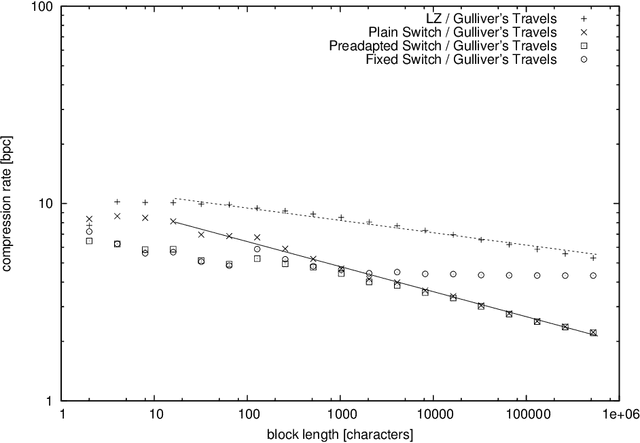
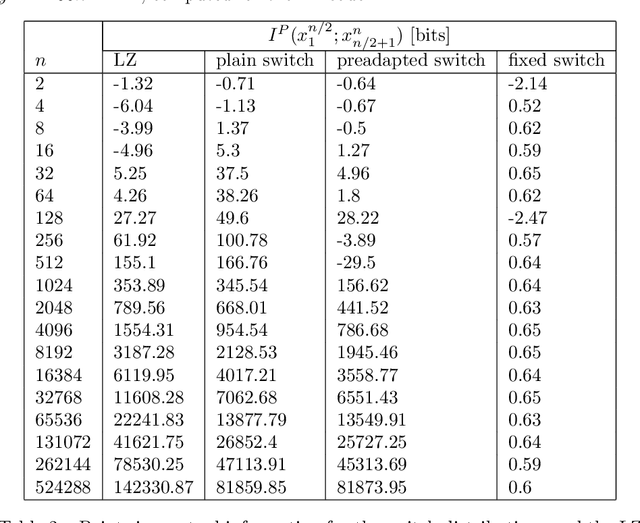
Hilberg's conjecture about natural language states that the mutual information between two adjacent long blocks of text grows like a power of the block length. The exponent in this statement can be upper bounded using the pointwise mutual information estimate computed for a carefully chosen code. The bound is the better, the lower the compression rate is but there is a requirement that the code be universal. So as to improve a received upper bound for Hilberg's exponent, in this paper, we introduce two novel universal codes, called the plain switch distribution and the preadapted switch distribution. Generally speaking, switch distributions are certain mixtures of adaptive Markov chains of varying orders with some additional communication to avoid so called catch-up phenomenon. The advantage of these distributions is that they both achieve a low compression rate and are guaranteed to be universal. Using the switch distributions we obtain that a sample of a text in English is non-Markovian with Hilberg's exponent being $\le 0.83$, which improves over the previous bound $\le 0.94$ obtained using the Lempel-Ziv code.
* 17 pages, 3 figures
Constant conditional entropy and related hypotheses
May 23, 2013Constant entropy rate (conditional entropies must remain constant as the sequence length increases) and uniform information density (conditional probabilities must remain constant as the sequence length increases) are two information theoretic principles that are argued to underlie a wide range of linguistic phenomena. Here we revise the predictions of these principles to the light of Hilberg's law on the scaling of conditional entropy in language and related laws. We show that constant entropy rate (CER) and two interpretations for uniform information density (UID), full UID and strong UID, are inconsistent with these laws. Strong UID implies CER but the reverse is not true. Full UID, a particular case of UID, leads to costly uncorrelated sequences that are totally unrealistic. We conclude that CER and its particular cases are incomplete hypotheses about the scaling of conditional entropies.
* introduction improved; typos corrected
Mixing, Ergodic, and Nonergodic Processes with Rapidly Growing Information between Blocks
Nov 22, 2011We construct mixing processes over an infinite alphabet and ergodic processes over a finite alphabet for which Shannon mutual information between adjacent blocks of length $n$ grows as $n^\beta$, where $\beta\in(0,1)$. The processes are a modification of nonergodic Santa Fe processes, which were introduced in the context of natural language modeling. The rates of mutual information for the latter processes are alike and also established in this paper. As an auxiliary result, it is shown that infinite direct products of mixing processes are also mixing.
On the Vocabulary of Grammar-Based Codes and the Logical Consistency of Texts
Feb 07, 2011The article presents a new interpretation for Zipf-Mandelbrot's law in natural language which rests on two areas of information theory. Firstly, we construct a new class of grammar-based codes and, secondly, we investigate properties of strongly nonergodic stationary processes. The motivation for the joint discussion is to prove a proposition with a simple informal statement: If a text of length $n$ describes $n^\beta$ independent facts in a repetitive way then the text contains at least $n^\beta/\log n$ different words, under suitable conditions on $n$. In the formal statement, two modeling postulates are adopted. Firstly, the words are understood as nonterminal symbols of the shortest grammar-based encoding of the text. Secondly, the text is assumed to be emitted by a finite-energy strongly nonergodic source whereas the facts are binary IID variables predictable in a shift-invariant way.
Valence extraction using EM selection and co-occurrence matrices
Nov 27, 2009This paper discusses two new procedures for extracting verb valences from raw texts, with an application to the Polish language. The first novel technique, the EM selection algorithm, performs unsupervised disambiguation of valence frame forests, obtained by applying a non-probabilistic deep grammar parser and some post-processing to the text. The second new idea concerns filtering of incorrect frames detected in the parsed text and is motivated by an observation that verbs which take similar arguments tend to have similar frames. This phenomenon is described in terms of newly introduced co-occurrence matrices. Using co-occurrence matrices, we split filtering into two steps. The list of valid arguments is first determined for each verb, whereas the pattern according to which the arguments are combined into frames is computed in the following stage. Our best extracted dictionary reaches an $F$-score of 45%, compared to an $F$-score of 39% for the standard frame-based BHT filtering.
* 24 pages, 3 tables