 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Synthetic Data Generation for Domain Adaptation of Question Answering Systems
Oct 12, 2020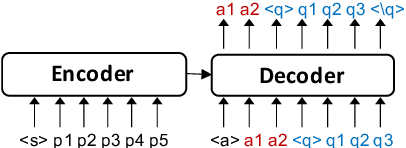

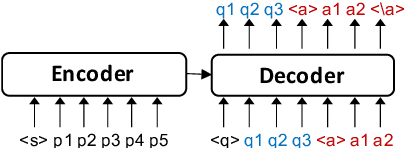
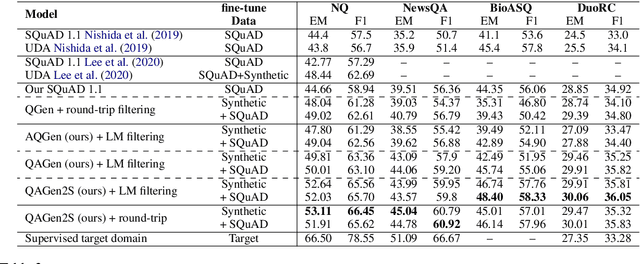
We propose an end-to-end approach for synthetic QA data generation. Our model comprises a single transformer-based encoder-decoder network that is trained end-to-end to generate both answers and questions. In a nutshell, we feed a passage to the encoder and ask the decoder to generate a question and an answer token-by-token. The likelihood produced in the generation process is used as a filtering score, which avoids the need for a separate filtering model. Our generator is trained by fine-tuning a pretrained LM using maximum likelihood estimation. The experimental results indicate significant improvements in the domain adaptation of QA models outperforming current state-of-the-art methods.
Who did They Respond to? Conversation Structure Modeling using Masked Hierarchical Transformer
Nov 25, 2019
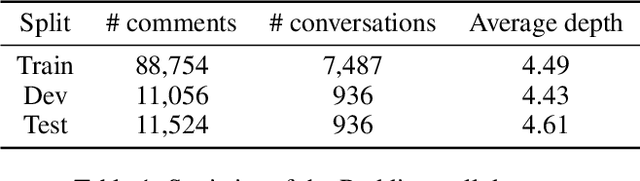
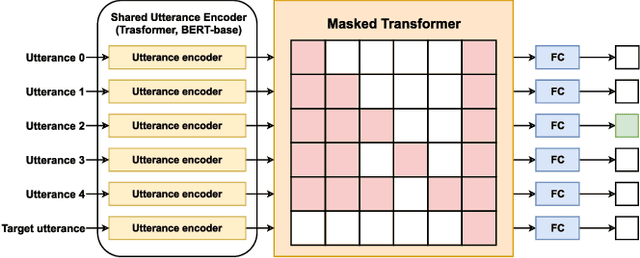
Conversation structure is useful for both understanding the nature of conversation dynamics and for providing features for many downstream applications such as summarization of conversations. In this work, we define the problem of conversation structure modeling as identifying the parent utterance(s) to which each utterance in the conversation responds to. Previous work usually took a pair of utterances to decide whether one utterance is the parent of the other. We believe the entire ancestral history