 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Information Asymmetry in Competitive Multi-Agent Reinforcement Learning: Convergence and Optimality
Oct 21, 2020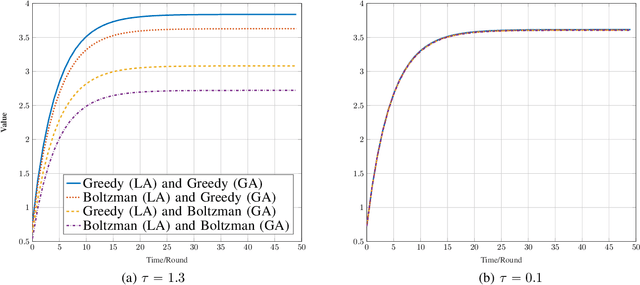
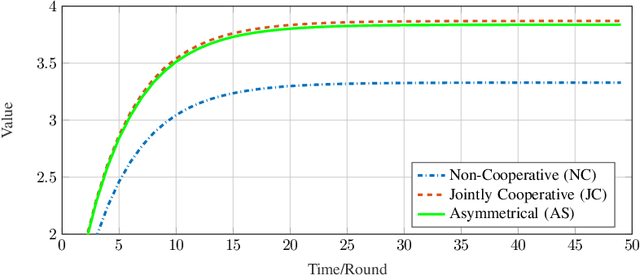
In this work, we study the system of interacting non-cooperative two Q-learning agents, where one agent has the privilege of observing the other's actions. We show that this information asymmetry can lead to a stable outcome of population learning, which does not occur in an environment of general independent learners. Furthermore, we discuss the resulted post-learning policies, show that they are almost optimal in the underlying game sense, and provide numerical hints of almost welfare-optimal of the resulted policies.
Coordinated Online Learning for Multi-Agent Systems with Coupled Constraints and Perturbed Utility Observations
Oct 21, 2020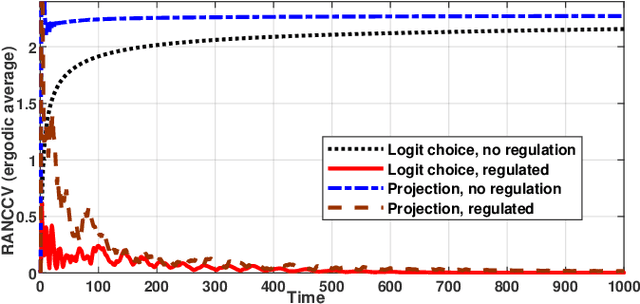
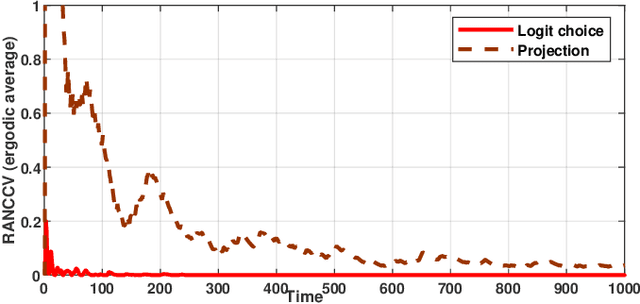
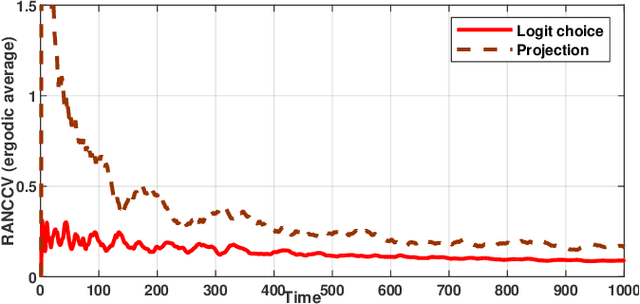
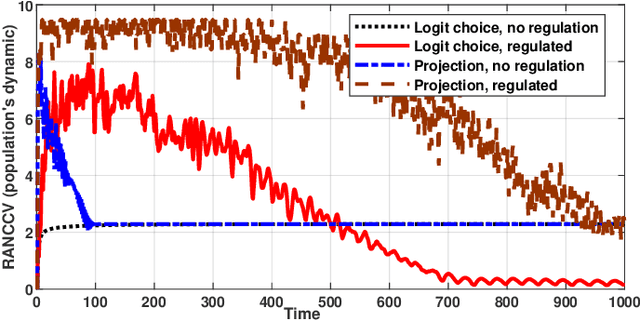
Competitive non-cooperative online decision-making agents whose actions increase congestion of scarce resources constitute a model for widespread modern large-scale applications. To ensure sustainable resource behavior, we introduce a novel method to steer the agents toward a stable population state, fulfilling the given coupled resource constraints. The proposed method is a decentralized resource pricing method based on the resource loads resulting from the augmentation of the game's Lagrangian. Assuming that the online learning agents have only noisy first-order utility feedback, we show that for a polynomially decaying agents' step size/learning rate, the population's dynamic will almost surely converge to generalized Nash equilibrium. A particular consequence of the latter is the fulfillment of resource constraints in the asymptotic limit. Moreover, we investigate the finite-time quality of the proposed algorithm by giving a nonasymptotic time decaying bound for the expected amount of resource constraint violation.
