 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Approximate Temporal Triangle Counting in Streaming with Predictions
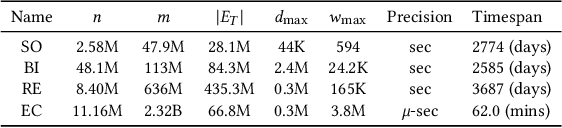
Jun 16, 2025Triangle counting is a fundamental and widely studied problem on static graphs, and recently on temporal graphs, where edges carry information on the timings of the associated events. Streaming processing and resource efficiency are crucial requirements for counting triangles in modern massive temporal graphs, with millions of nodes and up to billions of temporal edges. However, current exact and approximate algorithms are unable to handle large-scale temporal graphs. To fill such a gap, we introduce STEP, a scalable and efficient algorithm to approximate temporal triangle counts from a stream of temporal edges. STEP combines predictions to the number of triangles a temporal edge is involved in, with a simple sampling strategy, leading to scalability, efficiency, and accurate approximation of all eight temporal triangle types simultaneously. We analytically prove that, by using a sublinear amount of memory, STEP obtains unbiased and very accurate estimates. In fact, even noisy predictions can significantly reduce the variance of STEP's estimates. Our extensive experiments on massive temporal graphs with up to billions of edges demonstrate that STEP outputs high-quality estimates and is more efficient than state-of-the-art methods.
Scalable Rule Lists Learning with Sampling
Jun 18, 2024



Learning interpretable models has become a major focus of machine learning research, given the increasing prominence of machine learning in socially important decision-making. Among interpretable models, rule lists are among the best-known and easily interpretable ones. However, finding optimal rule lists is computationally challenging, and current approaches are impractical for large datasets. We present a novel and scalable approach to learn nearly optimal rule lists from large datasets. Our algorithm uses sampling to efficiently obtain an approximation of the optimal rule list with rigorous guarantees on the quality of the approximation. In particular, our algorithm guarantees to find a rule list with accuracy very close to the optimal rule list when a rule list with high accuracy exists. Our algorithm builds on the VC-dimension of rule lists, for which we prove novel upper and lower bounds. Our experimental evaluation on large datasets shows that our algorithm identifies nearly optimal rule lists with a speed-up up to two orders of magnitude over state-of-the-art exact approaches. Moreover, our algorithm is as fast as, and sometimes faster than, recent heuristic approaches, while reporting higher quality rule lists. In addition, the rules reported by our algorithm are more similar to the rules in the optimal rule list than the rules from heuristic approaches.
Efficient Discovery of Significant Patterns with Few-Shot Resampling
Jun 17, 2024



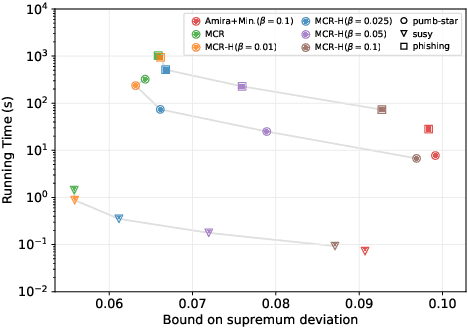
Significant pattern mining is a fundamental task in mining transactional data, requiring to identify patterns significantly associated with the value of a given feature, the target. In several applications, such as biomedicine, basket market analysis, and social networks, the goal is to discover patterns whose association with the target is defined with respect to an underlying population, or process, of which the dataset represents only a collection of observations, or samples. A natural way to capture the association of a pattern with the target is to consider its statistical significance, assessing its deviation from the (null) hypothesis of independence between the pattern and the target. While several algorithms have been proposed to find statistically significant patterns, it remains a computationally demanding task, and for complex patterns such as subgroups, no efficient solution exists. We present FSR, an efficient algorithm to identify statistically significant patterns with rigorous guarantees on the probability of false discoveries. FSR builds on a novel general framework for mining significant patterns that captures some of the most commonly considered patterns, including itemsets, sequential patterns, and subgroups. FSR uses a small number of resampled datasets, obtained by assigning i.i.d. labels to each transaction, to rigorously bound the supremum deviation of a quality statistic measuring the significance of patterns. FSR builds on novel tight bounds on the supremum deviation that require to mine a small number of resampled datasets, while providing a high effectiveness in discovering significant patterns. As a test case, we consider significant subgroup mining, and our evaluation on several real datasets shows that FSR is effective in discovering significant subgroups, while requiring a small number of resampled datasets.
