 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTest-time Recalibration of Conformal Predictors Under Distribution Shift Based on Unlabeled Examples
Oct 09, 2022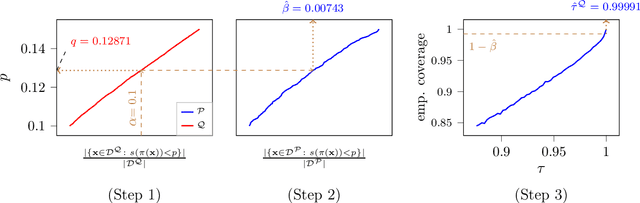
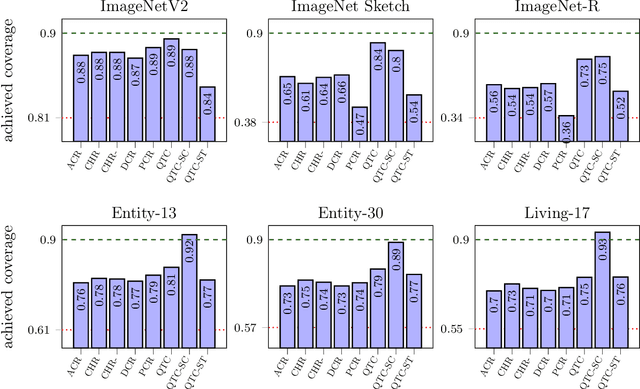
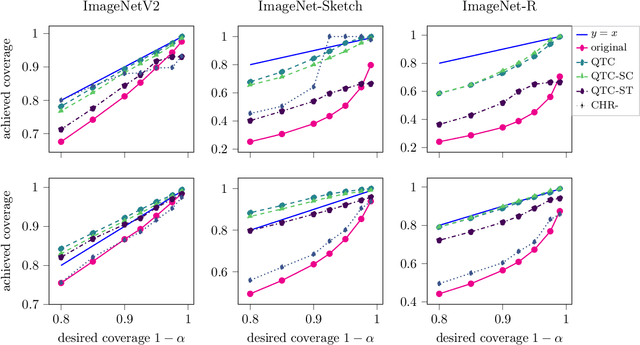
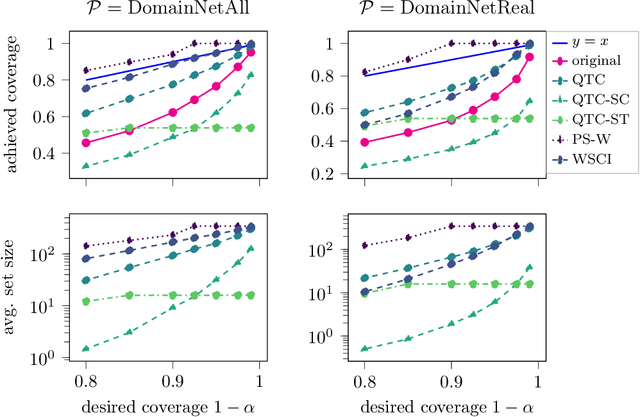
Modern image classifiers achieve high predictive accuracy, but the predictions typically come without reliable uncertainty estimates. Conformal prediction algorithms provide uncertainty estimates by predicting a set of classes based on the probability estimates of the classifier (for example, the softmax scores). To provide such sets, conformal prediction algorithms often rely on estimating a cutoff threshold for the probability estimates, and this threshold is chosen based on a calibration set. Conformal prediction methods guarantee reliability only when the calibration set is from the same distribution as the test set. Therefore, the methods need to be recalibrated for new distributions. However, in practice, labeled data from new distributions is rarely available, making calibration infeasible. In this work, we consider the problem of predicting the cutoff threshold for a new distribution based on unlabeled examples only. While it is impossible in general to guarantee reliability when calibrating based on unlabeled examples, we show that our method provides excellent uncertainty estimates under natural distribution shifts, and provably works for a specific model of a distribution shift.
