 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating Time Series Models for Urban Wastewater Management: Predictive Performance, Model Complexity and Resilience
Apr 24, 2025Climate change increases the frequency of extreme rainfall, placing a significant strain on urban infrastructures, especially Combined Sewer Systems (CSS). Overflows from overburdened CSS release untreated wastewater into surface waters, posing environmental and public health risks. Although traditional physics-based models are effective, they are costly to maintain and difficult to adapt to evolving system dynamics. Machine Learning (ML) approaches offer cost-efficient alternatives with greater adaptability. To systematically assess the potential of ML for modeling urban infrastructure systems, we propose a protocol for evaluating Neural Network architectures for CSS time series forecasting with respect to predictive performance, model complexity, and robustness to perturbations. In addition, we assess model performance on peak events and critical fluctuations, as these are the key regimes for urban wastewater management. To investigate the feasibility of lightweight models suitable for IoT deployment, we compare global models, which have access to all information, with local models, which rely solely on nearby sensor readings. Additionally, to explore the security risks posed by network outages or adversarial attacks on urban infrastructure, we introduce error models that assess the resilience of models. Our results demonstrate that while global models achieve higher predictive performance, local models provide sufficient resilience in decentralized scenarios, ensuring robust modeling of urban infrastructure. Furthermore, models with longer native forecast horizons exhibit greater robustness to data perturbations. These findings contribute to the development of interpretable and reliable ML solutions for sustainable urban wastewater management. The implementation is available in our GitHub repository.
Generating Synthetic Satellite Imagery for Rare Objects: An Empirical Comparison of Models and Metrics
Sep 02, 2024



Generative deep learning architectures can produce realistic, high-resolution fake imagery -- with potentially drastic societal implications. A key question in this context is: How easy is it to generate realistic imagery, in particular for niche domains. The iterative process required to achieve specific image content is difficult to automate and control. Especially for rare classes, it remains difficult to assess fidelity, meaning whether generative approaches produce realistic imagery and alignment, meaning how (well) the generation can be guided by human input. In this work, we present a large-scale empirical evaluation of generative architectures which we fine-tuned to generate synthetic satellite imagery. We focus on nuclear power plants as an example of a rare object category - as there are only around 400 facilities worldwide, this restriction is exemplary for many other scenarios in which training and test data is limited by the restricted number of occurrences of real-world examples. We generate synthetic imagery by conditioning on two kinds of modalities, textual input and image input obtained from a game engine that allows for detailed specification of the building layout. The generated images are assessed by commonly used metrics for automatic evaluation and then compared with human judgement from our conducted user studies to assess their trustworthiness. Our results demonstrate that even for rare objects, generation of authentic synthetic satellite imagery with textual or detailed building layouts is feasible. In line with previous work, we find that automated metrics are often not aligned with human perception -- in fact, we find strong negative correlations between commonly used image quality metrics and human ratings.
Data-driven Modeling of Combined Sewer Systems for Urban Sustainability: An Empirical Evaluation
Aug 21, 2024Climate change poses complex challenges, with extreme weather events becoming increasingly frequent and difficult to model. Examples include the dynamics of Combined Sewer Systems (CSS). Overburdened CSS during heavy rainfall will overflow untreated wastewater into surface water bodies. Classical approaches to modeling the impact of extreme rainfall events rely on physical simulations, which are particularly challenging to create for large urban infrastructures. Deep Learning (DL) models offer a cost-effective alternative for modeling the complex dynamics of sewer systems. In this study, we present a comprehensive empirical evaluation of several state-of-the-art DL time series models for predicting sewer system dynamics in a large urban infrastructure, utilizing three years of measurement data. We especially investigate the potential of DL models to maintain predictive precision during network outages by comparing global models, which have access to all variables within the sewer system, and local models, which are limited to data from a restricted set of local sensors. Our findings demonstrate that DL models can accurately predict the dynamics of sewer system load, even under network outage conditions. These results suggest that DL models can effectively aid in balancing the load redistribution in CSS, thereby enhancing the sustainability and resilience of urban infrastructures.
