 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBMFT: Achieving Fairness via Bias-based Weight Masking Fine-tuning
Aug 13, 2024Developing models with robust group fairness properties is paramount, particularly in ethically sensitive domains such as medical diagnosis. Recent approaches to achieving fairness in machine learning require a substantial amount of training data and depend on model retraining, which may not be practical in real-world scenarios. To mitigate these challenges, we propose Bias-based Weight Masking Fine-Tuning (BMFT), a novel post-processing method that enhances the fairness of a trained model in significantly fewer epochs without requiring access to the original training data. BMFT produces a mask over model parameters, which efficiently identifies the weights contributing the most towards biased predictions. Furthermore, we propose a two-step debiasing strategy, wherein the feature extractor undergoes initial fine-tuning on the identified bias-influenced weights, succeeded by a fine-tuning phase on a reinitialised classification layer to uphold discriminative performance. Extensive experiments across four dermatological datasets and two sensitive attributes demonstrate that BMFT outperforms existing state-of-the-art (SOTA) techniques in both diagnostic accuracy and fairness metrics. Our findings underscore the efficacy and robustness of BMFT in advancing fairness across various out-of-distribution (OOD) settings. Our code is available at: https://github.com/vios-s/BMFT
Connected Speech-Based Cognitive Assessment in Chinese and English
Jun 18, 2024



We present a novel benchmark dataset and prediction tasks for investigating approaches to assess cognitive function through analysis of connected speech. The dataset consists of speech samples and clinical information for speakers of Mandarin Chinese and English with different levels of cognitive impairment as well as individuals with normal cognition. These data have been carefully matched by age and sex by propensity score analysis to ensure balance and representativity in model training. The prediction tasks encompass mild cognitive impairment diagnosis and cognitive test score prediction. This framework was designed to encourage the development of approaches to speech-based cognitive assessment which generalise across languages. We illustrate it by presenting baseline prediction models that employ language-agnostic and comparable features for diagnosis and cognitive test score prediction. The models achieved unweighted average recall was 59.2% in diagnosis, and root mean squared error of 2.89 in score prediction.
Multilingual Alzheimer's Dementia Recognition through Spontaneous Speech: a Signal Processing Grand Challenge
Jan 13, 2023This Signal Processing Grand Challenge (SPGC) targets a difficult automatic prediction problem of societal and medical relevance, namely, the detection of Alzheimer's Dementia (AD). Participants were invited to employ signal processing and machine learning methods to create predictive models based on spontaneous speech data. The Challenge has been designed to assess the extent to which predictive models built based on speech in one language (English) generalise to another language (Greek). To the best of our knowledge no work has investigated acoustic features of the speech signal in multilingual AD detection. Our baseline system used conventional machine learning algorithms with Active Data Representation of acoustic features, achieving accuracy of 73.91% on AD detection, and 4.95 root mean squared error on cognitive score prediction.
Detecting cognitive decline using speech only: The ADReSSo Challenge
Mar 23, 2021Building on the success of the ADReSS Challenge at Interspeech 2020, which attracted the participation of 34 teams from across the world, the ADReSSo Challenge targets three difficult automatic prediction problems of societal and medical relevance, namely: detection of Alzheimer's Dementia, inference of cognitive testing scores, and prediction of cognitive decline. This paper presents these prediction tasks in detail, describes the datasets used, and reports the results of the baseline classification and regression models we developed for each task. A combination of acoustic and linguistic features extracted directly from audio recordings, without human intervention, yielded a baseline accuracy of 78.87% for the AD classification task, an MMSE prediction root mean squared (RMSE) error of 5.28, and 68.75% accuracy for the cognitive decline prediction task.
Alzheimer's Dementia Recognition through Spontaneous Speech: The ADReSS Challenge
Apr 30, 2020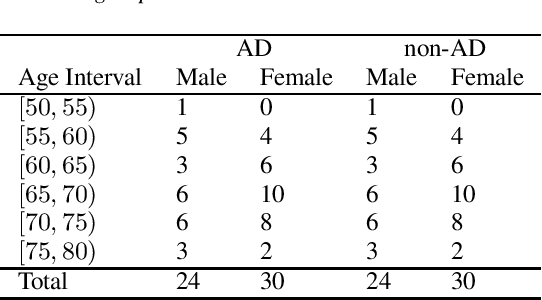
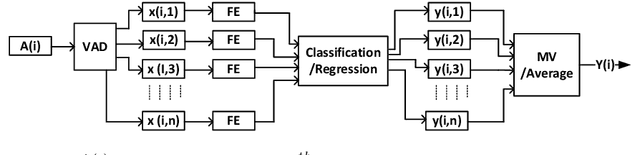
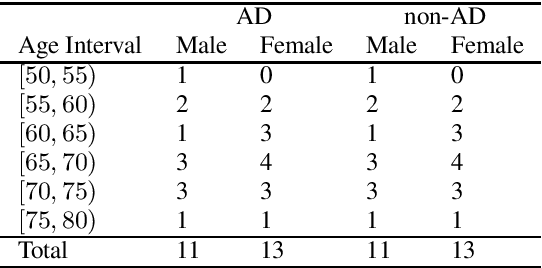

