 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMASAR: Motion-Appearance Synergy Refinement for Joint Detection and Trajectory Forecasting
Feb 13, 2026Classical autonomous driving systems connect perception and prediction modules via hand-crafted bounding-box interfaces, limiting information flow and propagating errors to downstream tasks. Recent research aims to develop end-to-end models that jointly address perception and prediction; however, they often fail to fully exploit the synergy between appearance and motion cues, relying mainly on short-term visual features. We follow the idea of "looking backward to look forward", and propose MASAR, a novel fully differentiable framework for joint 3D detection and trajectory forecasting compatible with any transformer-based 3D detector. MASAR employs an object-centric spatio-temporal mechanism that jointly encodes appearance and motion features. By predicting past trajectories and refining them using guidance from appearance cues, MASAR captures long-term temporal dependencies that enhance future trajectory forecasting. Experiments conducted on the nuScenes dataset demonstrate MASAR's effectiveness, showing improvements of over 20% in minADE and minFDE while maintaining robust detection performance. Code and models are available at https://github.com/aminmed/MASAR.
The EuroCity Persons Dataset: A Novel Benchmark for Object Detection
Jun 05, 2018
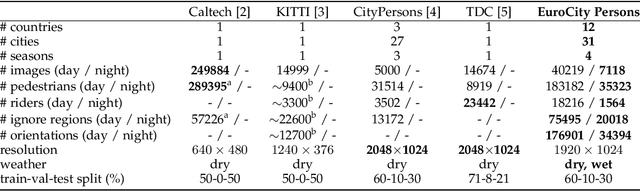

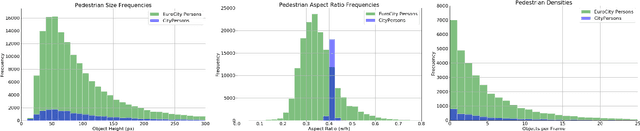
Big data has had a great share in the success of deep learning in computer vision. Recent works suggest that there is significant further potential to increase object detection performance by utilizing even bigger datasets. In this paper, we introduce the EuroCity Persons dataset, which provides a large number of highly diverse, accurate and detailed annotations of pedestrians, cyclists and other riders in urban traffic scenes. The images for this dataset were collected on-board a moving vehicle in 31 cities of 12 European countries. With over 238200 person instances manually labeled in over 47300 images, EuroCity Persons is nearly one order of magnitude larger than person datasets used previously for benchmarking. The dataset furthermore contains a large number of person orientation annotations (over 211200). We optimize four state-of-the-art deep learning approaches (Faster R-CNN, R-FCN, SSD and YOLOv3) to serve as baselines for the new object detection benchmark. In experiments with previous datasets we analyze the generalization capabilities of these detectors when trained with the new dataset. We furthermore study the effect of the training set size, the dataset diversity (day- vs. night-time, geographical region), the dataset detail (i.e. availability of object orientation information) and the annotation quality on the detector performance. Finally, we analyze error sources and discuss the road ahead.