 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Collapse in Machine Translation Through the Lens of Angular Dispersion
Feb 19, 2026Modern neural translation models based on the Transformer architecture are known for their high performance, particularly when trained on high-resource datasets. A standard next-token prediction training strategy, while widely adopted in practice, may lead to overlooked artifacts such as representation collapse. Previous works have shown that this problem is especially pronounced in the representation of the deeper Transformer layers, where it often fails to efficiently utilize the geometric space. Representation collapse is even more evident in end-to-end training of continuous-output neural machine translation, where the trivial solution would be to set all vectors to the same value. In this work, we analyze the dynamics of representation collapse at different levels of discrete and continuous NMT transformers throughout training. We incorporate an existing regularization method based on angular dispersion and demonstrate empirically that it not only mitigates collapse but also improves translation quality. Furthermore, we show that quantized models exhibit similar collapse behavior and that the benefits of regularization are preserved even after quantization.
Keep your distance: learning dispersed embeddings on $\mathbb{S}_d$
Feb 12, 2025



Learning well-separated features in high-dimensional spaces, such as text or image embeddings, is crucial for many machine learning applications. Achieving such separation can be effectively accomplished through the dispersion of embeddings, where unrelated vectors are pushed apart as much as possible. By constraining features to be on a hypersphere, we can connect dispersion to well-studied problems in mathematics and physics, where optimal solutions are known for limited low-dimensional cases. However, in representation learning we typically deal with a large number of features in high-dimensional space, and moreover, dispersion is usually traded off with some other task-oriented training objective, making existing theoretical and numerical solutions inapplicable. Therefore, it is common to rely on gradient-based methods to encourage dispersion, usually by minimizing some function of the pairwise distances. In this work, we first give an overview of existing methods from disconnected literature, making new connections and highlighting similarities. Next, we introduce some new angles. We propose to reinterpret pairwise dispersion using a maximum mean discrepancy (MMD) motivation. We then propose an online variant of the celebrated Lloyd's algorithm, of K-Means fame, as an effective alternative regularizer for dispersion on generic domains. Finally, we derive a novel dispersion method that directly exploits properties of the hypersphere. Our experiments show the importance of dispersion in image classification and natural language processing tasks, and how algorithms exhibit different trade-offs in different regimes.
The Unreasonable Effectiveness of Random Target Embeddings for Continuous-Output Neural Machine Translation
Oct 31, 2023



Continuous-output neural machine translation (CoNMT) replaces the discrete next-word prediction problem with an embedding prediction. The semantic structure of the target embedding space (i.e., closeness of related words) is intuitively believed to be crucial. We challenge this assumption and show that completely random output embeddings can outperform laboriously pretrained ones, especially on larger datasets. Further investigation shows this surprising effect is strongest for rare words, due to the geometry of their embeddings. We shed further light on this finding by designing a mixed strategy that combines random and pre-trained embeddings for different tokens.
