 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing of Term Clustering Frameworks for Modular Ontology Learning
Jan 25, 2019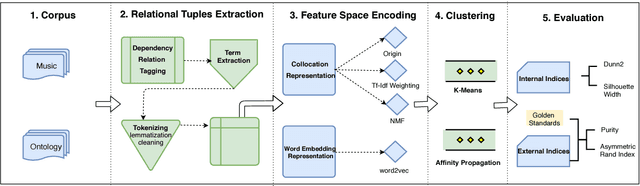
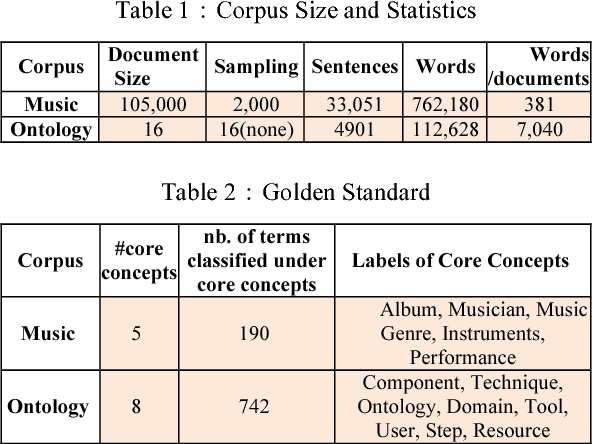
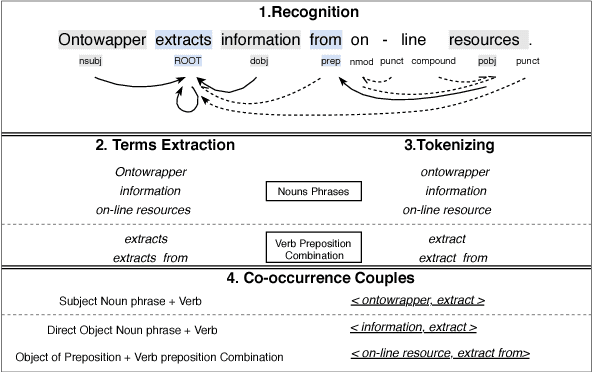
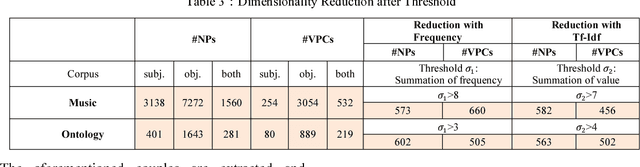
This paper aims to use term clustering to build a modular ontology according to core ontology from domain-specific text. The acquisition of semantic knowledge focuses on noun phrase appearing with the same syntactic roles in relation to a verb or its preposition combination in a sentence. The construction of this co-occurrence matrix from context helps to build feature space of noun phrases, which is then transformed to several encoding representations including feature selection and dimensionality reduction. In addition, the content has also been presented with the construction of word vectors. These representations are clustered respectively with K-Means and Affinity Propagation (AP) methods, which differentiate into the term clustering frameworks. Due to the randomness of K-Means, iteration efforts are adopted to find the optimal parameter. The frameworks are evaluated extensively where AP shows dominant effectiveness for co-occurred terms and NMF encoding technique is salient by its promising facilities in feature compression.
Post-Processing of Discovered Association Rules Using Ontologies
Oct 02, 2009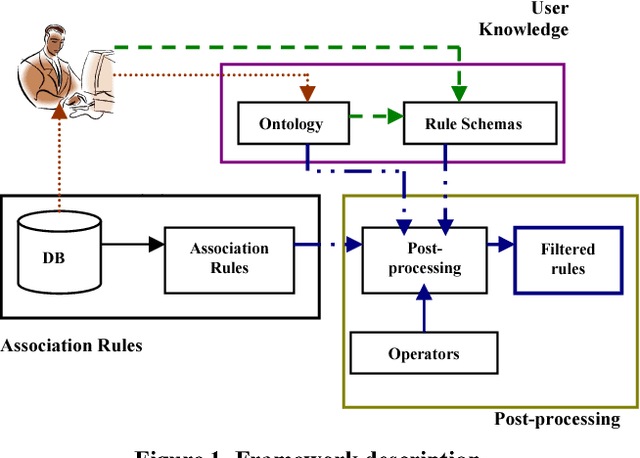


In Data Mining, the usefulness of association rules is strongly limited by the huge amount of delivered rules. In this paper we propose a new approach to prune and filter discovered rules. Using Domain Ontologies, we strengthen the integration of user knowledge in the post-processing task. Furthermore, an interactive and iterative framework is designed to assist the user along the analyzing task. On the one hand, we represent user domain knowledge using a Domain Ontology over database. On the other hand, a novel technique is suggested to prune and to filter discovered rules. The proposed framework was applied successfully over the client database provided by Nantes Habitat.