 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositionality and Generalization in Emergent Languages
Apr 20, 2020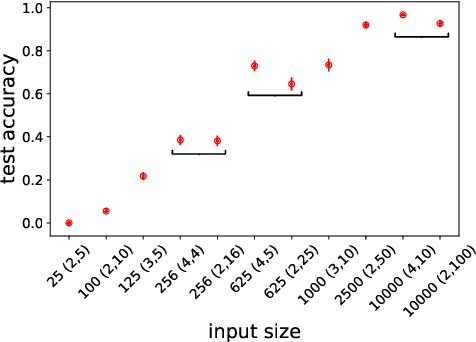
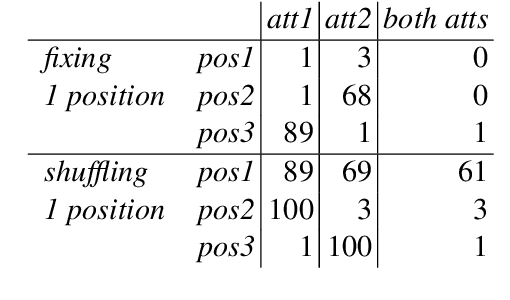
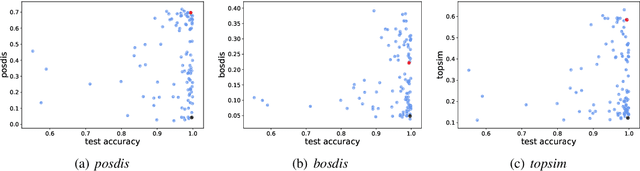

Natural language allows us to refer to novel composite concepts by combining expressions denoting their parts according to systematic rules, a property known as \emph{compositionality}. In this paper, we study whether the language emerging in deep multi-agent simulations possesses a similar ability to refer to novel primitive combinations, and whether it accomplishes this feat by strategies akin to human-language compositionality. Equipped with new ways to measure compositionality in emergent languages inspired by disentanglement in representation learning, we establish three main results. First, given sufficiently large input spaces, the emergent language will naturally develop the ability to refer to novel composite concepts. Second, there is no correlation between the degree of compositionality of an emergent language and its ability to generalize. Third, while compositionality is not necessary for generalization, it provides an advantage in terms of language transmission: The more compositional a language is, the more easily it will be picked up by new learners, even when the latter differ in architecture from the original agents. We conclude that compositionality does not arise from simple generalization pressure, but if an emergent language does chance upon it, it will be more likely to survive and thrive.
EGG: a toolkit for research on Emergence of lanGuage in Games
Jul 01, 2019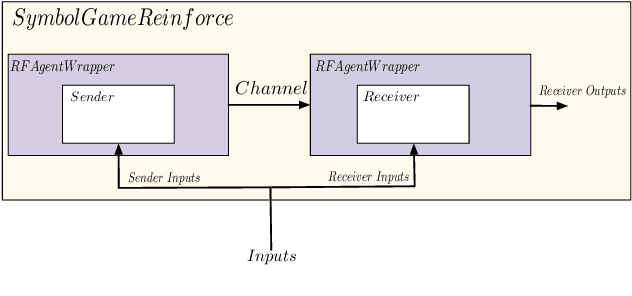



There is renewed interest in simulating language emergence among deep neural agents that communicate to jointly solve a task, spurred by the practical aim to develop language-enabled interactive AIs, as well as by theoretical questions about the evolution of human language. However, optimizing deep architectures connected by a discrete communication channel (such as that in which language emerges) is technically challenging. We introduce EGG, a toolkit that greatly simplifies the implementation of emergent-language communication games. EGG's modular design provides a set of building blocks that the user can combine to create new games, easily navigating the optimization and architecture space. We hope that the tool will lower the technical barrier, and encourage researchers from various backgrounds to do original work in this exciting area.
