 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnsembling of Distilled Models from Multi-task Teachers for Constrained Resource Language Pairs
Nov 26, 2021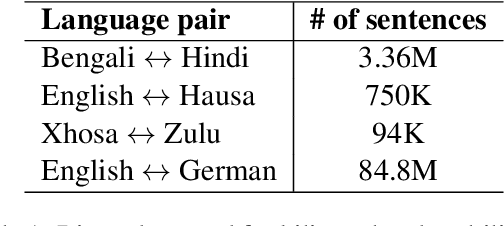
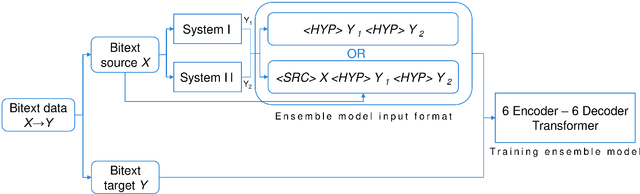
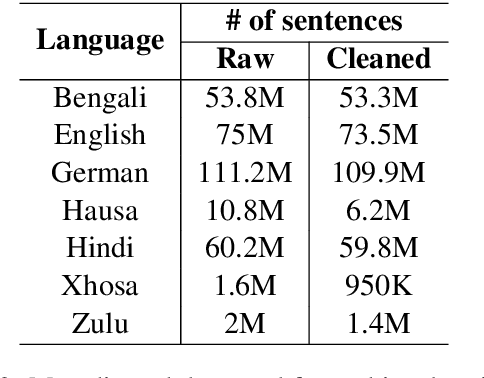
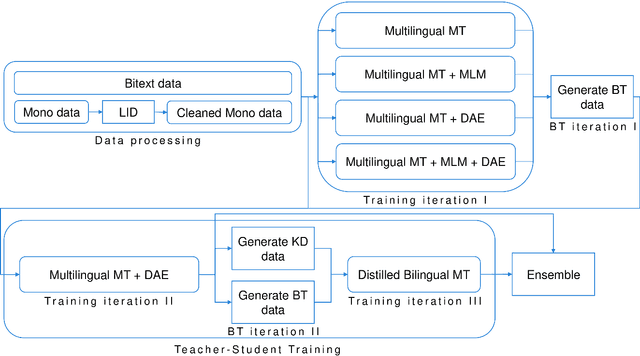
This paper describes our submission to the constrained track of WMT21 shared news translation task. We focus on the three relatively low resource language pairs Bengali to and from Hindi, English to and from Hausa, and Xhosa to and from Zulu. To overcome the limitation of relatively low parallel data we train a multilingual model using a multitask objective employing both parallel and monolingual data. In addition, we augment the data using back translation. We also train a bilingual model incorporating back translation and knowledge distillation then combine the two models using sequence-to-sequence mapping. We see around 70% relative gain in BLEU point for English to and from Hausa, and around 25% relative improvements for both Bengali to and from Hindi, and Xhosa to and from Zulu compared to bilingual baselines.