 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Teams Play What? Where? When?
May 28, 2026Large language models (LLMs) remain limited on tasks requiring indirect reasoning, cultural knowledge, and coordinated hypothesis testing. We investigate whether team-based interaction improves LLM performance in What? Where? When? (ChGK), a quiz game designed to reward collective reasoning. We introduce three team strategies: Voting, Silent Team (the captain observes final answers), and Talkative Team (the captain observes both answers and rationales). To minimize data leakage, we evaluate these strategies on a dataset consisting of 572 ChGK questions released in 2025. Using six recent large-scale open models, we show that team-based strategies outperform single-model baselines, yielding gains of up to 20 percentage points in accuracy. The best team achieves 44.23% accuracy, and approaches human team performance on questions with available human statistics. Analysis of inter-model diversity reveals that disagreement strongly predicts lower accuracy, but explanatory communication substantially mitigates performance drops. We further examine captain behavior and find no evidence of self-preference bias; access to peer rationales improves captain judgments. Overall, LLM teams function primarily as answer selection and error-filtering mechanisms rather than generators of novel solutions. Our findings highlight the importance of interaction and suggest adaptive strategies as a promising direction for multi-agent systems.
Improving Small Language Models for Code Generation with Reinforcement Learning from Verification Feedback
May 28, 2026Reinforcement learning with verifiable rewards (RLVR) trains language models using programmatically checkable signals such as unit-test outcomes, enabling direct optimization for functional correctness in code generation. We conduct an empirical study of RLVR for Python code generation on the MBPP benchmark using two small models (Qwen3-0.6B and Llama3.2-1B) with LoRA fine-tuning. Across multiple reward formulations such as: unit-test-only rewards, static-analysis-only shaping via the Ruff linter, and a combined reward, we compare group-based policy optimization variants (GRPO and GSPO) and evaluate both functional correctness and behavioral diagnostics. In our experimental setting, RLVR improves pass@1 on MBPP test by up to 13 percentage points under proposed combined reward configuration. However, we find that reward shaping can induce systematic behavioral shifts: using only static-analysis penalties may bias the policy toward shorter completions that reduce lint errors without reliably improving functional correctness. In contrast, combined rewards mitigate this degeneration and yield more stable trade-offs between correctness and style constraints. Overall, our results highlight that RLVR effectiveness for code generation is highly sensitive to reward design and optimization granularity, and that diagnostics beyond pass@1, including generation length, Ruff severity profiles, and execution error types are useful for identifying failure modes.
I've got the "Answer"! Interpretation of LLMs Hidden States in Question Answering
Jun 04, 2024



Interpretability and explainability of AI are becoming increasingly important in light of the rapid development of large language models (LLMs). This paper investigates the interpretation of LLMs in the context of the knowledge-based question answering. The main hypothesis of the study is that correct and incorrect model behavior can be distinguished at the level of hidden states. The quantized models LLaMA-2-7B-Chat, Mistral-7B, Vicuna-7B and the MuSeRC question-answering dataset are used to test this hypothesis. The results of the analysis support the proposed hypothesis. We also identify the layers which have a negative effect on the model's behavior. As a prospect of practical application of the hypothesis, we propose to train such "weak" layers additionally in order to improve the quality of the task solution.