Automated Computational Energy Minimization of ML Algorithms using Constrained Bayesian Optimization
Jul 08, 2024Bayesian optimization (BO) is an efficient framework for optimization of black-box objectives when function evaluations are costly and gradient information is not easily accessible. BO has been successfully applied to automate the task of hyperparameter optimization (HPO) in machine learning (ML) models with the primary objective of optimizing predictive performance on held-out data. In recent years, however, with ever-growing model sizes, the energy cost associated with model training has become an important factor for ML applications. Here we evaluate Constrained Bayesian Optimization (CBO) with the primary objective of minimizing energy consumption and subject to the constraint that the generalization performance is above some threshold. We evaluate our approach on regression and classification tasks and demonstrate that CBO achieves lower energy consumption without compromising the predictive performance of ML models.
Using Game Engines and Machine Learning to Create Synthetic Satellite Imagery for a Tabletop Verification Exercise
Apr 17, 2024



Satellite imagery is regarded as a great opportunity for citizen-based monitoring of activities of interest. Relevant imagery may however not be available at sufficiently high resolution, quality, or cadence -- let alone be uniformly accessible to open-source analysts. This limits an assessment of the true long-term potential of citizen-based monitoring of nuclear activities using publicly available satellite imagery. In this article, we demonstrate how modern game engines combined with advanced machine-learning techniques can be used to generate synthetic imagery of sites of interest with the ability to choose relevant parameters upon request; these include time of day, cloud cover, season, or level of activity onsite. At the same time, resolution and off-nadir angle can be adjusted to simulate different characteristics of the satellite. While there are several possible use-cases for synthetic imagery, here we focus on its usefulness to support tabletop exercises in which simple monitoring scenarios can be examined to better understand verification capabilities enabled by new satellite constellations and very short revisit times.
Generating Synthetic Satellite Imagery With Deep-Learning Text-to-Image Models -- Technical Challenges and Implications for Monitoring and Verification
Apr 11, 2024Novel deep-learning (DL) architectures have reached a level where they can generate digital media, including photorealistic images, that are difficult to distinguish from real data. These technologies have already been used to generate training data for Machine Learning (ML) models, and large text-to-image models like DALL-E 2, Imagen, and Stable Diffusion are achieving remarkable results in realistic high-resolution image generation. Given these developments, issues of data authentication in monitoring and verification deserve a careful and systematic analysis: How realistic are synthetic images? How easily can they be generated? How useful are they for ML researchers, and what is their potential for Open Science? In this work, we use novel DL models to explore how synthetic satellite images can be created using conditioning mechanisms. We investigate the challenges of synthetic satellite image generation and evaluate the results based on authenticity and state-of-the-art metrics. Furthermore, we investigate how synthetic data can alleviate the lack of data in the context of ML methods for remote-sensing. Finally we discuss implications of synthetic satellite imagery in the context of monitoring and verification.
* https://resources.inmm.org/annual-meeting-proceedings/generating-synthetic-satellite-imagery-deep-learning-text-image-models
Interpretable Time Series Models for Wastewater Modeling in Combined Sewer Overflows
Jan 04, 2024Climate change poses increasingly complex challenges to our society. Extreme weather events such as floods, wild fires or droughts are becoming more frequent, spontaneous and difficult to foresee or counteract. In this work we specifically address the problem of sewage water polluting surface water bodies after spilling over from rain tanks as a consequence of heavy rain events. We investigate to what extent state-of-the-art interpretable time series models can help predict such critical water level points, so that the excess can promptly be redistributed across the sewage network. Our results indicate that modern time series models can contribute to better waste water management and prevention of environmental pollution from sewer systems. All the code and experiments can be found in our repository: https://github.com/TeodorChiaburu/RIWWER_TimeSeries.
Changes in Policy Preferences in German Tweets during the COVID Pandemic
Jul 31, 2023Online social media have become an important forum for exchanging political opinions. In response to COVID measures citizens expressed their policy preferences directly on these platforms. Quantifying political preferences in online social media remains challenging: The vast amount of content requires scalable automated extraction of political preferences -- however fine grained political preference extraction is difficult with current machine learning (ML) technology, due to the lack of data sets. Here we present a novel data set of tweets with fine grained political preference annotations. A text classification model trained on this data is used to extract policy preferences in a German Twitter corpus ranging from 2019 to 2022. Our results indicate that in response to the COVID pandemic, expression of political opinions increased. Using a well established taxonomy of policy preferences we analyse fine grained political views and highlight changes in distinct political categories. These analyses suggest that the increase in policy preference expression is dominated by the categories pro-welfare, pro-education and pro-governmental administration efficiency. All training data and code used in this study are made publicly available to encourage other researchers to further improve automated policy preference extraction methods. We hope that our findings contribute to a better understanding of political statements in online social media and to a better assessment of how COVID measures impact political preferences.
