 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison of Modern Multilingual Text Embedding Techniques for Hate Speech Detection Task
Apr 16, 2026Online hate speech and abusive language pose a growing challenge for content moderation, especially in multilingual settings and for low-resource languages such as Lithuanian. This paper investigates to what extent modern multilingual sentence embedding models can support accurate hate speech detection in Lithuanian, Russian, and English, and how their performance depends on downstream modeling choices and feature dimensionality. We introduce LtHate, a new Lithuanian hate speech corpus derived from news portals and social networks, and benchmark six modern multilingual encoders (potion, gemma, bge, snow, jina, e5) on LtHate, RuToxic, and EnSuperset using a unified Python pipeline. For each embedding, we train both a one class HBOS anomaly detector and a two class CatBoost classifier, with and without principal component analysis (PCA) compression to 64-dimensional feature vectors. Across all datasets, two class supervised models consistently and substantially outperform one class anomaly detection, with the best configurations achieving up to 80.96% accuracy and AUC ROC of 0.887 in Lithuanian (jina), 92.19% accuracy and AUC ROC of 0.978 in Russian (e5), and 77.21% accuracy and AUC ROC of 0.859 in English (e5 with PCA). PCA compression preserves almost all discriminative power in the supervised setting, while showing some negative impact for the unsupervised anomaly detection case. These results demonstrate how modern multilingual sentence embeddings combined with gradient boosted decision trees provide robust soft-computing solutions for multilingual hate speech detection applications.
Exploring traditional machine learning for identification of pathological auscultations
Sep 01, 2022
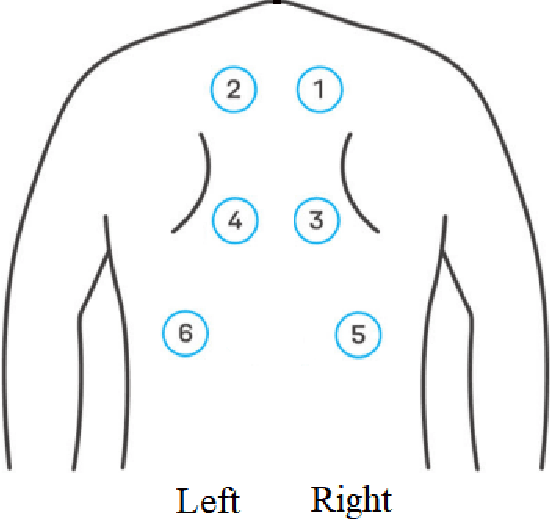


Today, data collection has improved in various areas, and the medical domain is no exception. Auscultation, as an important diagnostic technique for physicians, due to the progress and availability of digital stethoscopes, lends itself well to applications of machine learning. Due to the large number of auscultations performed, the availability of data opens up an opportunity for more effective analysis of sounds where prognostic accuracy even among experts remains low. In this study, digital 6-channel auscultations of 45 patients were used in various machine learning scenarios, with the aim of distinguishing between normal and anomalous pulmonary sounds. Audio features (such as fundamental frequencies F0-4, loudness, HNR, DFA, as well as descriptive statistics of log energy, RMS and MFCC) were extracted using the Python library Surfboard. Windowing and feature aggregation and concatenation strategies were used to prepare data for tree-based ensemble models in unsupervised (fair-cut forest) and supervised (random forest) machine learning settings. The evaluation was carried out using 9-fold stratified cross-validation repeated 30 times. Decision fusion by averaging outputs for a subject was tested and found to be useful. Supervised models showed a consistent advantage over unsupervised ones, achieving mean AUC ROC of 0.691 (accuracy 71.11%, Kappa 0.416, F1-score 0.771) in side-based detection and mean AUC ROC of 0.721 (accuracy 68.89%, Kappa 0.371, F1-score 0.650) in patient-based detection.
Meta-Learning for Time Series Forecasting Ensemble
Nov 20, 2020

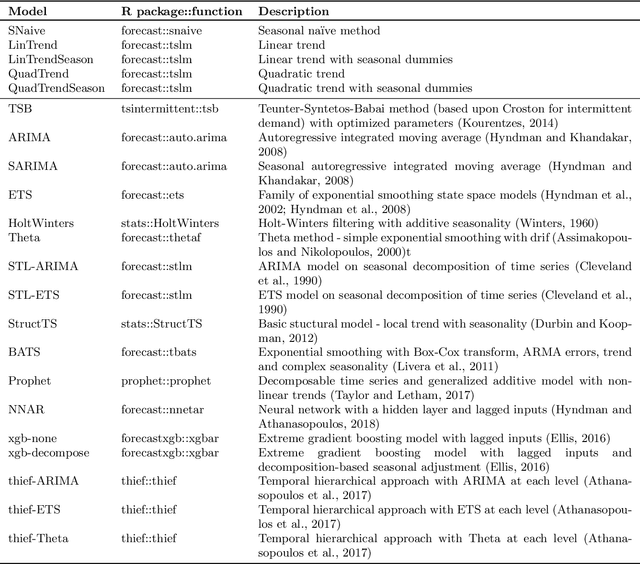
Amounts of historical data collected increase together with business intelligence applicability and demands for automatic forecasting of time series. While no single time series modeling method is universal to all types of dynamics, forecasting using ensemble of several methods is often seen as a compromise. Instead of fixing ensemble diversity and size we propose to adaptively predict these aspects using meta-learning. Meta-learning here considers two separate random forest regression models, built on 390 time series features, to rank 22 univariate forecasting methods and to recommend ensemble size. Forecasting ensemble is consequently formed from methods ranked as the best and forecasts are pooled using either simple or weighted average (with weight corresponding to reciprocal rank). Proposed approach was tested on 12561 micro-economic time series (expanded to 38633 for various forecasting horizons) of M4 competition where meta-learning outperformed Theta and Comb benchmarks by relative forecasting errors for all data types and horizons. Best overall results were achieved by weighted pooling with symmetric mean absolute percentage error of 9.21% versus 11.05% obtained using Theta method.