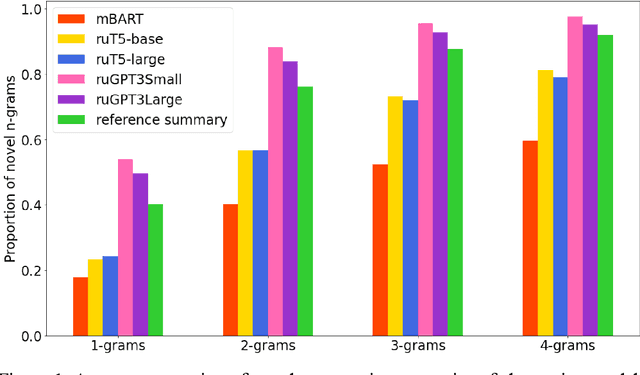
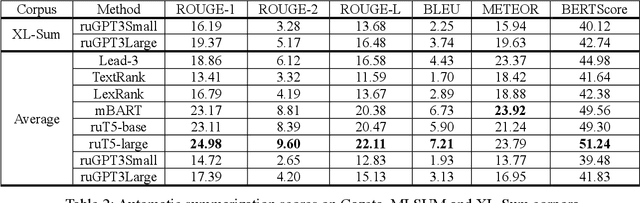
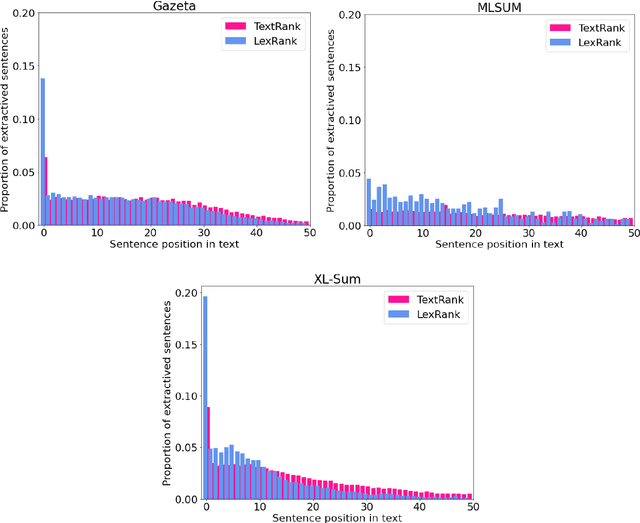
Automatic Summarization of Russian Texts: Comparison of Extractive and Abstractive Methods
Jun 18, 2022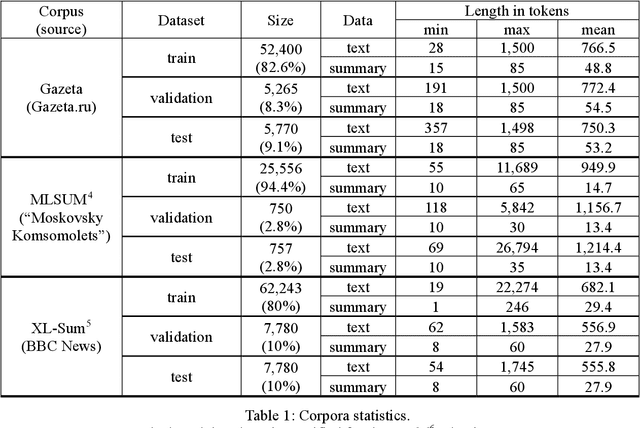
The development of large and super-large language models, such as GPT-3, T5, Switch Transformer, ERNIE, etc., has significantly improved the performance of text generation. One of the important research directions in this area is the generation of texts with arguments. The solution of this problem can be used in business meetings, political debates, dialogue systems, for preparation of student essays. One of the main domains for these applications is the economic sphere. The key problem of the argument text generation for the Russian language is the lack of annotated argumentation corpora. In this paper, we use translated versions of the Argumentative Microtext, Persuasive Essays and UKP Sentential corpora to fine-tune RuBERT model. Further, this model is used to annotate the corpus of economic news by argumentation. Then the annotated corpus is employed to fine-tune the ruGPT-3 model, which generates argument texts. The results show that this approach improves the accuracy of the argument generation by more than 20 percentage points (63.2% vs. 42.5%) compared to the original ruGPT-3 model.