Automated Extraction of Fine-Grained Standardized Product Information from Unstructured Multilingual Web Data
Feb 23, 2023Extracting structured information from unstructured data is one of the key challenges in modern information retrieval applications, including e-commerce. Here, we demonstrate how recent advances in machine learning, combined with a recently published multilingual data set with standardized fine-grained product category information, enable robust product attribute extraction in challenging transfer learning settings. Our models can reliably predict product attributes across online shops, languages, or both. Furthermore, we show that our models can be used to match product taxonomies between online retailers.
GreenDB -- A Dataset and Benchmark for Extraction of Sustainability Information of Consumer Goods
Jul 29, 2022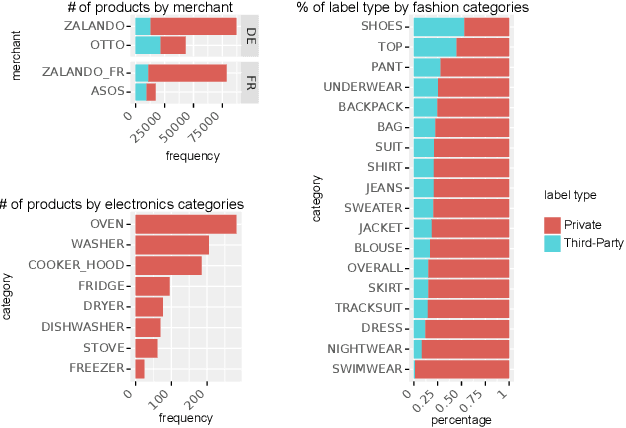
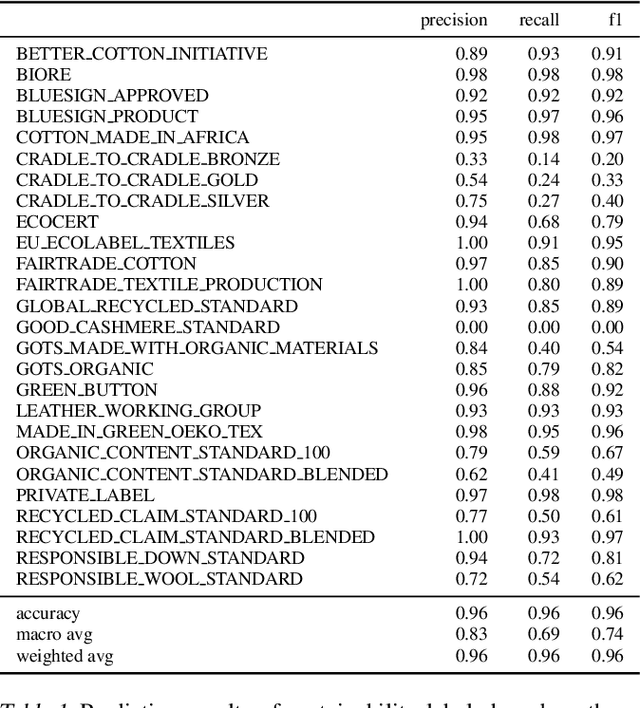
The production, shipping, usage, and disposal of consumer goods have a substantial impact on greenhouse gas emissions and the depletion of resources. Machine Learning (ML) can help to foster sustainable consumption patterns by accounting for sustainability aspects in product search or recommendations of modern retail platforms. However, the lack of large high quality publicly available product data with trustworthy sustainability information impedes the development of ML technology that can help to reach our sustainability goals. Here we present GreenDB, a database that collects products from European online shops on a weekly basis. As proxy for the products' sustainability, it relies on sustainability labels, which are evaluated by experts. The GreenDB schema extends the well-known schema.org Product definition and can be readily integrated into existing product catalogs. We present initial results demonstrating that ML models trained with our data can reliably (F1 score 96%) predict the sustainability label of products. These contributions can help to complement existing e-commerce experiences and ultimately encourage users to more sustainable consumption patterns.