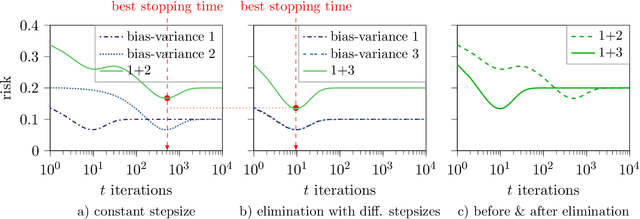
Regularization-wise double descent: Why it occurs and how to eliminate it
Jun 03, 2022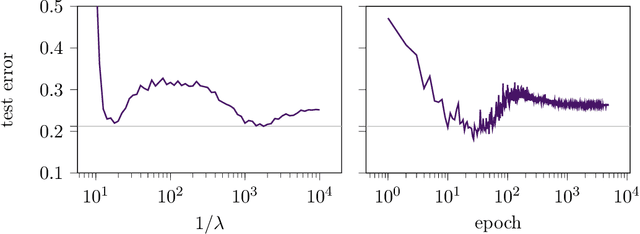
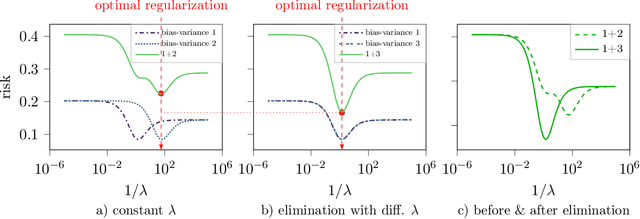
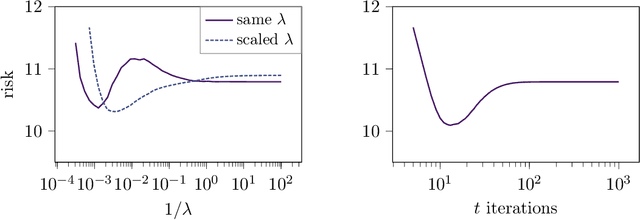
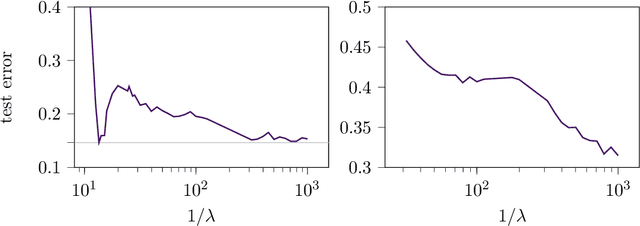
The risk of overparameterized models, in particular deep neural networks, is often double-descent shaped as a function of the model size. Recently, it was shown that the risk as a function of the early-stopping time can also be double-descent shaped, and this behavior can be explained as a super-position of bias-variance tradeoffs. In this paper, we show that the risk of explicit L2-regularized models can exhibit double descent behavior as a function of the regularization strength, both in theory and practice. We find that for linear regression, a double descent shaped risk is caused by a superposition of bias-variance tradeoffs corresponding to different parts of the model and can be mitigated by scaling the regularization strength of each part appropriately. Motivated by this result, we study a two-layer neural network and show that double descent can be eliminated by adjusting the regularization strengths for the first and second layer. Lastly, we study a 5-layer CNN and ResNet-18 trained on CIFAR-10 with label noise, and CIFAR-100 without label noise, and demonstrate that all exhibit double descent behavior as a function of the regularization strength.
Early Stopping in Deep Networks: Double Descent and How to Eliminate it
Jul 20, 2020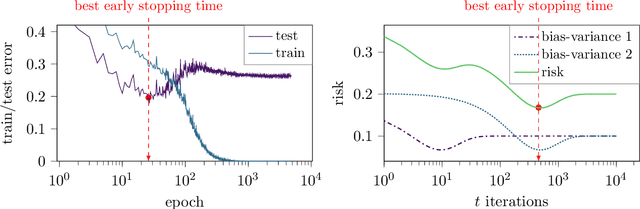
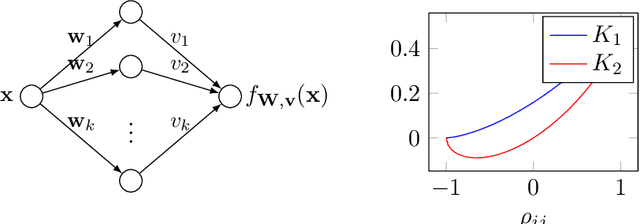
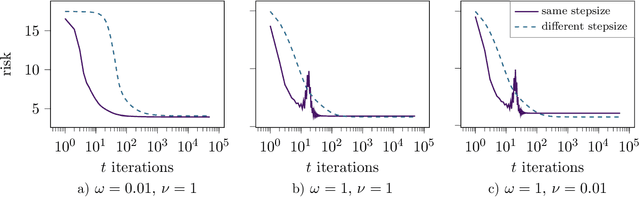
Over-parameterized models, in particular deep networks, often exhibit a double descent phenomenon, where as a function of model size, error first decreases, increases, and decreases at last. This intriguing double descent behavior also occurs as a function of training epochs, and has been conjectured to arise because training epochs control the model complexity. In this paper, we show that such epoch-wise double descent arises for a different reason: It is caused by a superposition of two or more bias-variance tradeoffs that arise because different parts of the network are learned at different times, and eliminating this by proper scaling of stepsizes can significantly improve the early stopping performance. We show this analytically for i) linear regression, where differently scaled features give rise to a superposition of bias-variance tradeoffs, and for ii) a two-layer neural network, where the first and second layers each govern a bias-variance tradeoff. Inspired by this theory, we study a five-layer convolutional network empirically and show that eliminating epoch-wise double descent through adjusting stepsizes of different layers improves the early stopping performance significantly.