Pricing Mechanism for Resource Sustainability in Competitive Online Learning Multi-Agent Systems
Oct 21, 2019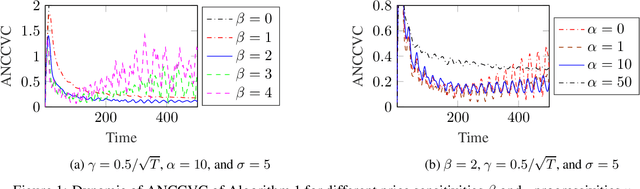
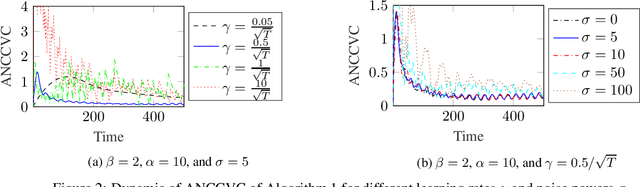
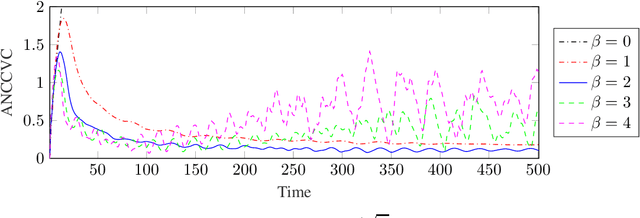
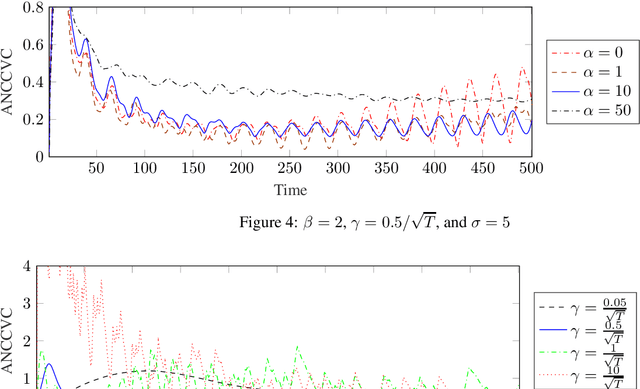
In this paper, we consider the problem of resource congestion control for competing online learning agents. On the basis of non-cooperative game as the model for the interaction between the agents, and the noisy online mirror ascent as the model for rational behavior of the agents, we propose a novel pricing mechanism which gives the agents incentives for sustainable use of the resources. Our mechanism is distributed and resource-centric, in the sense that it is done by the resources themselves and not by a centralized instance, and that it is based rather on the congestion state of the resources than the preferences of the agents. In case that the noise is persistent, and for several choices of the intrinsic parameter of the agents, such as their learning rate, and of the mechanism parameters, such as the learning rate of -, the progressivity of the price-setters, and the extrinsic price sensitivity of the agents, we show that the accumulative violation of the resource constraints of the resulted iterates is sub-linear w.r.t. the time horizon. Moreover, we provide numerical simulations to support our theoretical findings.