SizeShiftReg: a Regularization Method for Improving Size-Generalization in Graph Neural Networks
Jul 16, 2022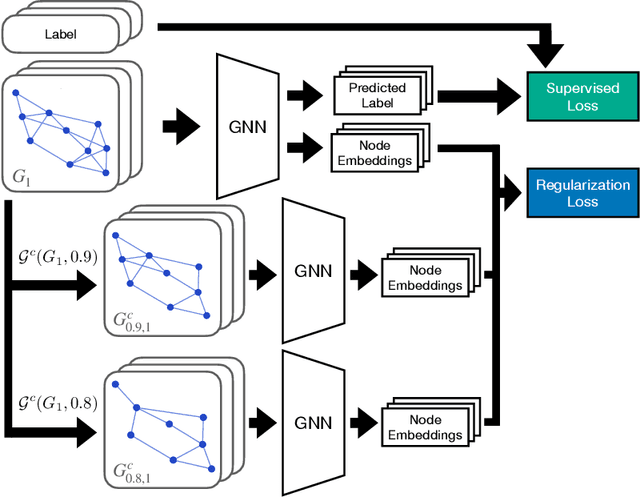

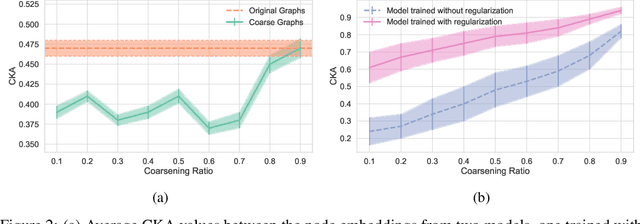

In the past few years, graph neural networks (GNNs) have become the de facto model of choice for graph classification. While, from the theoretical viewpoint, most GNNs can operate on graphs of any size, it is empirically observed that their classification performance degrades when they are applied on graphs with sizes that differ from those in the training data. Previous works have tried to tackle this issue in graph classification by providing the model with inductive biases derived from assumptions on the generative process of the graphs, or by requiring access to graphs from the test domain. The first strategy is tied to the use of ad-hoc models and to the quality of the assumptions made on the generative process, leaving open the question of how to improve the performance of generic GNN models in general settings. On the other hand, the second strategy can be applied to any GNN, but requires access to information that is not always easy to obtain. In this work we consider the scenario in which we only have access to the training data, and we propose a regularization strategy that can be applied to any GNN to improve its generalization capabilities from smaller to larger graphs without requiring access to the test data. Our regularization is based on the idea of simulating a shift in the size of the training graphs using coarsening techniques, and enforcing the model to be robust to such a shift. Experimental results on standard datasets show that popular GNN models, trained on the 50% smallest graphs in the dataset and tested on the 10% largest graphs, obtain performance improvements of up to 30% when trained with our regularization strategy.