is a very important information source to make accurate prediction. Therefore, we design a novel masking mechanism to guide the ancestor flow, and leverage the transformer model to aggregate all ancestors to predict parent utterances. Our experiments are performed on the Reddit dataset (Zhang, Culbertson, and Paritosh 2017) and the Ubuntu IRC dataset (Kummerfeld et al. 2019). In addition, we also report experiments on a new larger corpus from the Reddit platform and release this dataset. We show that the proposed model, that takes into account the ancestral history of the conversation, significantly outperforms several strong baselines including the BERT model on all datasets
Topic Modeling with Wasserstein Autoencoders
Jul 24, 2019
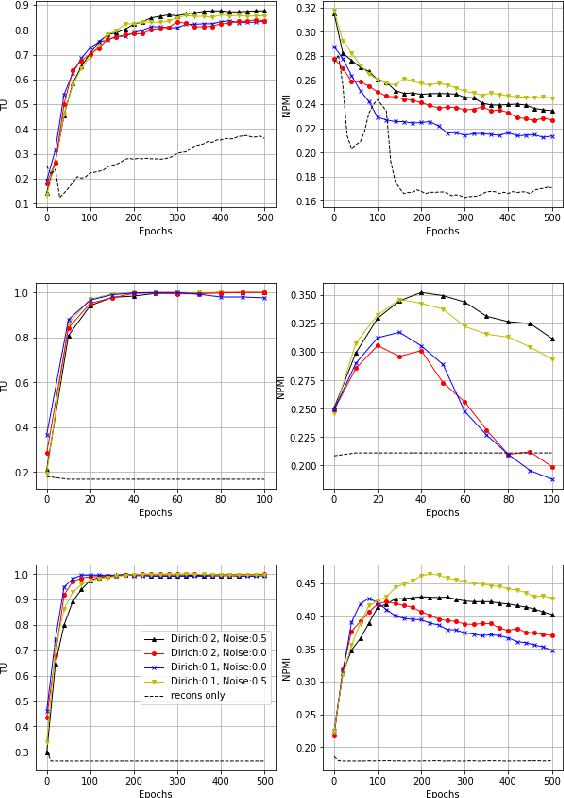

We propose a novel neural topic model in the Wasserstein autoencoders (WAE) framework. Unlike existing variational autoencoder based models, we directly enforce Dirichlet prior on the latent document-topic vectors. We exploit the structure of the latent space and apply a suitable kernel in minimizing the Maximum Mean Discrepancy (MMD) to perform distribution matching. We discover that MMD performs much better than the Generative Adversarial Network (GAN) in matching high dimensional Dirichlet distribution. We further discover that incorporating randomness in the encoder output during training leads to significantly more coherent topics. To measure the diversity of the produced topics, we propose a simple topic uniqueness metric. Together with the widely used coherence measure NPMI, we offer a more wholistic evaluation of topic quality. Experiments on several real datasets show that our model produces significantly better topics than existing topic models.