Leveraging inductive bias of neural networks for learning without explicit human annotations
Oct 31, 2019
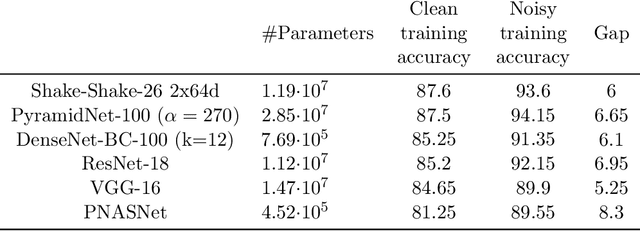
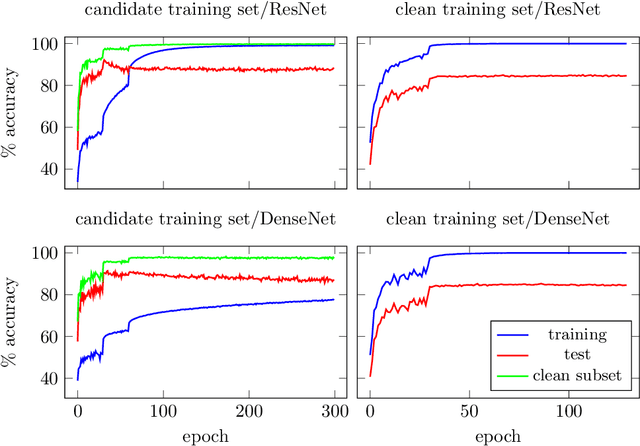
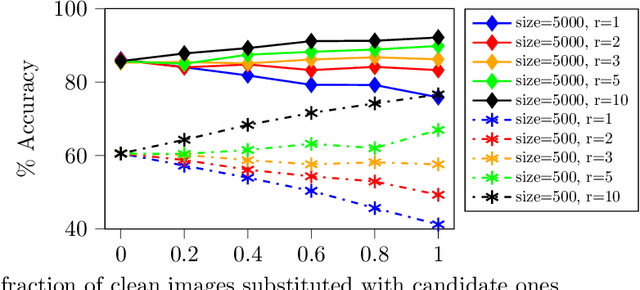
Classification problems today are often solved by first collecting examples along with candidate labels, second obtaining clean labels from workers, and third training a large, overparameterized deep neural network on the clean examples. The second, manual labeling step is often the most expensive one as it requires manually going through all examples. In this paper we propose to i) skip the manual labeling step entirely, ii) directly train the deep neural network on the noisy candidate labels, and iii) early stop the training to avoid overfitting. With this procedure we exploit an intriguing property of large overparameterized neural networks: While they are capable of perfectly fitting the noisy data, gradient descent fits clean labels faster than noisy ones. Thus, training and early stopping on noisy labels resembles training on clean labels only. Our results show that early stopping the training of standard deep networks (such as ResNet-18) on a subset of the Tiny Images dataset (which is obtained without any explicit human labels and only about half of the labels are correct), gives a significantly higher test performance than when trained on the clean CIFAR-10 training dataset (which is obtained by labeling a subset of the Tiny Images dataset). In addition, our results show that the noise generated through the label collection process is not nearly as adversarial for learning as the noise generated by randomly flipping labels, which is the noise most prevalent in works demonstrating noise robustness of neural networks.