 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJust DIAL: DomaIn Alignment Layers for Unsupervised Domain Adaptation
Apr 27, 2017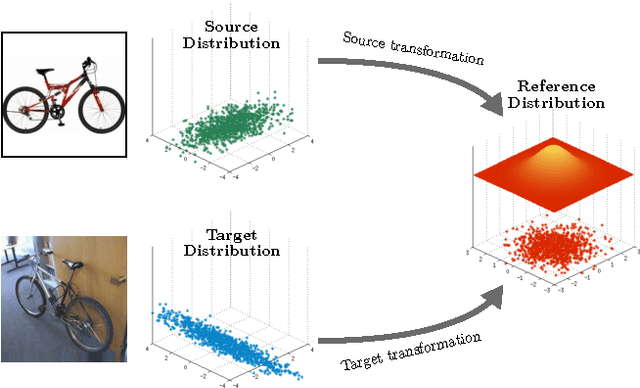
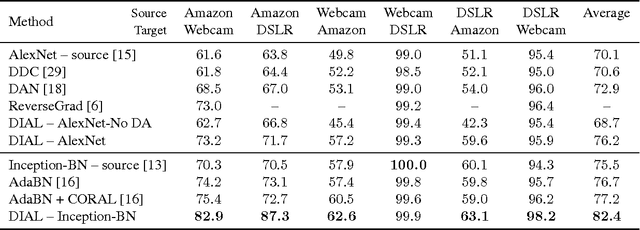
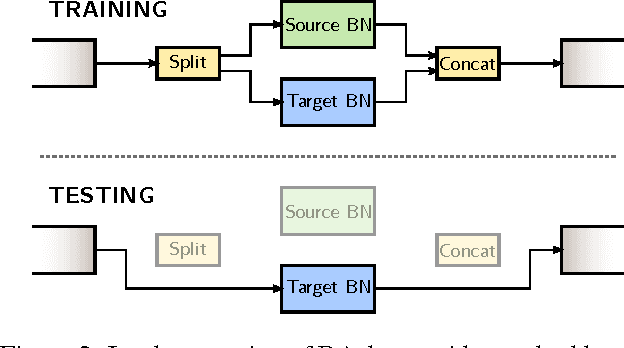
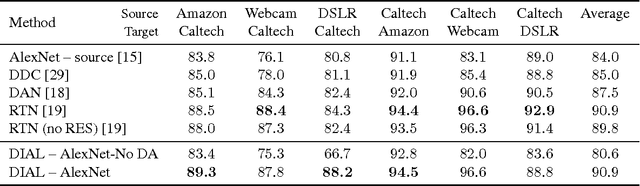
The empirical fact that classifiers, trained on given data collections, perform poorly when tested on data acquired in different settings is theoretically explained in domain adaptation through a shift among distributions of the source and target domains. Alleviating the domain shift problem, especially in the challenging setting where no labeled data are available for the target domain, is paramount for having visual recognition systems working in the wild. As the problem stems from a shift among distributions, intuitively one should try to align them. In the literature, this has resulted in a stream of works attempting to align the feature representations learned from the source and target domains. Here we take a different route. Rather than introducing regularization terms aiming to promote the alignment of the two representations, we act at the distribution level through the introduction of \emph{DomaIn Alignment Layers} (\DIAL), able to match the observed source and target data distributions to a reference one. Thorough experiments on three different public benchmarks we confirm the power of our approach.