Sequential Dynamic Decision Making with Deep Neural Nets on a Test-Time Budget
May 31, 2017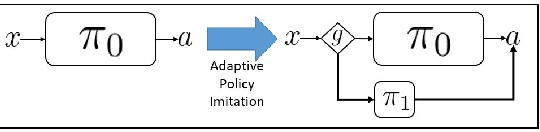
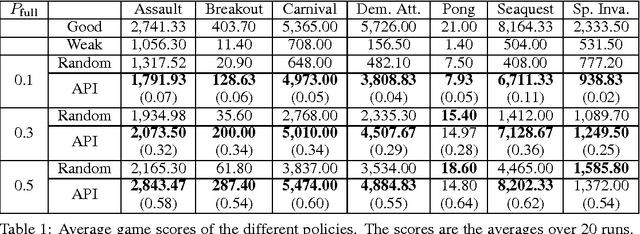
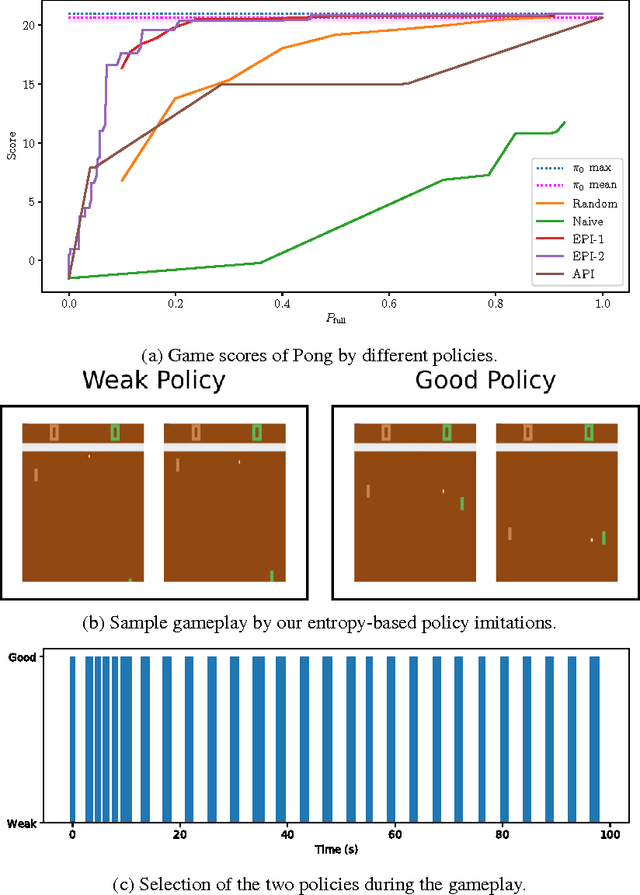
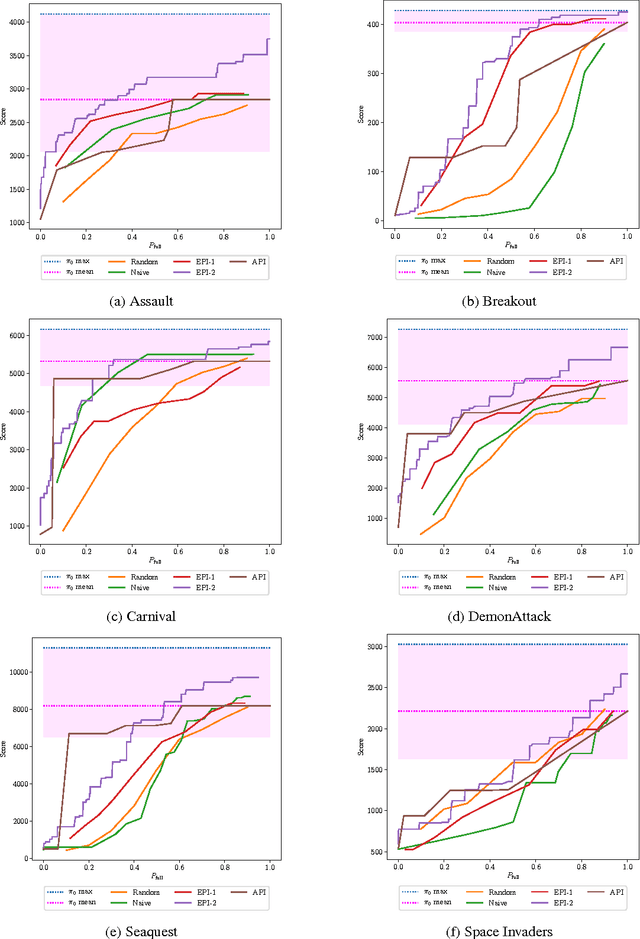
Deep neural network (DNN) based approaches hold significant potential for reinforcement learning (RL) and have already shown remarkable gains over state-of-art methods in a number of applications. The effectiveness of DNN methods can be attributed to leveraging the abundance of supervised data to learn value functions, Q-functions, and policy function approximations without the need for feature engineering. Nevertheless, the deployment of DNN-based predictors with very deep architectures can pose an issue due to computational and other resource constraints at test-time in a number of applications. We propose a novel approach for reducing the average latency by learning a computationally efficient gating function that is capable of recognizing states in a sequential decision process for which policy prescriptions of a shallow network suffices and deeper layers of the DNN have little marginal utility. The overall system is adaptive in that it dynamically switches control actions based on state-estimates in order to reduce average latency without sacrificing terminal performance. We experiment with a number of alternative loss-functions to train gating functions and shallow policies and show that in a number of applications a speed-up of up to almost 5X can be obtained with little loss in performance.