Graph Representation Learning for Multi-Task Settings: a Meta-Learning Approach
Jan 10, 2022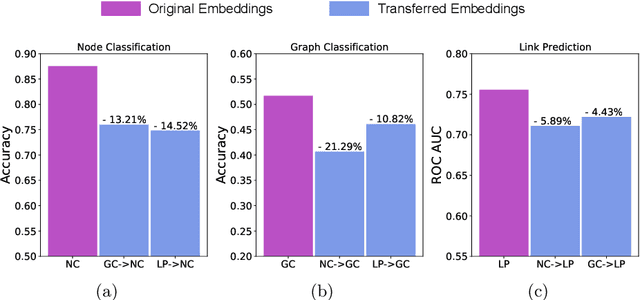
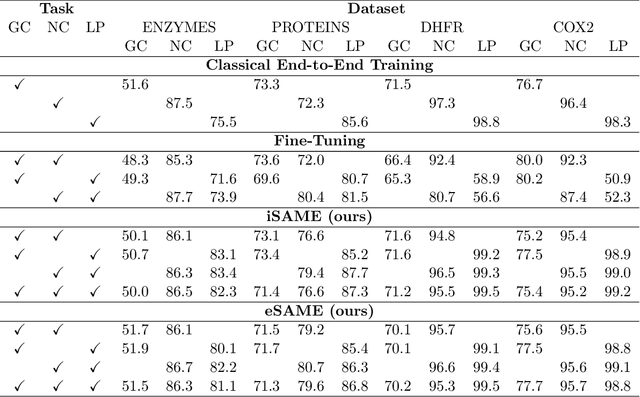
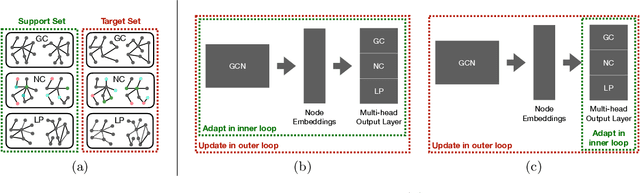
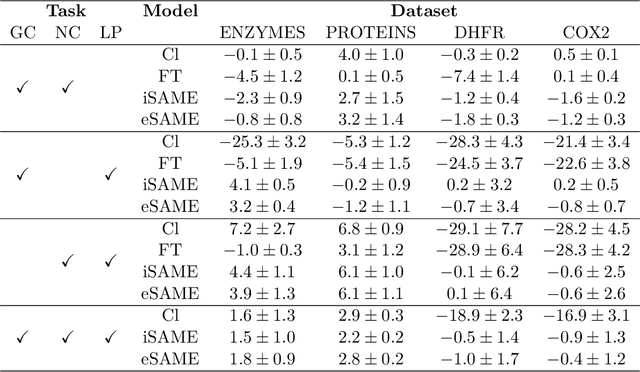
Graph Neural Networks (GNNs) have become the state-of-the-art method for many applications on graph structured data. GNNs are a framework for graph representation learning, where a model learns to generate low dimensional node embeddings that encapsulate structural and feature-related information. GNNs are usually trained in an end-to-end fashion, leading to highly specialized node embeddings. While this approach achieves great results in the single-task setting, generating node embeddings that can be used to perform multiple tasks (with performance comparable to single-task models) is still an open problem. We propose a novel training strategy for graph representation learning, based on meta-learning, which allows the training of a GNN model capable of producing multi-task node embeddings. Our method avoids the difficulties arising when learning to perform multiple tasks concurrently by, instead, learning to quickly (i.e. with a few steps of gradient descent) adapt to multiple tasks singularly. We show that the embeddings produced by a model trained with our method can be used to perform multiple tasks with comparable or, surprisingly, even higher performance than both single-task and multi-task end-to-end models.
