 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultiSynt/MT: Trillion-Token Multi-Parallel Pre-Training Data Translated Across 36 Languages
Jul 01, 2026Open web-scale pre-training corpora remain concentrated in English, limiting multilingual LLM development. We introduce MultiSynt/MT, an open synthetic parallel corpus with approximately 4.8 trillion target-language tokens across 36 European languages, produced by translating 100 billion high-quality Nemotron-CC tokens with Tower+ and OPUS-MT/HPLT-MT systems. For many medium- and lower-resource European languages, this is the largest openly available pre-training resource. On a broad multilingual benchmark suite, reference LLMs trained on MultiSynt/MT reach the final score of HPLT 2.0, a native-data baseline, using roughly 72% fewer pre-training tokens, and outperform it by approximately 15% relative at a matched 100B-token training budget. Our analyses also identify evaluation blind spots: standard multiple-choice benchmarks miss translation-quality differences that a fluency-sensitive LLM-as-judge evaluation cleanly recovers on the trained LLMs (with no fluency deficit in MultiSynt itself), and Norwegian idiomatic and culturally grounded tasks remain better served by native data. We release the corpus, including row-aligned translations from multiple systems, to support controlled research on multilingual pre-training data and evaluation.
On the Limits of Model Merging for Multilinguality in Pre-Training
May 25, 2026Endowing models with consistent multilingual performance can be achieved by mixing pre-training data, or post-training approaches such as language-specific model merging. In this work, we test whether merging can be applied to monolingually pre-trained models. We conduct a controlled study on the efficacy of mixed, merged, and monolingual pre-training setups. We find that while monolingual pre-training results in strong in-language performance, merging any combination of monolingual models leads to performance collapse due to interference. Our analysis suggests representational similarity is a prerequisite for model merging. We therefore conclude that the flexibility of merging in fine-tuning does not extend trivially to language-specific pre-training.
FIN-bench-v2: A Unified and Robust Benchmark Suite for Evaluating Finnish Large Language Models
Dec 15, 2025



We introduce FIN-bench-v2, a unified benchmark suite for evaluating large language models in Finnish. FIN-bench-v2 consolidates Finnish versions of widely used benchmarks together with an updated and expanded version of the original FIN-bench into a single, consistently formatted collection, covering multiple-choice and generative tasks across reading comprehension, commonsense reasoning, sentiment analysis, world knowledge, and alignment. All datasets are converted to HuggingFace Datasets, which include both cloze and multiple-choice prompt formulations with five variants per task, and we incorporate human annotation or review for machine-translated resources such as GoldenSwag and XED. To select robust tasks, we pretrain a set of 2.15B-parameter decoder-only models and use their learning curves to compute monotonicity, signal-to-noise, non-random performance, and model ordering consistency, retaining only tasks that satisfy all criteria. We further evaluate a set of larger instruction-tuned models to characterize performance across tasks and prompt formulations. All datasets, prompts, and evaluation configurations are publicly available via our fork of the Language Model Evaluation Harness at https://github.com/LumiOpen/lm-evaluation-harness. Supplementary resources are released in a separate repository at https://github.com/TurkuNLP/FIN-bench-v2.
Unraveling Code-Mixing Patterns in Migration Discourse: Automated Detection and Analysis of Online Conversations on Reddit
Jun 12, 2024The surge in global migration patterns underscores the imperative of integrating migrants seamlessly into host communities, necessitating inclusive and trustworthy public services. Despite the Nordic countries' robust public sector infrastructure, recent immigrants often encounter barriers to accessing these services, exacerbating social disparities and eroding trust. Addressing digital inequalities and linguistic diversity is paramount in this endeavor. This paper explores the utilization of code-mixing, a communication strategy prevalent among multilingual speakers, in migration-related discourse on social media platforms such as Reddit. We present Ensemble Learning for Multilingual Identification of Code-mixed Texts (ELMICT), a novel approach designed to automatically detect code-mixed messages in migration-related discussions. Leveraging ensemble learning techniques for combining multiple tokenizers' outputs and pre-trained language models, ELMICT demonstrates high performance (with F1 more than 0.95) in identifying code-mixing across various languages and contexts, particularly in cross-lingual zero-shot conditions (with avg. F1 more than 0.70). Moreover, the utilization of ELMICT helps to analyze the prevalence of code-mixing in migration-related threads compared to other thematic categories on Reddit, shedding light on the topics of concern to migrant communities. Our findings reveal insights into the communicative strategies employed by migrants on social media platforms, offering implications for the development of inclusive digital public services and conversational systems. By addressing the research questions posed in this study, we contribute to the understanding of linguistic diversity in migration discourse and pave the way for more effective tools for building trust in multicultural societies.
Construction of Hyper-Relational Knowledge Graphs Using Pre-Trained Large Language Models
Mar 18, 2024



Extracting hyper-relations is crucial for constructing comprehensive knowledge graphs, but there are limited supervised methods available for this task. To address this gap, we introduce a zero-shot prompt-based method using OpenAI's GPT-3.5 model for extracting hyper-relational knowledge from text. Comparing our model with a baseline, we achieved promising results, with a recall of 0.77. Although our precision is currently lower, a detailed analysis of the model outputs has uncovered potential pathways for future research in this area.
Cross-Lingual Query-Based Summarization of Crisis-Related Social Media: An Abstractive Approach Using Transformers
Apr 21, 2022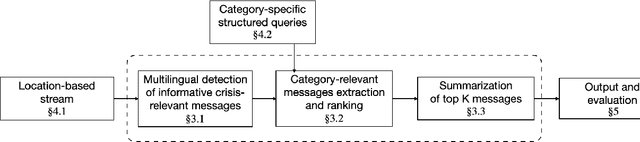


Relevant and timely information collected from social media during crises can be an invaluable resource for emergency management. However, extracting this information remains a challenging task, particularly when dealing with social media postings in multiple languages. This work proposes a cross-lingual method for retrieving and summarizing crisis-relevant information from social media postings. We describe a uniform way of expressing various information needs through structured queries and a way of creating summaries answering those information needs. The method is based on multilingual transformers embeddings. Queries are written in one of the languages supported by the embeddings, and the extracted sentences can be in any of the other languages supported. Abstractive summaries are created by transformers. The evaluation, done by crowdsourcing evaluators and emergency management experts, and carried out on collections extracted from Twitter during five large-scale disasters spanning ten languages, shows the flexibility of our approach. The generated summaries are regarded as more focused, structured, and coherent than existing state-of-the-art methods, and experts compare them favorably against summaries created by existing, state-of-the-art methods.