Adaptive Classification for Prediction Under a Budget
May 26, 2017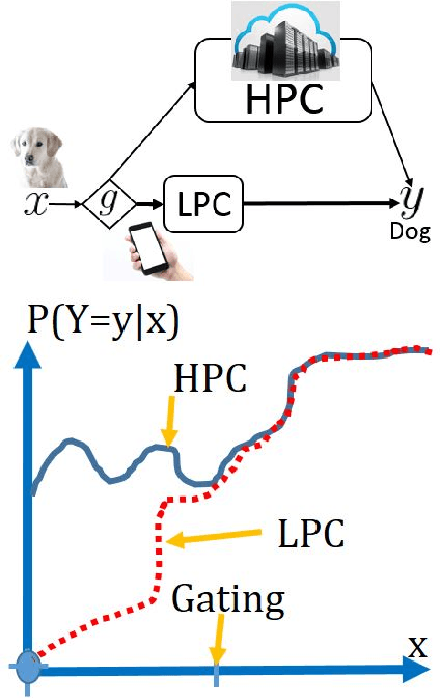
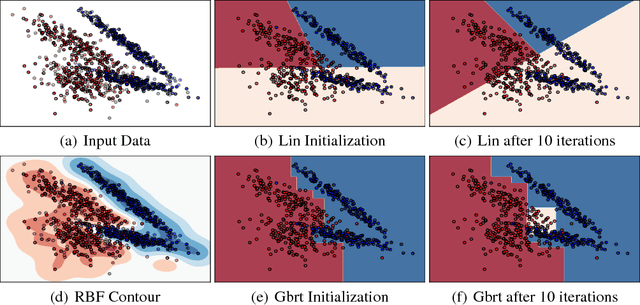
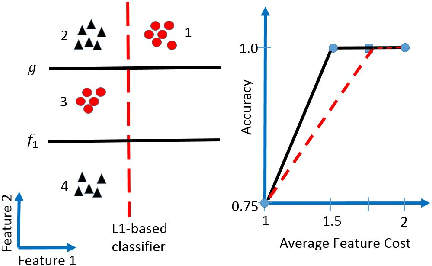
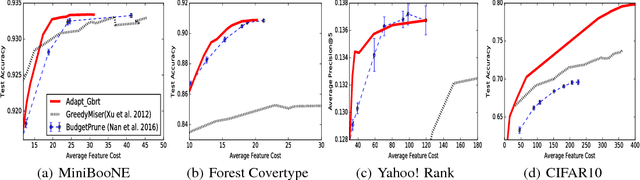
We propose a novel adaptive approximation approach for test-time resource-constrained prediction. Given an input instance at test-time, a gating function identifies a prediction model for the input among a collection of models. Our objective is to minimize overall average cost without sacrificing accuracy. We learn gating and prediction models on fully labeled training data by means of a bottom-up strategy. Our novel bottom-up method first trains a high-accuracy complex model. Then a low-complexity gating and prediction model are subsequently learned to adaptively approximate the high-accuracy model in regions where low-cost models are capable of making highly accurate predictions. We pose an empirical loss minimization problem with cost constraints to jointly train gating and prediction models. On a number of benchmark datasets our method outperforms state-of-the-art achieving higher accuracy for the same cost.
Comments on the proof of adaptive submodular function minimization
May 10, 2017
We point out an issue with Theorem 5 appearing in "Group-based active query selection for rapid diagnosis in time-critical situations". Theorem 5 bounds the expected number of queries for a greedy algorithm to identify the class of an item within a constant factor of optimal. The Theorem is based on correctness of a result on minimization of adaptive submodular functions. We present an example that shows that a critical step in Theorem A.11 of "Adaptive Submodularity: Theory and Applications in Active Learning and Stochastic Optimization" is incorrect.
Dynamic Model Selection for Prediction Under a Budget
Apr 25, 2017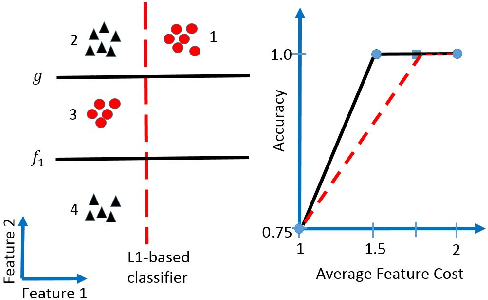
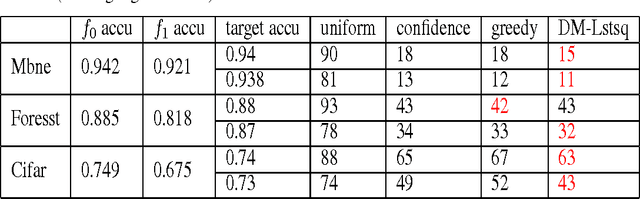
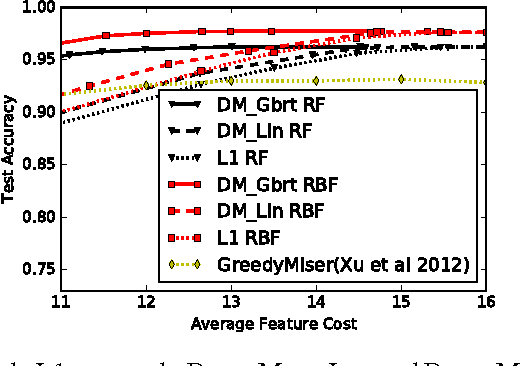
We present a dynamic model selection approach for resource-constrained prediction. Given an input instance at test-time, a gating function identifies a prediction model for the input among a collection of models. Our objective is to minimize overall average cost without sacrificing accuracy. We learn gating and prediction models on fully labeled training data by means of a bottom-up strategy. Our novel bottom-up method is a recursive scheme whereby a high-accuracy complex model is first trained. Then a low-complexity gating and prediction model are subsequently learnt to adaptively approximate the high-accuracy model in regions where low-cost models are capable of making highly accurate predictions. We pose an empirical loss minimization problem with cost constraints to jointly train gating and prediction models. On a number of benchmark datasets our method outperforms state-of-the-art achieving higher accuracy for the same cost.