odeN: Simultaneous Approximation of Multiple Motif Counts in Large Temporal Networks
Aug 19, 2021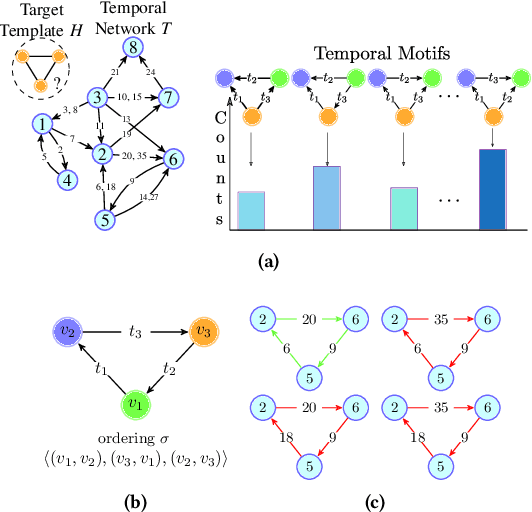
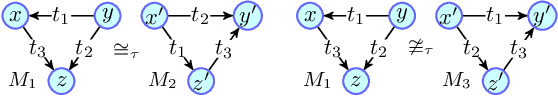
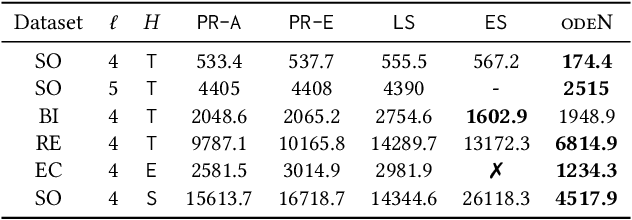
Counting the number of occurrences of small connected subgraphs, called temporal motifs, has become a fundamental primitive for the analysis of temporal networks, whose edges are annotated with the time of the event they represent. One of the main complications in studying temporal motifs is the large number of motifs that can be built even with a limited number of vertices or edges. As a consequence, since in many applications motifs are employed for exploratory analyses, the user needs to iteratively select and analyze several motifs that represent different aspects of the network, resulting in an inefficient, time-consuming process. This problem is exacerbated in large networks, where the analysis of even a single motif is computationally demanding. As a solution, in this work we propose and study the problem of simultaneously counting the number of occurrences of multiple temporal motifs, all corresponding to the same (static) topology (e.g., a triangle). Given that for large temporal networks computing the exact counts is unfeasible, we propose odeN, a sampling-based algorithm that provides an accurate approximation of all the counts of the motifs. We provide analytical bounds on the number of samples required by odeN to compute rigorous, probabilistic, relative approximations. Our extensive experimental evaluation shows that odeN enables the approximation of the counts of motifs in temporal networks in a fraction of the time needed by state-of-the-art methods, and that it also reports more accurate approximations than such methods.
PRESTO: Simple and Scalable Sampling Techniques for the Rigorous Approximation of Temporal Motif Counts
Jan 18, 2021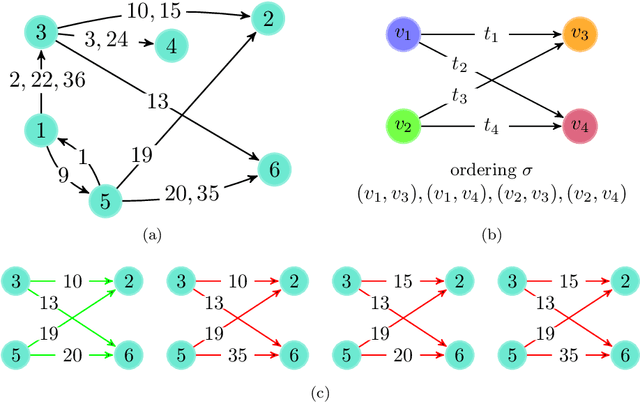

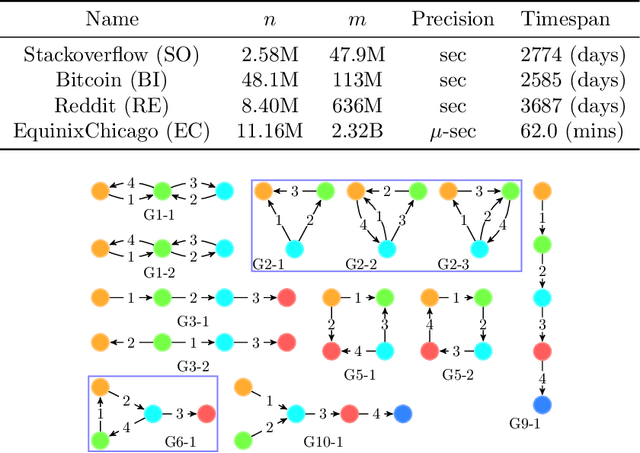
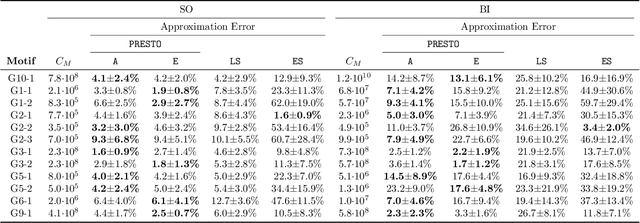
The identification and counting of small graph patterns, called network motifs, is a fundamental primitive in the analysis of networks, with application in various domains, from social networks to neuroscience. Several techniques have been designed to count the occurrences of motifs in static networks, with recent work focusing on the computational challenges provided by large networks. Modern networked datasets contain rich information, such as the time at which the events modeled by the networks