Word-order biases in deep-agent emergent communication
Jun 14, 2019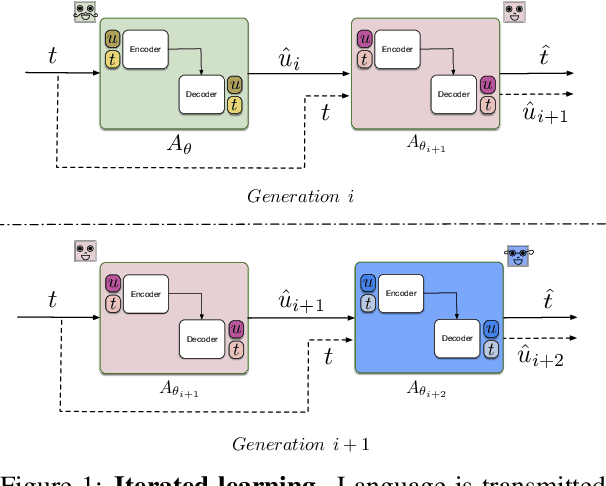
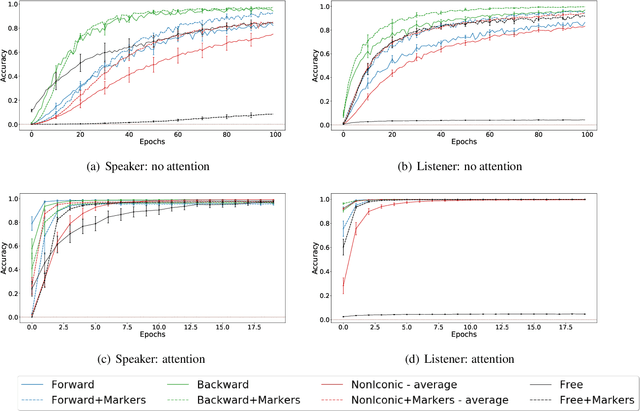
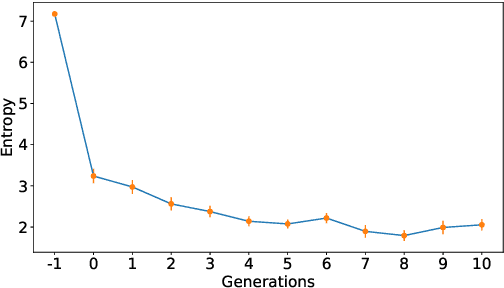
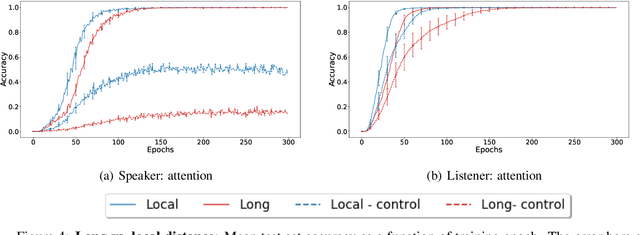
Sequence-processing neural networks led to remarkable progress on many NLP tasks. As a consequence, there has been increasing interest in understanding to what extent they process language as humans do. We aim here to uncover which biases such models display with respect to "natural" word-order constraints. We train models to communicate about paths in a simple gridworld, using miniature languages that reflect or violate various natural language trends, such as the tendency to avoid redundancy or to minimize long-distance dependencies. We study how the controlled characteristics of our miniature languages affect individual learning and their stability across multiple network generations. The results draw a mixed picture. On the one hand, neural networks show a strong tendency to avoid long-distance dependencies. On the other hand, there is no clear preference for the efficient, non-redundant encoding of information that is widely attested in natural language. We thus suggest inoculating a notion of "effort" into neural networks, as a possible way to make their linguistic behavior more human-like.
Anti-efficient encoding in emergent communication
Jun 13, 2019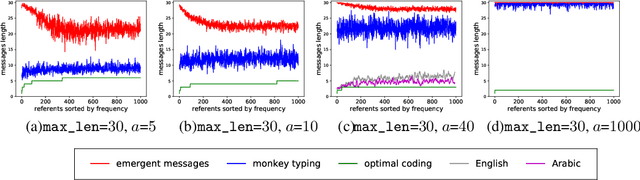
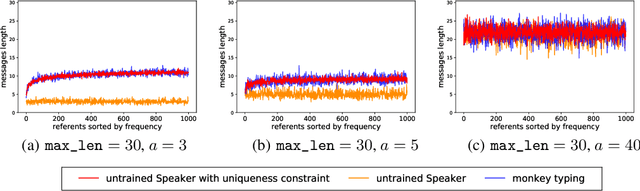
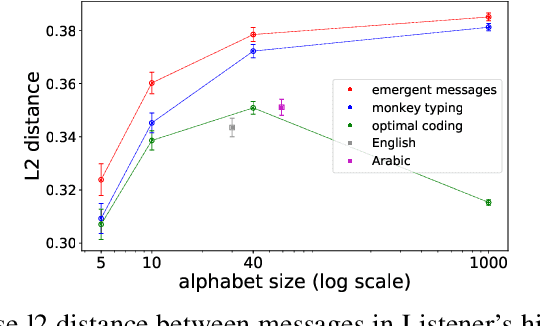
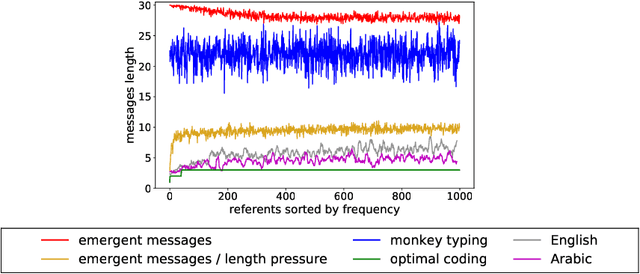
Despite renewed interest in emergent language simulations with neural networks, little is known about the basic properties of the induced code, and how they compare to human language. One fundamental characteristic of the latter, known as Zipf's Law of Abbreviation (ZLA), is that more frequent words are efficiently associated to shorter strings. We study whether the same pattern emerges when two neural networks, a "speaker" and a "listener", are trained to play a signaling game. Surprisingly, we find that networks develop an \emph{anti-efficient} encoding scheme, in which the most frequent inputs are associated to the longest messages, and messages in general are skewed towards the maximum length threshold. This anti-efficient code appears easier to discriminate for the listener, and, unlike in human communication, the speaker does not impose a contrasting least-effort pressure towards brevity. Indeed, when the cost function includes a penalty for longer messages, the resulting message distribution starts respecting ZLA. Our analysis stresses the importance of studying the basic features of emergent communication in a highly controlled setup, to ensure the latter will not strand too far from human language. Moreover, we present a concrete illustration of how different functional pressures can lead to successful communication codes that lack basic properties of human language, thus highlighting the role such pressures play in the latter.
