 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeak Supervision for Label Efficient Visual Bug Detection
Sep 20, 2023



As video games evolve into expansive, detailed worlds, visual quality becomes essential, yet increasingly challenging. Traditional testing methods, limited by resources, face difficulties in addressing the plethora of potential bugs. Machine learning offers scalable solutions; however, heavy reliance on large labeled datasets remains a constraint. Addressing this challenge, we propose a novel method, utilizing unlabeled gameplay and domain-specific augmentations to generate datasets & self-supervised objectives used during pre-training or multi-task settings for downstream visual bug detection. Our methodology uses weak-supervision to scale datasets for the crafted objectives and facilitates both autonomous and interactive weak-supervision, incorporating unsupervised clustering and/or an interactive approach based on text and geometric prompts. We demonstrate on first-person player clipping/collision bugs (FPPC) within the expansive Giantmap game world, that our approach is very effective, improving over a strong supervised baseline in a practical, very low-prevalence, low data regime (0.336 $\rightarrow$ 0.550 F1 score). With just 5 labeled "good" exemplars (i.e., 0 bugs), our self-supervised objective alone captures enough signal to outperform the low-labeled supervised settings. Building on large-pretrained vision models, our approach is adaptable across various visual bugs. Our results suggest applicability in curating datasets for broader image and video tasks within video games beyond visual bugs.
On the Surprising Effectiveness of Transformers in Low-Labeled Video Recognition
Sep 15, 2022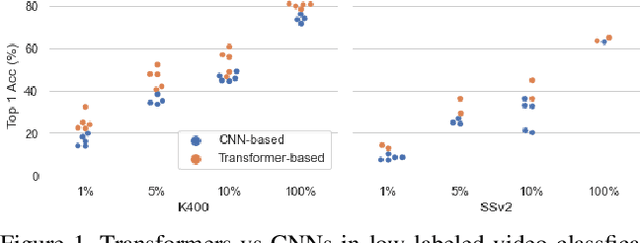
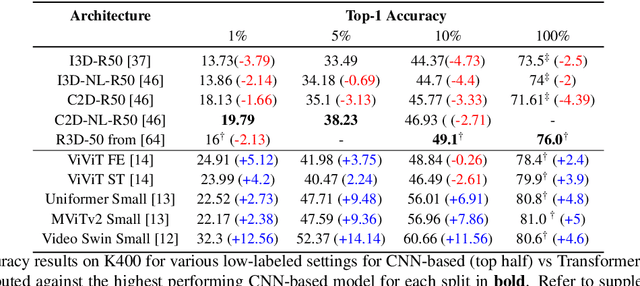
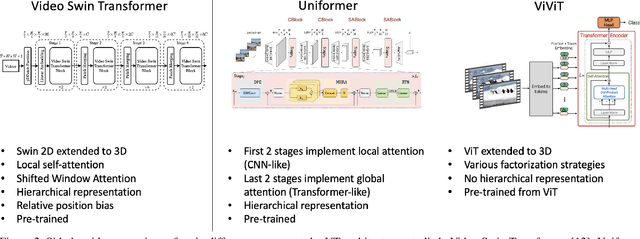

Recently vision transformers have been shown to be competitive with convolution-based methods (CNNs) broadly across multiple vision tasks. The less restrictive inductive bias of transformers endows greater representational capacity in comparison with CNNs. However, in the image classification setting this flexibility comes with a trade-off with respect to sample efficiency, where transformers require ImageNet-scale training. This notion has carried over to video where transformers have not yet been explored for video classification in the low-labeled or semi-supervised settings. Our work empirically explores the low data regime for video classification and discovers that, surprisingly, transformers perform extremely well in the low-labeled video setting compared to CNNs. We specifically evaluate video vision transformers across two contrasting video datasets (Kinetics-400 and SomethingSomething-V2) and perform thorough analysis and ablation studies to explain this observation using the predominant features of video transformer architectures. We even show that using just the labeled data, transformers significantly outperform complex semi-supervised CNN methods that leverage large-scale unlabeled data as well. Our experiments inform our recommendation that semi-supervised learning video work should consider the use of video transformers in the future.