Argumentative Text Generation in Economic Domain
Jun 18, 2022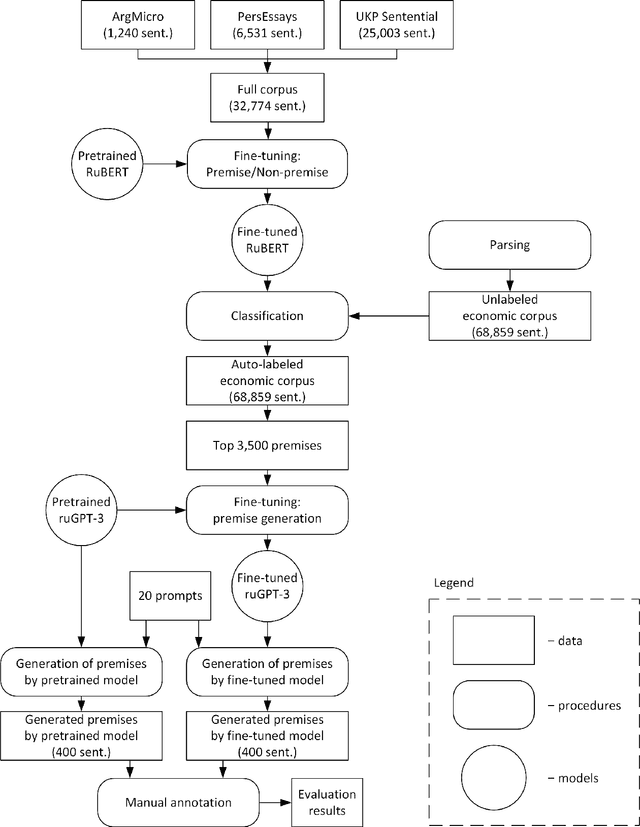



The development of large and super-large language models, such as GPT-3, T5, Switch Transformer, ERNIE, etc., has significantly improved the performance of text generation. One of the important research directions in this area is the generation of texts with arguments. The solution of this problem can be used in business meetings, political debates, dialogue systems, for preparation of student essays. One of the main domains for these applications is the economic sphere. The key problem of the argument text generation for the Russian language is the lack of annotated argumentation corpora. In this paper, we use translated versions of the Argumentative Microtext, Persuasive Essays and UKP Sentential corpora to fine-tune RuBERT model. Further, this model is used to annotate the corpus of economic news by argumentation. Then the annotated corpus is employed to fine-tune the ruGPT-3 model, which generates argument texts. The results show that this approach improves the accuracy of the argument generation by more than 20 percentage points (63.2\% vs. 42.5\%) compared to the original ruGPT-3 model.
RuArg-2022: Argument Mining Evaluation
Jun 18, 2022

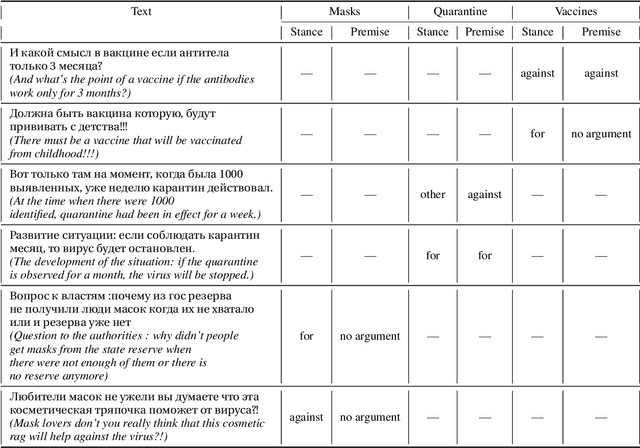

Argumentation analysis is a field of computational linguistics that studies methods for extracting arguments from texts and the relationships between them, as well as building argumentation structure of texts. This paper is a report of the organizers on the first competition of argumentation analysis systems dealing with Russian language texts within the framework of the Dialogue conference. During the competition, the participants were offered two tasks: stance detection and argument classification. A corpus containing 9,550 sentences (comments on social media posts) on three topics related to the COVID-19 pandemic (vaccination, quarantine, and wearing masks) was prepared, annotated, and used for training and testing. The system that won the first place in both tasks used the NLI (Natural Language Inference) variant of the BERT architecture, automatic translation into English to apply a specialized BERT model, retrained on Twitter posts discussing COVID-19, as well as additional masking of target entities. This system showed the following results: for the stance detection task an F1-score of 0.6968, for the argument classification task an F1-score of 0.7404. We hope that the prepared dataset and baselines will help to foster further research on argument mining for the Russian language.