Information Minimization In Emergent Languages
May 31, 2019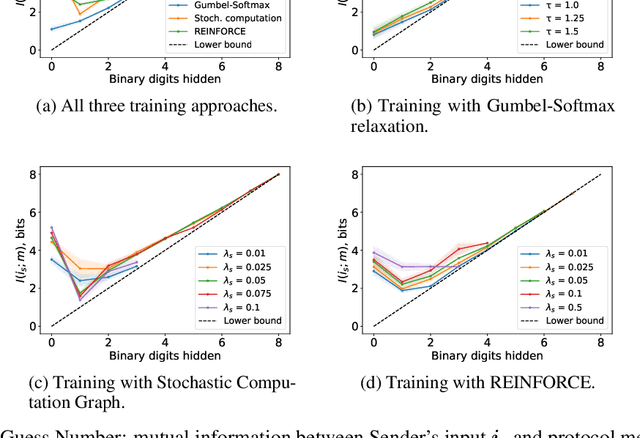
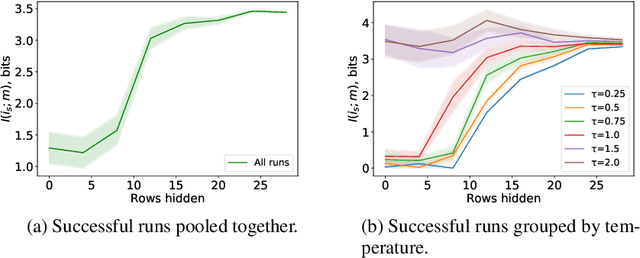
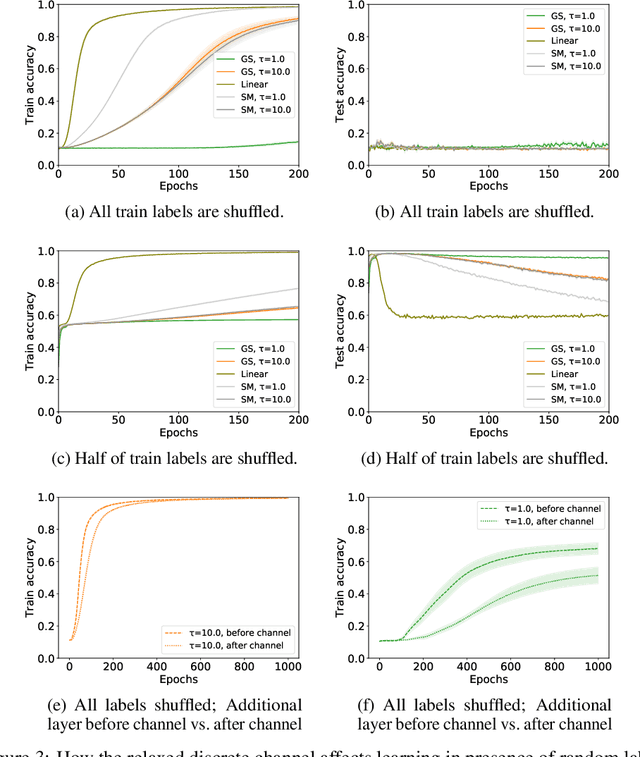
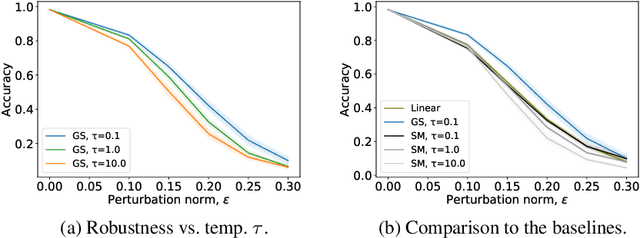
There is a growing interest in studying the languages emerging when neural agents are jointly trained to solve tasks that require communication through discrete messages. We investigate here the information-theoretic complexity of such languages, focusing on the most basic two-agent, one-symbol, one-exchange setup. We find that, under common training procedures, the emergent languages are subject to an information minimization pressure: The mutual information between the communicating agent's inputs and the messages is close to the minimum that still allows the task to be solved. After verifying this information minimization property, we perform experiments showing that a stronger discrete-channel-driven information minimization pressure leads to increased robustness to overfitting and to adversarial attacks. We conclude by discussing the implications of our findings for the studies of artificial and natural language emergence, and for representation learning.