 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Examples that Fool Detectors
Dec 07, 2017



An adversarial example is an example that has been adjusted to produce a wrong label when presented to a system at test time. To date, adversarial example constructions have been demonstrated for classifiers, but not for detectors. If adversarial examples that could fool a detector exist, they could be used to (for example) maliciously create security hazards on roads populated with smart vehicles. In this paper, we demonstrate a construction that successfully fools two standard detectors, Faster RCNN and YOLO. The existence of such examples is surprising, as attacking a classifier is very different from attacking a detector, and that the structure of detectors - which must search for their own bounding box, and which cannot estimate that box very accurately - makes it quite likely that adversarial patterns are strongly disrupted. We show that our construction produces adversarial examples that generalize well across sequences digitally, even though large perturbations are needed. We also show that our construction yields physical objects that are adversarial.
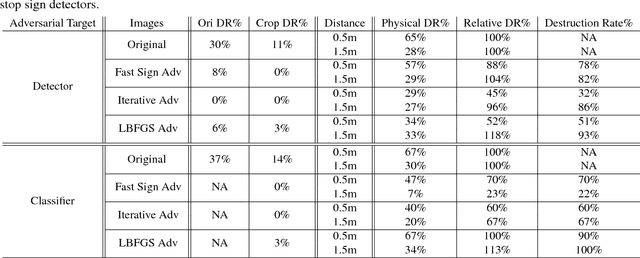
Standard detectors aren't fooled by physical adversarial stop signs
Oct 26, 2017



An adversarial example is an example that has been adjusted to produce the wrong label when presented to a system at test time. If adversarial examples existed that could fool a detector, they could be used to (for example) wreak havoc on roads populated with smart vehicles. Recently, we described our difficulties creating physical adversarial stop signs that fool a detector. More recently, Evtimov et al. produced a physical adversarial stop sign that fools a proxy model of a detector. In this paper, we show that these physical adversarial stop signs do not fool two standard detectors (YOLO and Faster RCNN) in standard configuration. Evtimov et al.'s construction relies on a crop of the image to the stop sign; this crop is then resized and presented to a classifier. We argue that the cropping and resizing procedure largely eliminates the effects of rescaling and of view angle. Whether an adversarial attack is robust under rescaling and change of view direction remains moot. We argue that attacking a classifier is very different from attacking a detector, and that the structure of detectors - which must search for their own bounding box, and which cannot estimate that box very accurately - likely makes it difficult to make adversarial patterns. Finally, an adversarial pattern on a physical object that could fool a detector would have to be adversarial in the face of a wide family of parametric distortions (scale; view angle; box shift inside the detector; illumination; and so on). Such a pattern would be of great theoretical and practical interest. There is currently no evidence that such patterns exist.
NO Need to Worry about Adversarial Examples in Object Detection in Autonomous Vehicles
Jul 12, 2017


It has been shown that most machine learning algorithms are susceptible to adversarial perturbations. Slightly perturbing an image in a carefully chosen direction in the image space may cause a trained neural network model to misclassify it. Recently, it was shown that physical adversarial examples exist: printing perturbed images then taking pictures of them would still result in misclassification. This raises security and safety concerns. However, these experiments ignore a crucial property of physical objects: the camera can view objects from different distances and at different angles. In this paper, we show experiments that suggest that current constructions of physical adversarial examples do not disrupt object detection from a moving platform. Instead, a trained neural network classifies most of the pictures taken from different distances and angles of a perturbed image correctly. We believe this is because the adversarial property of the perturbation is sensitive to the scale at which the perturbed picture is viewed, so (for example) an autonomous car will misclassify a stop sign only from a small range of distances. Our work raises an important question: can one construct examples that are adversarial for many or most viewing conditions? If so, the construction should offer very significant insights into the internal representation of patterns by deep networks. If not, there is a good prospect that adversarial examples can be reduced to a curiosity with little practical impact.