A deep representation for depth images from synthetic data
Sep 30, 2016


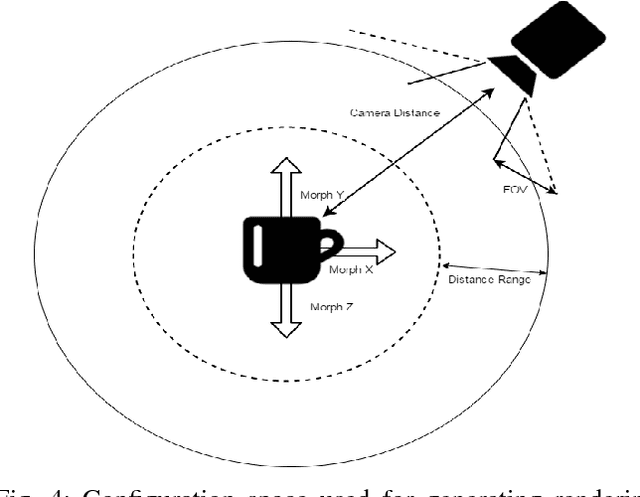
Convolutional Neural Networks (CNNs) trained on large scale RGB databases have become the secret sauce in the majority of recent approaches for object categorization from RGB-D data. Thanks to colorization techniques, these methods exploit the filters learned from 2D images to extract meaningful representations in 2.5D. Still, the perceptual signature of these two kind of images is very different, with the first usually strongly characterized by textures, and the second mostly by silhouettes of objects. Ideally, one would like to have two CNNs, one for RGB and one for depth, each trained on a suitable data collection, able to capture the perceptual properties of each channel for the task at hand. This has not been possible so far, due to the lack of a suitable depth database. This paper addresses this issue, proposing to opt for synthetically generated images rather than collecting by hand a 2.5D large scale database. While being clearly a proxy for real data, synthetic images allow to trade quality for quantity, making it possible to generate a virtually infinite amount of data. We show that the filters learned from such data collection, using the very same architecture typically used on visual data, learns very different filters, resulting in depth features (a) able to better characterize the different facets of depth images, and (b) complementary with respect to those derived from CNNs pre-trained on 2D datasets. Experiments on two publicly available databases show the power of our approach.
When Naïve Bayes Nearest Neighbours Meet Convolutional Neural Networks
Nov 17, 2015
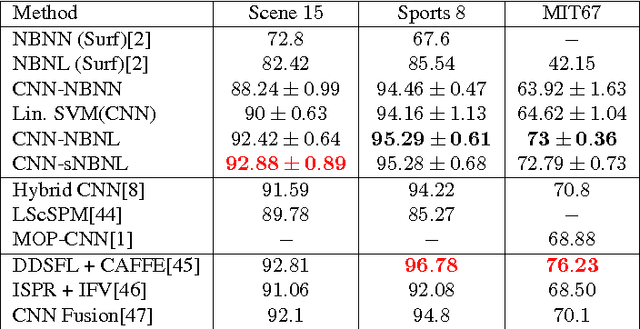

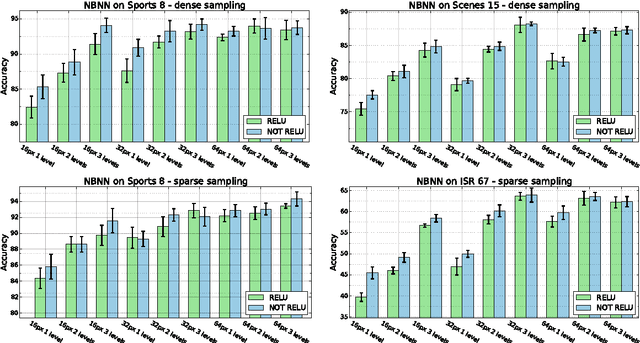
Since Convolutional Neural Networks (CNNs) have become the leading learning paradigm in visual recognition, Naive Bayes Nearest Neighbour (NBNN)-based classifiers have lost momentum in the community. This is because (1) such algorithms cannot use CNN activations as input features; (2) they cannot be used as final layer of CNN architectures for end-to-end training , and (3) they are generally not scalable and hence cannot handle big data. This paper proposes a framework that addresses all these issues, thus bringing back NBNNs on the map. We solve the first by extracting CNN activations from local patches at multiple scale levels, similarly to [1]. We address simultaneously the second and third by proposing a scalable version of Naive Bayes Non-linear Learning (NBNL, [2]). Results obtained using pre-trained CNNs on standard scene and domain adaptation databases show the strength of our approach, opening a new season for NBNNs.