Collocation2Text: Controllable Text Generation from Guide Phrases in Russian
Jun 18, 2022
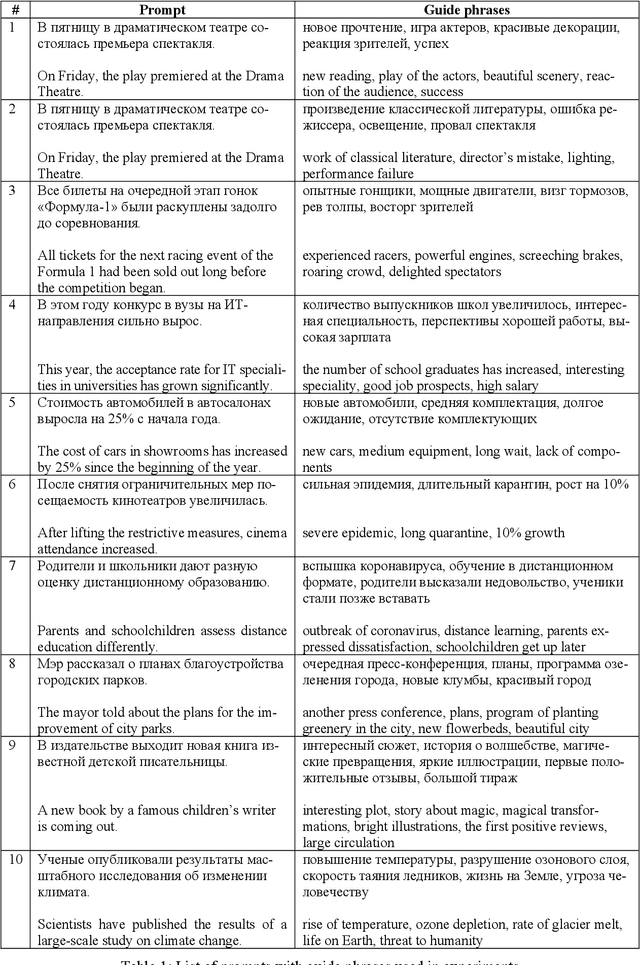
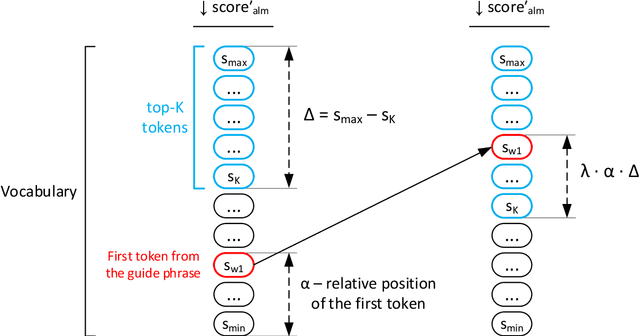
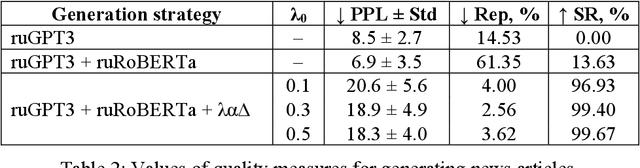
Large pre-trained language models are capable of generating varied and fluent texts. Starting from the prompt, these models generate a narrative that can develop unpredictably. The existing methods of controllable text generation, which guide the narrative in the text in the user-specified direction, require creating a training corpus and an additional time-consuming training procedure. The paper proposes and investigates Collocation2Text, a plug-and-play method for automatic controllable text generation in Russian, which does not require fine-tuning. The method is based on two interacting models: the autoregressive language ruGPT-3 model and the autoencoding language ruRoBERTa model. The idea of the method is to shift the output distribution of the autoregressive model according to the output distribution of the autoencoding model in order to ensure a coherent transition of the narrative in the text towards the guide phrase, which can contain single words or collocations. The autoencoding model, which is able to take into account the left and right contexts of the token, "tells" the autoregressive model which tokens are the most and least logical at the current generation step, increasing or decreasing the probabilities of the corresponding tokens. The experiments on generating news articles using the proposed method showed its effectiveness for automatically generated fluent texts which contain coherent transitions between user-specified phrases.
Does BERT look at sentiment lexicon?