Investigation on Data Adaptation Techniques for Neural Named Entity Recognition
Oct 12, 2021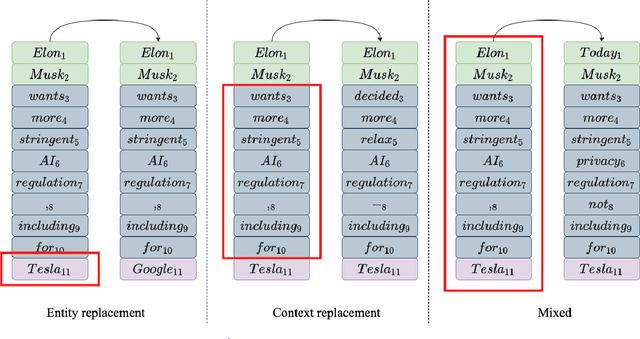
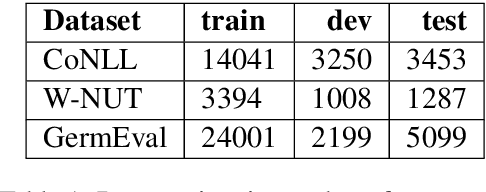
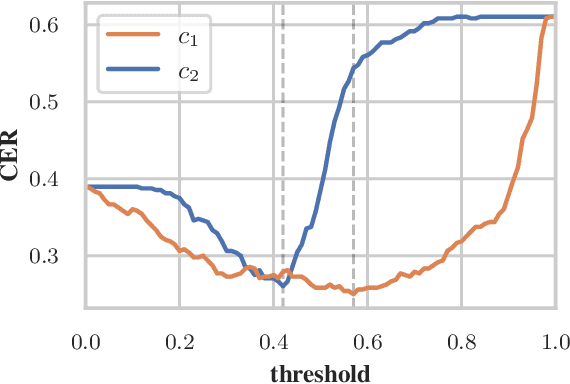
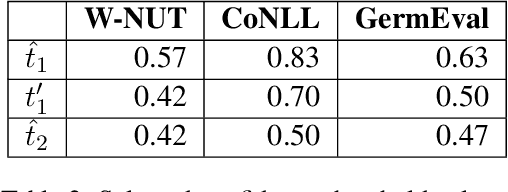
Data processing is an important step in various natural language processing tasks. As the commonly used datasets in named entity recognition contain only a limited number of samples, it is important to obtain additional labeled data in an efficient and reliable manner. A common practice is to utilize large monolingual unlabeled corpora. Another popular technique is to create synthetic data from the original labeled data (data augmentation). In this work, we investigate the impact of these two methods on the performance of three different named entity recognition tasks.
Towards Reinforcement Learning for Pivot-based Neural Machine Translation with Non-autoregressive Transformer
Sep 27, 2021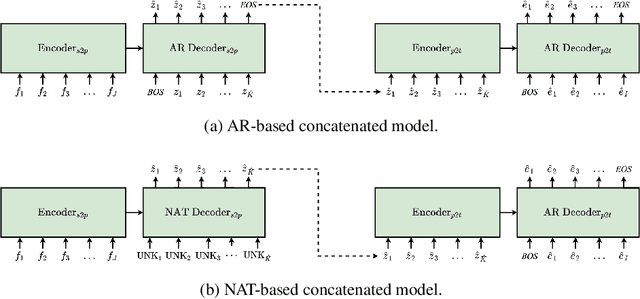
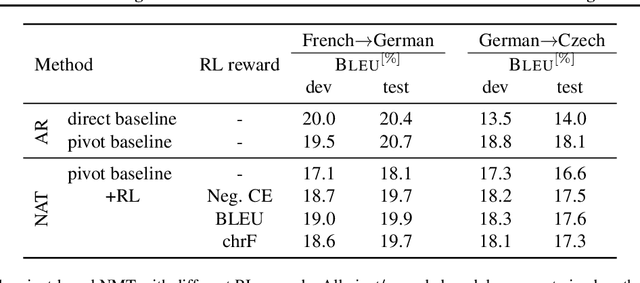
Pivot-based neural machine translation (NMT) is commonly used in low-resource setups, especially for translation between non-English language pairs. It benefits from using high resource source-pivot and pivot-target language pairs and an individual system is trained for both sub-tasks. However, these models have no connection during training, and the source-pivot model is not optimized to produce the best translation for the source-target task. In this work, we propose to train a pivot-based NMT system with the reinforcement learning (RL) approach, which has been investigated for various text generation tasks, including machine translation (MT). We utilize a non-autoregressive transformer and present an end-to-end pivot-based integrated model, enabling training on source-target data.
