 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurating art exhibitions using machine learning
Jun 24, 2025Art curatorship has always been mostly the subjective work of human experts, who, with extensive knowledge of many and diverse artworks, select a few of those to present in communal spaces, spaces that evolved into what we now call art galleries. There are no hard and fast set of rules on how to select these artworks, given a theme which either is presented to the art curator or constructed by her/him. Here we present a series of artificial models -- a total of four related models -- based on machine learning techniques (a subset of artificial intelligence) that attempt to learn from existing exhibitions which have been curated by human experts, in order to be able to do similar curatorship work. We focus exclusively on the last 25 years of past exhibitions at the Metropolitan Museum of Art in New York, due to the quality of the data available and the physical and time limitations of our research. Our four artificial intelligence models achieve a reasonable ability at imitating these various curators responsible for all those exhibitions, with various degrees of precision and curatorial coherence. In particular, we can conclude two key insights: first, that there is sufficient information in these exhibitions to construct an artificial intelligence model that replicates past exhibitions with an accuracy well above random choices; second, that using feature engineering and carefully designing the architecture of modest size models can make them as good as those using the so-called large language models such as GPT in a brute force approach. We also believe, based on small attempts to use the models in out-of-sample experiments, that given more much more data, it should be possible for these kinds of artificial intelligence agents to be closer and closer to the aesthetic and curatorial judgment of human art curators.
Named entity recognition using GPT for identifying comparable companies
Jul 11, 2023For both public and private firms, comparable companies analysis is widely used as a method for company valuation. In particular, the method is of great value for valuation of private equity companies. The several approaches to the comparable companies method usually rely on a qualitative approach to identifying similar peer companies, which tends to use established industry classification schemes and/or analyst intuition and knowledge. However, more quantitative methods have started being used in the literature and in the private equity industry, in particular, machine learning clustering, and natural language processing (NLP). For NLP methods, the process consists of extracting product entities from e.g., the company's website or company descriptions from some financial database system and then to perform similarity analysis. Here, using companies descriptions/summaries from publicly available companies' Wikipedia websites, we show that using large language models (LLMs), such as GPT from openaAI, has a much higher precision and success rate than using the standard named entity recognition (NER) which uses manual annotation. We demonstrate quantitatively a higher precision rate, and show that, qualitatively, it can be used to create appropriate comparable companies peer groups which can then be used for equity valuation.
Transfer Learning in Spatial-Temporal Forecasting of the Solar Magnetic Field