Pruning Random Forests for Prediction on a Budget
Jun 16, 2016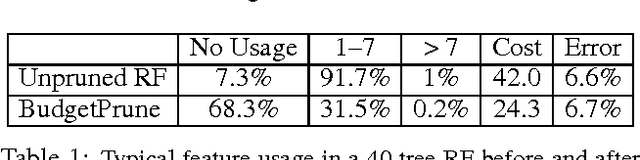

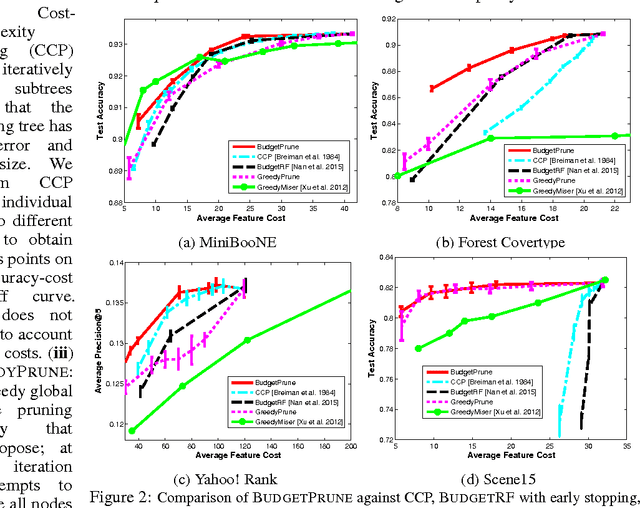
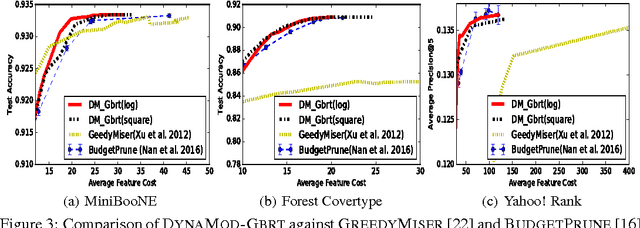
We propose to prune a random forest (RF) for resource-constrained prediction. We first construct a RF and then prune it to optimize expected feature cost & accuracy. We pose pruning RFs as a novel 0-1 integer program with linear constraints that encourages feature re-use. We establish total unimodularity of the constraint set to prove that the corresponding LP relaxation solves the original integer program. We then exploit connections to combinatorial optimization and develop an efficient primal-dual algorithm, scalable to large datasets. In contrast to our bottom-up approach, which benefits from good RF initialization, conventional methods are top-down acquiring features based on their utility value and is generally intractable, requiring heuristics. Empirically, our pruning algorithm outperforms existing state-of-the-art resource-constrained algorithms.