Integrated Training for Sequence-to-Sequence Models Using Non-Autoregressive Transformer
Sep 27, 2021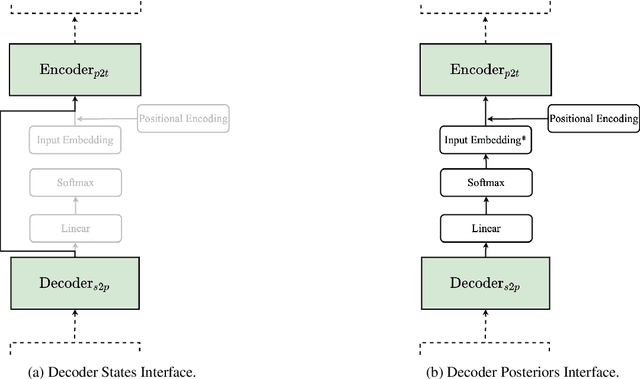
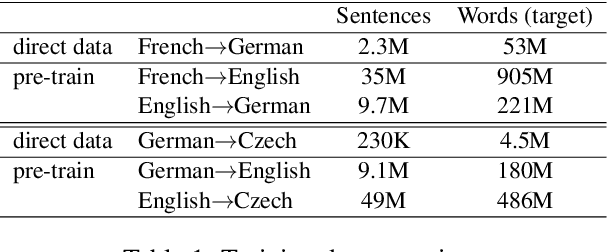
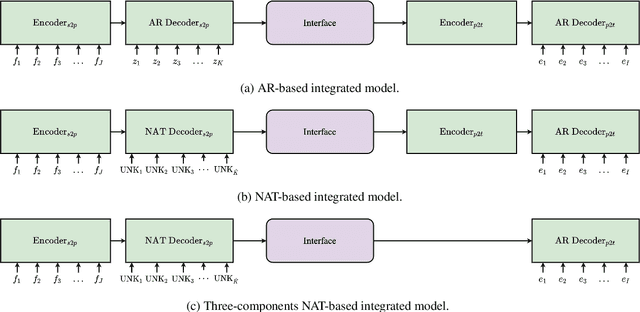
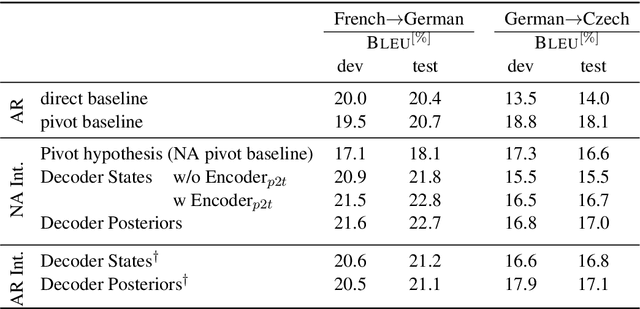
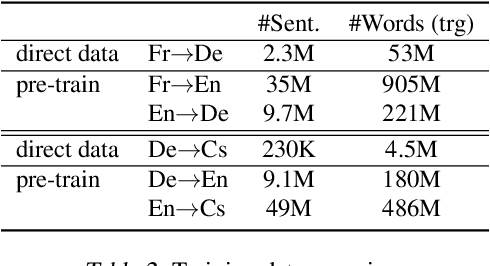
Complex natural language applications such as speech translation or pivot translation traditionally rely on cascaded models. However, cascaded models are known to be prone to error propagation and model discrepancy problems. Furthermore, there is no possibility of using end-to-end training data in conventional cascaded systems, meaning that the training data most suited for the task cannot be used. Previous studies suggested several approaches for integrated end-to-end training to overcome those problems, however they mostly rely on (synthetic or natural) three-way data. We propose a cascaded model based on the non-autoregressive Transformer that enables end-to-end training without the need for an explicit intermediate representation. This new architecture (i) avoids unnecessary early decisions that can cause errors which are then propagated throughout the cascaded models and (ii) utilizes the end-to-end training data directly. We conduct an evaluation on two pivot-based machine translation tasks, namely French-German and German-Czech. Our experimental results show that the proposed architecture yields an improvement of more than 2 BLEU for French-German over the cascaded baseline.