edges happened, which can provide useful insights into the process modeled by the network. The analysis of motifs in temporal networks, called temporal motifs, is becoming an important component in the analysis of modern networked datasets. Several methods have been recently designed to count the number of instances of temporal motifs in temporal networks, which is even more challenging than its counterpart for static networks. Such methods are either exact, and not applicable to large networks, or approximate, but provide only weak guarantees on the estimates they produce and do not scale to very large networks. In this work we present an efficient and scalable algorithm to obtain rigorous approximations of the count of temporal motifs. Our algorithm is based on a simple but effective sampling approach, which renders our algorithm practical for very large datasets. Our extensive experimental evaluation shows that our algorithm provides estimates of temporal motif counts which are more accurate than the state-of-the-art sampling algorithms, with significantly lower running time than exact approaches, enabling the study of temporal motifs, of size larger than the ones considered in previous works, on billion edges networks.
A Meta-Learning Approach for Graph Representation Learning in Multi-Task Settings
Dec 12, 2020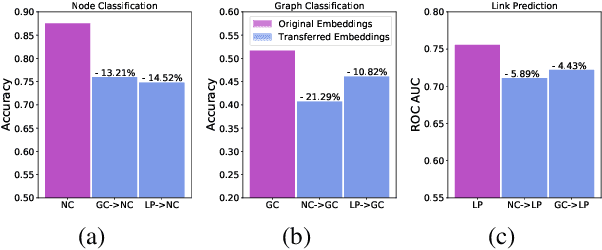
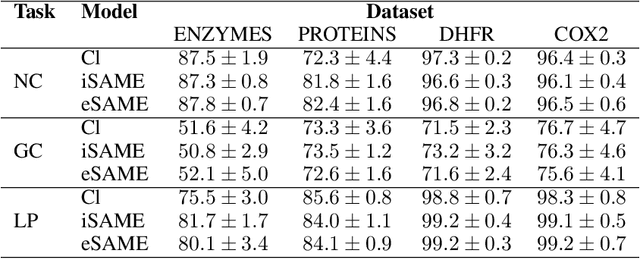
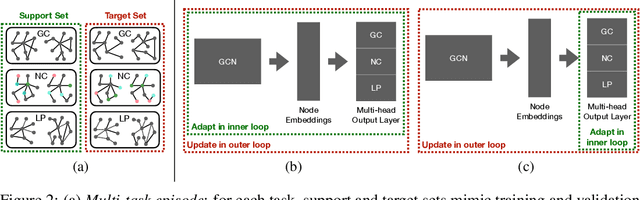
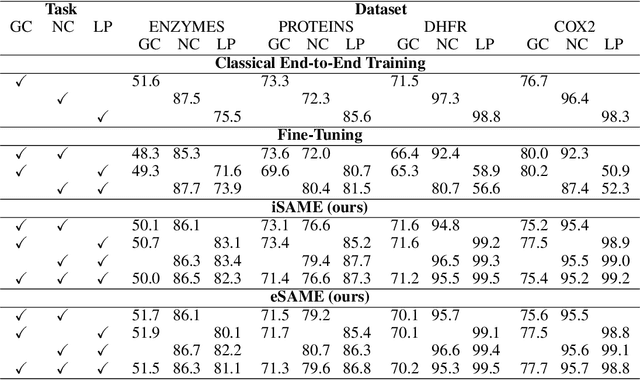
Graph Neural Networks (GNNs) are a framework for graph representation learning, where a model learns to generate low dimensional node embeddings that encapsulate structural and feature-related information. GNNs are usually trained in an end-to-end fashion, leading to highly specialized node embeddings. However, generating node embeddings that can be used to perform multiple tasks (with performance comparable to single-task models) is an open problem. We propose a novel meta-learning strategy capable of producing multi-task node embeddings. Our method avoids the difficulties arising when learning to perform multiple tasks concurrently by, instead, learning to quickly (i.e. with a few steps of gradient descent) adapt to multiple tasks singularly. We show that the embeddings produced by our method can be used to perform multiple tasks with comparable or higher performance than classically trained models. Our method is model-agnostic and task-agnostic, thus applicable to a wide variety of multi-task domains.