Optimally Pruning Decision Tree Ensembles With Feature Cost
Jan 05, 2016
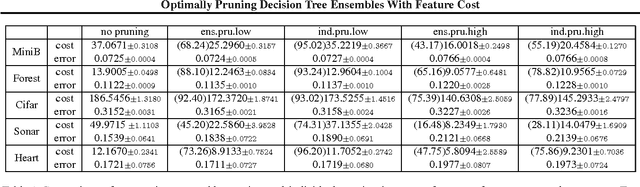
We consider the problem of learning decision rules for prediction with feature budget constraint. In particular, we are interested in pruning an ensemble of decision trees to reduce expected feature cost while maintaining high prediction accuracy for any test example. We propose a novel 0-1 integer program formulation for ensemble pruning. Our pruning formulation is general - it takes any ensemble of decision trees as input. By explicitly accounting for feature-sharing across trees together with accuracy/cost trade-off, our method is able to significantly reduce feature cost by pruning subtrees that introduce more loss in terms of feature cost than benefit in terms of prediction accuracy gain. Theoretically, we prove that a linear programming relaxation produces the exact solution of the original integer program. This allows us to use efficient convex optimization tools to obtain an optimally pruned ensemble for any given budget. Empirically, we see that our pruning algorithm significantly improves the performance of the state of the art ensemble method BudgetRF.
Feature-Budgeted Random Forest
Feb 20, 2015
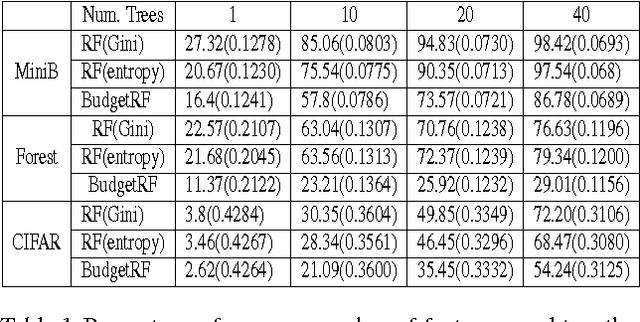
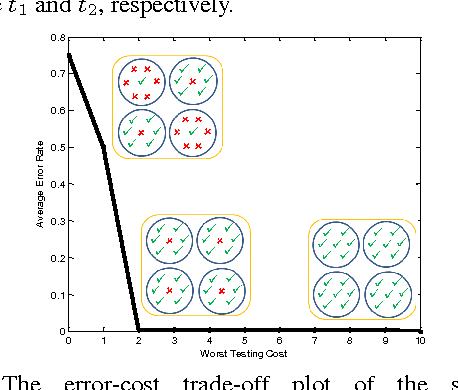
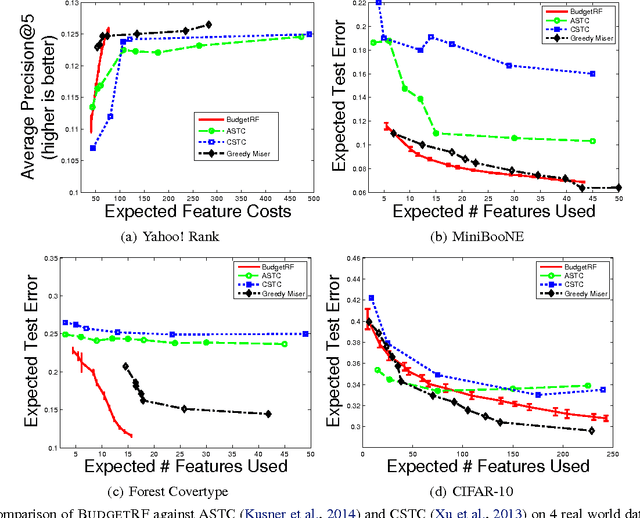
We seek decision rules for prediction-time cost reduction, where complete data is available for training, but during prediction-time, each feature can only be acquired for an additional cost. We propose a novel random forest algorithm to minimize prediction error for a user-specified {\it average} feature acquisition budget. While random forests yield strong generalization performance, they do not explicitly account for feature costs and furthermore require low correlation among trees, which amplifies costs. Our random forest grows trees with low acquisition cost and high strength based on greedy minimax cost-weighted-impurity splits. Theoretically, we establish near-optimal acquisition cost guarantees for our algorithm. Empirically, on a number of benchmark datasets we demonstrate superior accuracy-cost curves against state-of-the-art prediction-time algorithms.