Nov 08, 2019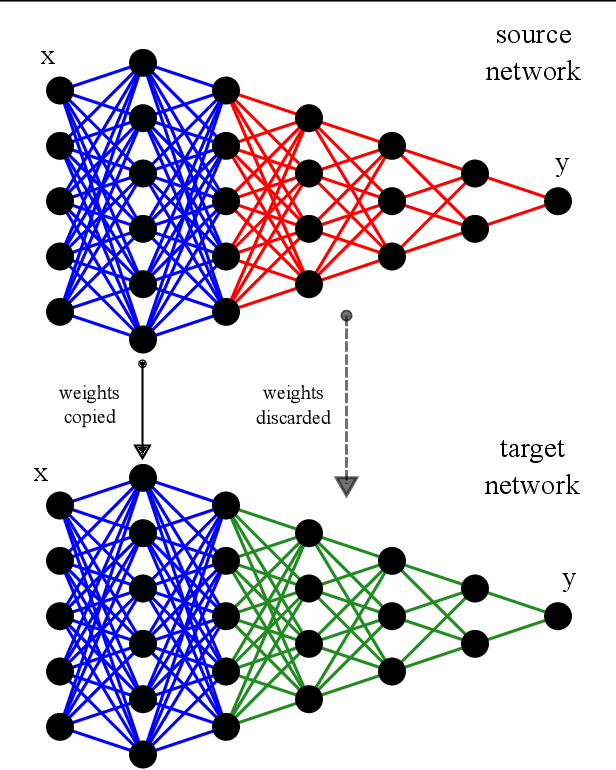


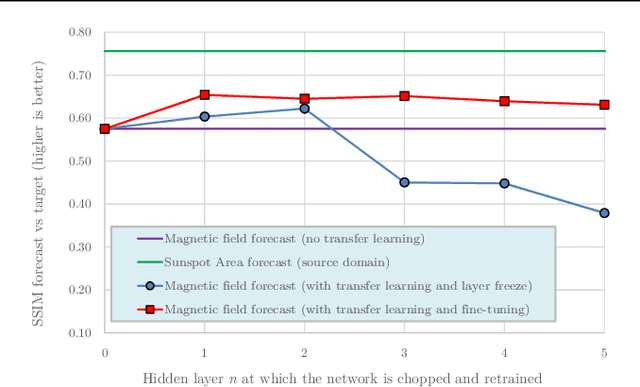
Machine learning techniques have been widely used in attempts to forecast several solar datasets. Most of these approaches employ supervised machine learning algorithms which are, in general, very data hungry. This hampers the attempts to forecast some of these data series, particularly the ones that depend on (relatively) recent space observations. Here we focus on an attempt to forecast the solar surface longitudinally averaged radial magnetic field distribution using a form of spatial-temporal neural networks. Given that the recording of these spatial-temporal datasets only started in 1975 and are therefore quite short, the forecasts are predictably quite modest. However, given that there is a potential physical relationship between sunspots and the magnetic field, we employ another machine learning technique called transfer learning which has recently received considerable attention in the literature. Here, this approach consists in first training the source spatial-temporal neural network on the much longer time/latitude sunspot area dataset, which starts in 1874, then transferring the trained set of layers to a target network, and continue training the latter on the magnetic field dataset. The employment of transfer learning in the field of computer vision is known to obtain a generalized set of feature filters that can be reused for other datasets and tasks. Here we obtain a similar result, whereby we first train the network on the spatial-temporal sunspot area data, then the first few layers of the neural network are able to identify the two main features of the solar cycle, i.e. the amplitude variation and the migration to the equator, and therefore can be used to train on the magnetic field dataset and forecast better than a prediction based only on the historical magnetic field data.
Optimal Neural Network Feature Selection for Spatial-Temporal Forecasting
Apr 30, 2018
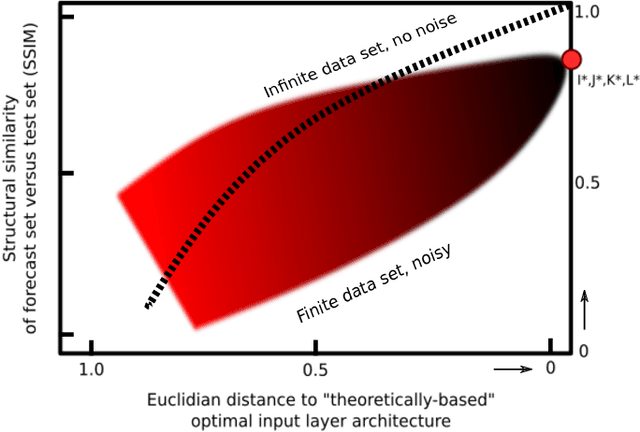


In this paper, we show empirical evidence on how to construct the optimal feature selection or input representation used by the input layer of a feedforward neural network for the propose of forecasting spatial-temporal signals. The approach is based on results from dynamical systems theory, namely the non-linear embedding theorems. We demonstrate it for a variety of spatial-temporal signals, with one spatial and one temporal dimensions, and show that the optimal input layer representation consists of a grid, with spatial/temporal lags determined by the minimum of the mutual information of the spatial/temporal signals and the number of points taken in space/time decided by the embedding dimension of the signal. We present evidence of this proposal by running a Monte Carlo simulation of several combinations of input layer feature designs and show that the one predicted by the non-linear embedding theorems seems to be optimal or close of optimal. In total we show evidence in four unrelated systems: a series of coupled Henon maps; a series of couple Ordinary Differential Equations (Lorenz-96) phenomenologically modelling atmospheric dynamics; the Kuramoto-Sivashinsky equation, a partial differential equation used in studies of instabilities in laminar flame fronts and finally real physical data from sunspot areas in the Sun (in latitude and time) from 1874 to 2015.