MCRapper: Monte-Carlo Rademacher Averages for Poset Families and Approximate Pattern Mining
Jun 16, 2020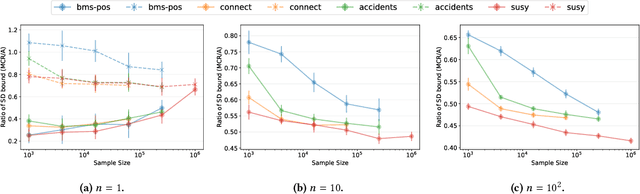
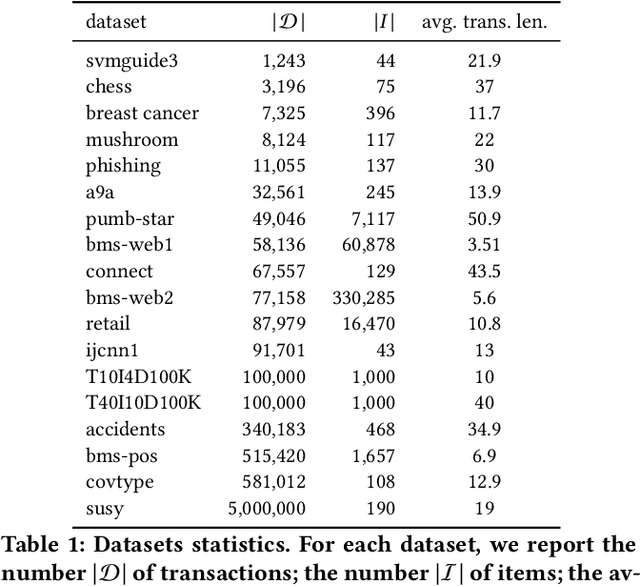
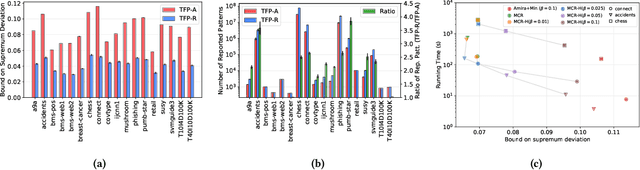
We present MCRapper, an algorithm for efficient computation of Monte-Carlo Empirical Rademacher Averages (MCERA) for families of functions exhibiting poset (e.g., lattice) structure, such as those that arise in many pattern mining tasks. The MCERA allows us to compute upper bounds to the maximum deviation of sample means from their expectations, thus it can be used to find both statistically-significant functions (i.e., patterns) when the available data is seen as a sample from an unknown distribution, and approximations of collections of high-expectation functions (e.g., frequent patterns) when the available data is a small sample from a large dataset. This feature is a strong improvement over previously proposed solutions that could only achieve one of the two. MCRapper uses upper bounds to the discrepancy of the functions to efficiently explore and prune the search space, a technique borrowed from pattern mining itself. To show the practical use of MCRapper, we employ it to develop an algorithm TFP-R for the task of True Frequent Pattern (TFP) mining. TFP-R gives guarantees on the probability of including any false positives (precision) and exhibits higher statistical power (recall) than existing methods offering the same guarantees. We evaluate MCRapper and TFP-R and show that they outperform the state-of-the-art for their respective tasks.