Nov 19, 2021

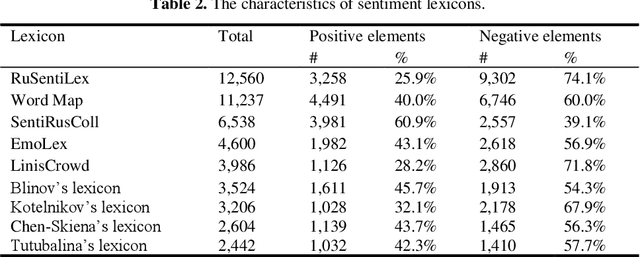
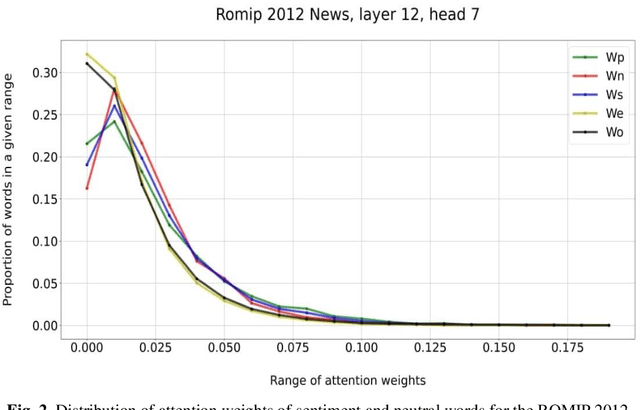
The main approaches to sentiment analysis are rule-based methods and ma-chine learning, in particular, deep neural network models with the Trans-former architecture, including BERT. The performance of neural network models in the tasks of sentiment analysis is superior to the performance of rule-based methods. The reasons for this situation remain unclear due to the poor interpretability of deep neural network models. One of the main keys to understanding the fundamental differences between the two approaches is the analysis of how sentiment lexicon is taken into account in neural network models. To this end, we study the attention weights matrices of the Russian-language RuBERT model. We fine-tune RuBERT on sentiment text corpora and compare the distributions of attention weights for sentiment and neutral lexicons. It turns out that, on average, 3/4 of the heads of various model var-iants statistically pay more attention to the sentiment lexicon compared to the neutral one.
Lexicon-based Methods vs. BERT for Text Sentiment Analysis
Nov 19, 2021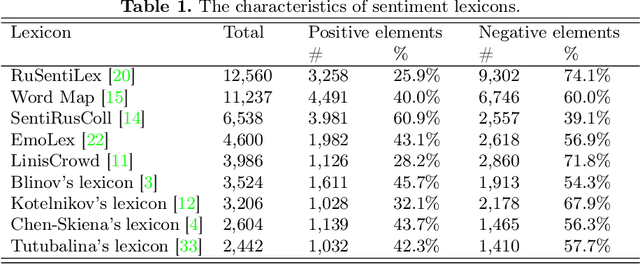
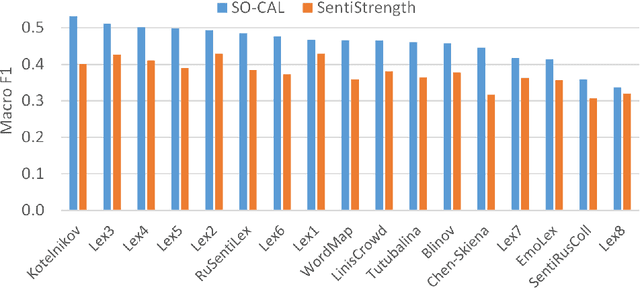
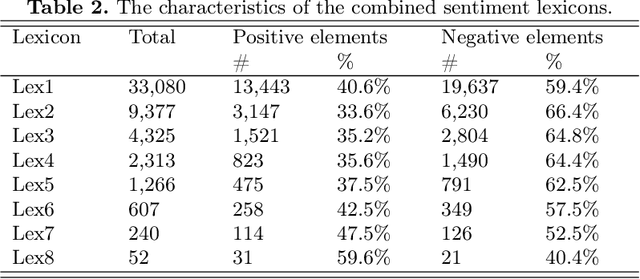
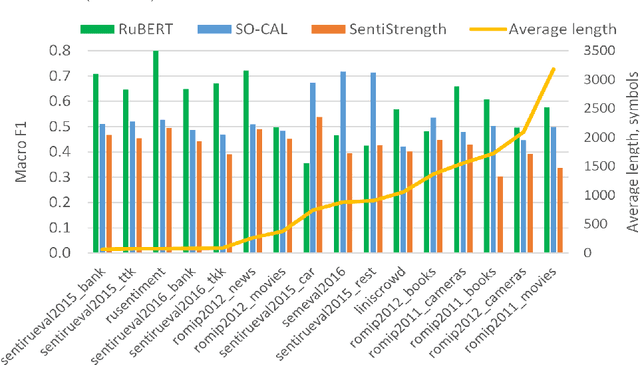
The performance of sentiment analysis methods has greatly increased in recent years. This is due to the use of various models based on the Transformer architecture, in particular BERT. However, deep neural network models are difficult to train and poorly interpretable. An alternative approach is rule-based methods using sentiment lexicons. They are fast, require no training, and are well interpreted. But recently, due to the widespread use of deep learning, lexicon-based methods have receded into the background. The purpose of the article is to study the performance of the SO-CAL and SentiStrength lexicon-based methods, adapted for the Russian language. We have tested these methods, as well as the RuBERT neural network model, on 16 text corpora and have analyzed their results. RuBERT outperforms both lexicon-based methods on average, but SO-CAL surpasses RuBERT for four corpora out of 16.