The ADReSS Challenge at INTERSPEECH 2020 defines a shared task through which different approaches to the automated recognition of Alzheimer's dementia based on spontaneous speech can be compared. ADReSS provides researchers with a benchmark speech dataset which has been acoustically pre-processed and balanced in terms of age and gender, defining two cognitive assessment tasks, namely: the Alzheimer's speech classification task and the neuropsychological score regression task. In the Alzheimer's speech classification task, ADReSS challenge participants create models for classifying speech as dementia or healthy control speech. In the the neuropsychological score regression task, participants create models to predict mini-mental state examination scores. This paper describes the ADReSS Challenge in detail and presents a baseline for both tasks, including a feature extraction procedure and results for a classification and a regression model. ADReSS aims to provide the speech and language Alzheimer's research community with a platform for comprehensive methodological comparisons. This will contribute to addressing the lack of standardisation that currently affects the field and shed light on avenues for future research and clinical applicability.
Emotion Recognition in Low-Resource Settings: An Evaluation of Automatic Feature Selection Methods
Aug 28, 2019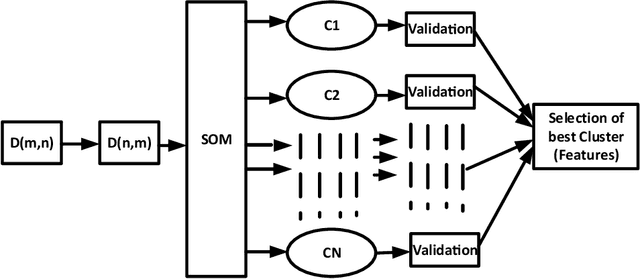

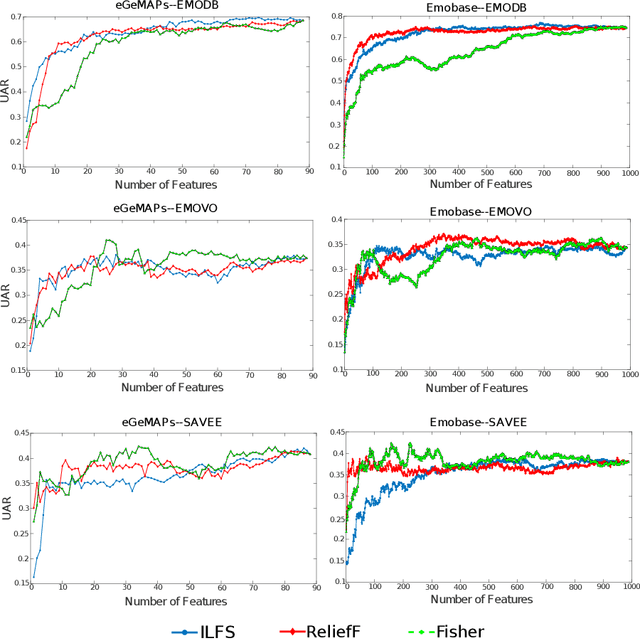
Research in automatic emotion recognition has seldom addressed the issue of computational resource utilization. With the advent of ambient technology, which employs a variety of low-power, resource constrained devices, this issue is increasingly gaining interest. This is especially the case in the context of health and elderly care technologies, where interventions aim at maintaining the user's independence as unobtrusively as possible. In this context, efforts are being made to model human social signals such as emotions, which can aid health monitoring. This paper focuses on emotion recognition from speech data. In order to minimize the system's memory and computational needs, a minimum number of features should be extracted for use in machine learning models. A number of feature set reduction methods exist which seek to find minimal sets of relevant features. We evaluate three different state of the art feature selection methods: Infinite Latent Feature Selection (ILFS), ReliefF and Fisher (generalized Fisher score), and compare them to our recently proposed feature selection method named 'Active Feature Selection' (AFS). The evaluation is performed on three emotion recognition data sets (EmoDB, SAVEE and EMOVO) using two standard speech feature sets (i.e. eGeMAPs and emobase). The results show that similar or better accuracy can be achieved using subsets of features substantially smaller than entire feature set. A machine learning model trained on a smaller feature set will reduce the memory and computational resources of an emotion recognition system which can result in lowering the barriers for use of health monitoring technology.
Proceedings of eNTERFACE 2015 Workshop on Intelligent Interfaces
Jan 19, 2018
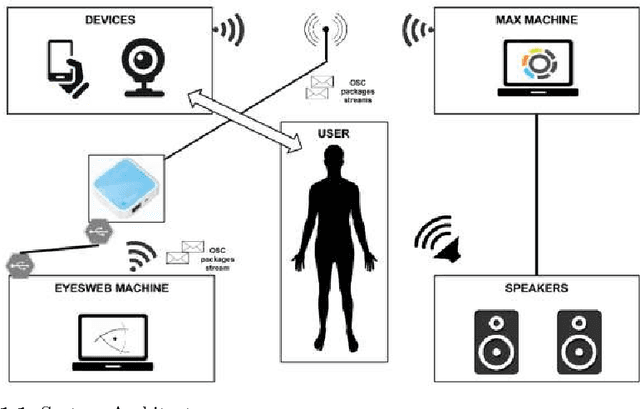
The 11th Summer Workshop on Multimodal Interfaces eNTERFACE 2015 was hosted by the Numediart Institute of Creative Technologies of the University of Mons from August 10th to September 2015. During the four weeks, students and researchers from all over the world came together in the Numediart Institute of the University of Mons to work on eight selected projects structured around intelligent interfaces. Eight projects were selected and their reports are shown here.