Attention-Based Deep Learning Framework for Human Activity Recognition with User Adaptation
Jun 06, 2020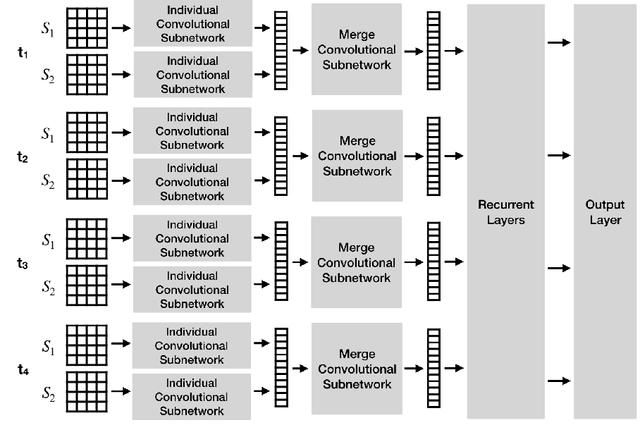

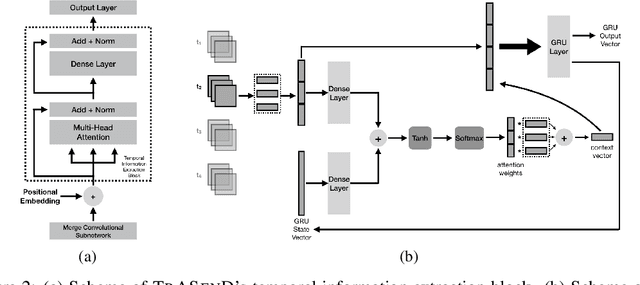
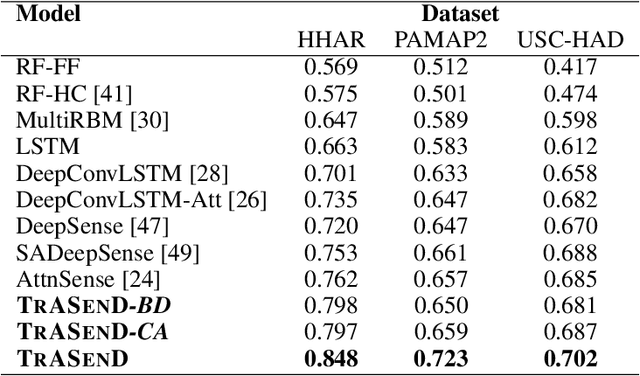
Sensor-based human activity recognition (HAR) requires to predict the action of a person based on sensor-generated time series data. HAR has attracted major interest in the past few years, thanks to the large number of applications enabled by modern ubiquitous computing devices. While several techniques based on hand-crafted feature engineering have been proposed, the current state-of-the-art is represented by deep learning architectures that automatically obtain high level representations and that use recurrent neural networks (RNNs) to extract temporal dependencies in the input. RNNs have several limitations, in particular in dealing with long-term dependencies. We propose a novel deep learning framework, \algname, based on a purely attention-based mechanism, that overcomes the limitations of the state-of-the-art. We show that our proposed attention-based architecture is considerably more powerful than previous approaches, with an average increment, of more than $7\%$ on the F1 score over the previous best performing model. Furthermore, we consider the problem of personalizing HAR deep learning models, which is of great importance in several applications. We propose a simple and effective transfer-learning based strategy to adapt a model to a specific user, providing an average increment of $6\%$ on the F1 score on the predictions for that user. Our extensive experimental evaluation proves the significantly superior capabilities of our proposed framework over the current state-of-the-art and the effectiveness of our user adaptation technique.