Robust Online Learning for Resource Allocation -- Beyond Euclidean Projection and Dynamic Fit
Oct 21, 2019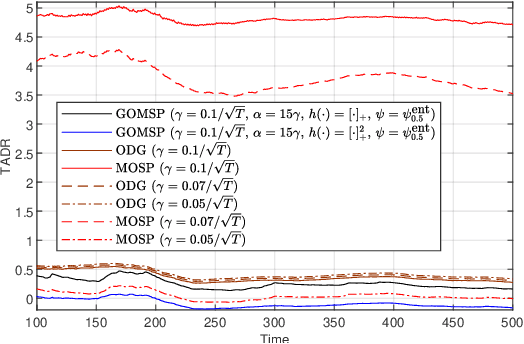
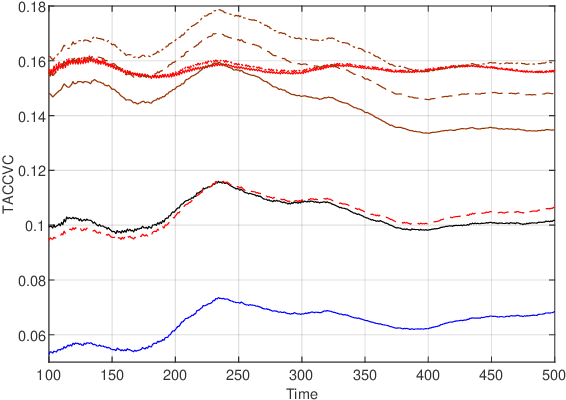
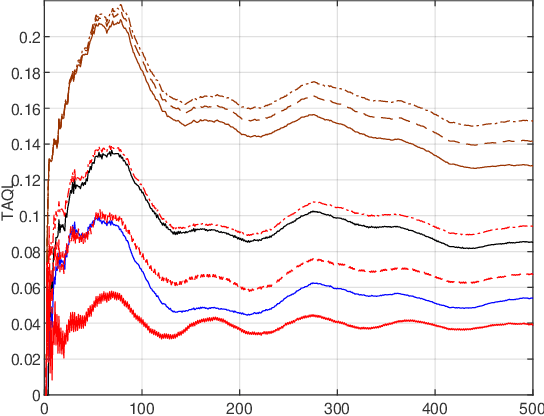
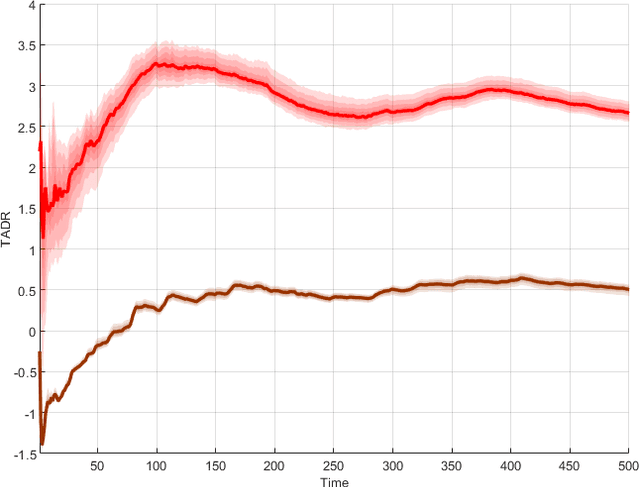
Online-learning literature has focused on designing algorithms that ensure sub-linear growth of the cumulative long-term constraint violations. The drawback of this guarantee is that strictly feasible actions may cancel out constraint violations on other time slots. For this reason, we introduce a new performance measure called $\hCFit$, whose particular instance is the cumulative positive part of the constraint violations. We propose a class of non-causal algorithms for online-decision making, which guarantees, in slowly changing environments, sub-linear growth of this quantity despite noisy first-order feedback. Furthermore, we demonstrate by numerical experiments the performance gain of our method relative to the state of art.
Semi-Decentralized Coordinated Online Learning for Continuous Games with Coupled Constraints via Augmented Lagrangian
Oct 21, 2019We consider a class of concave continuous games in which the corresponding admissible strategy profile of each player underlies affine coupling constraints. We propose a novel algorithm that leads the relevant population dynamic toward Nash equilibrium. This algorithm is based on a mirror ascent algorithm, which suits with the framework of no-regret online learning, and on the augmented Lagrangian method. The decentralization aspect of the algorithm corresponds to the aspects that the iterate of each player requires the local information about how she contributes to the coupling constraints and the price vector broadcasted by a central coordinator. So each player needs not know about the population action. Moreover, no specific control by the central primary coordinator is required. We give a condition on the step sizes and the degree of the augmentation of the Lagrangian, such that the proposed algorithm converges to a generalized Nash equilibrium.