Traditional Machine Learning and Deep Learning Models for Argumentation Mining in Russian Texts
Jun 28, 2021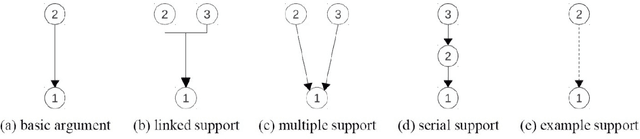
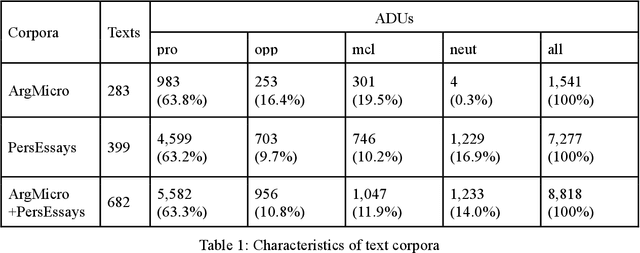
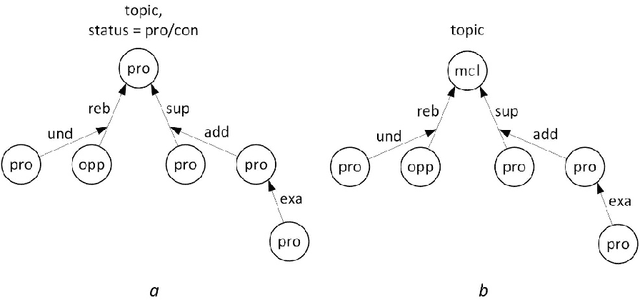
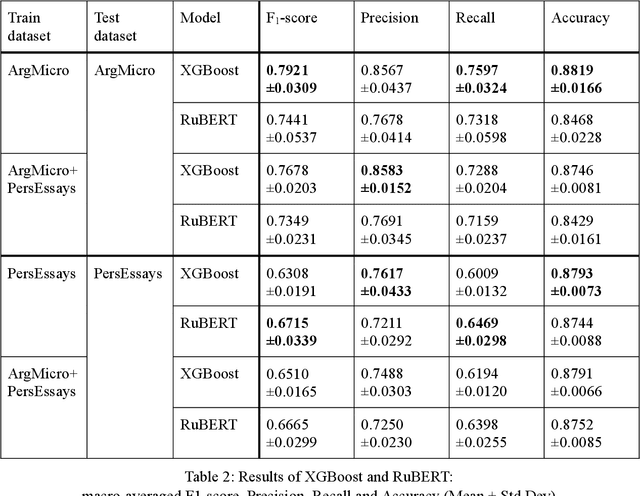
Argumentation mining is a field of computational linguistics that is devoted to extracting from texts and classifying arguments and relations between them, as well as constructing an argumentative structure. A significant obstacle to research in this area for the Russian language is the lack of annotated Russian-language text corpora. This article explores the possibility of improving the quality of argumentation mining using the extension of the Russian-language version of the Argumentative Microtext Corpus (ArgMicro) based on the machine translation of the Persuasive Essays Corpus (PersEssays). To make it possible to use these two corpora combined, we propose a Joint Argument Annotation Scheme based on the schemes used in ArgMicro and PersEssays. We solve the problem of classifying argumentative discourse units (ADUs) into two classes - "pro" ("for") and "opp" ("against") using traditional machine learning techniques (SVM, Bagging and XGBoost) and a deep neural network (BERT model). An ensemble of XGBoost and BERT models was proposed, which showed the highest performance of ADUs classification for both corpora.