 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeiMotion-LLM: Motion Prediction Instruction Tuning
Jun 11, 2024



We introduce iMotion-LLM: a Multimodal Large Language Models (LLMs) with trajectory prediction, tailored to guide interactive multi-agent scenarios. Different from conventional motion prediction approaches, iMotion-LLM capitalizes on textual instructions as key inputs for generating contextually relevant trajectories. By enriching the real-world driving scenarios in the Waymo Open Dataset with textual motion instructions, we created InstructWaymo. Leveraging this dataset, iMotion-LLM integrates a pretrained LLM, fine-tuned with LoRA, to translate scene features into the LLM input space. iMotion-LLM offers significant advantages over conventional motion prediction models. First, it can generate trajectories that align with the provided instructions if it is a feasible direction. Second, when given an infeasible direction, it can reject the instruction, thereby enhancing safety. These findings act as milestones in empowering autonomous navigation systems to interpret and predict the dynamics of multi-agent environments, laying the groundwork for future advancements in this field.
Kestrel: Point Grounding Multimodal LLM for Part-Aware 3D Vision-Language Understanding
May 29, 2024



While 3D MLLMs have achieved significant progress, they are restricted to object and scene understanding and struggle to understand 3D spatial structures at the part level. In this paper, we introduce Kestrel, representing a novel approach that empowers 3D MLLMs with part-aware understanding, enabling better interpretation and segmentation grounding of 3D objects at the part level. Despite its significance, the current landscape lacks tasks and datasets that endow and assess this capability. Therefore, we propose two novel tasks: (1) Part-Aware Point Grounding, the model is tasked with directly predicting a part-level segmentation mask based on user instructions, and (2) Part-Aware Point Grounded Captioning, the model provides a detailed caption that includes part-level descriptions and their corresponding masks. To support learning and evaluating for these tasks, we introduce 3DCoMPaT Grounded Instructions Dataset (3DCoMPaT-GRIN). 3DCoMPaT-GRIN Vanilla, comprising 789k part-aware point cloud-instruction-segmentation mask triplets, is used to evaluate MLLMs' ability of part-aware segmentation grounding. 3DCoMPaT-GRIN Grounded Caption, containing 107k part-aware point cloud-instruction-grounded caption triplets, assesses both MLLMs' part-aware language comprehension and segmentation grounding capabilities. Our introduced tasks, dataset, and Kestrel represent a preliminary effort to bridge the gap between human cognition and 3D MLLMs, i.e., the ability to perceive and engage with the environment at both global and part levels. Extensive experiments on the 3DCoMPaT-GRIN show that Kestrel can generate user-specified segmentation masks, a capability not present in any existing 3D MLLM. Kestrel thus established a benchmark for evaluating the part-aware language comprehension and segmentation grounding of 3D objects. Project page at https://feielysia.github.io/Kestrel.github.io/
ToddlerDiffusion: Flash Interpretable Controllable Diffusion Model
Nov 24, 2023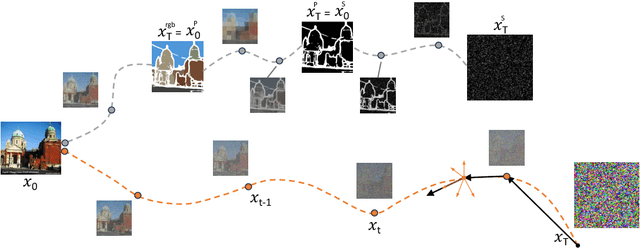

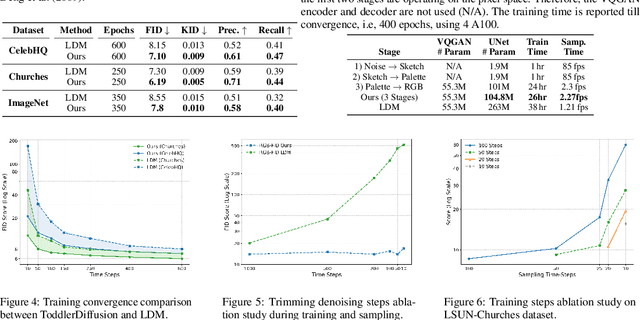
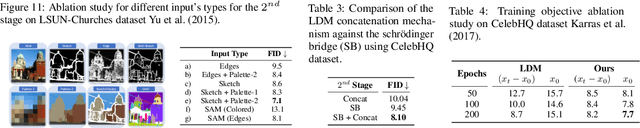
Diffusion-based generative models excel in perceptually impressive synthesis but face challenges in interpretability. This paper introduces ToddlerDiffusion, an interpretable 2D diffusion image-synthesis framework inspired by the human generation system. Unlike traditional diffusion models with opaque denoising steps, our approach decomposes the generation process into simpler, interpretable stages; generating contours, a palette, and a detailed colored image. This not only enhances overall performance but also enables robust editing and interaction capabilities. Each stage is meticulously formulated for efficiency and accuracy, surpassing Stable-Diffusion (LDM). Extensive experiments on datasets like LSUN-Churches and COCO validate our approach, consistently outperforming existing methods. ToddlerDiffusion achieves notable efficiency, matching LDM performance on LSUN-Churches while operating three times faster with a 3.76 times smaller architecture. Our source code is provided in the supplementary material and will be publicly accessible.
CoT3DRef: Chain-of-Thoughts Data-Efficient 3D Visual Grounding
Oct 10, 2023



3D visual grounding is the ability to localize objects in 3D scenes conditioned by utterances. Most existing methods devote the referring head to localize the referred object directly, causing failure in complex scenarios. In addition, it does not illustrate how and why the network reaches the final decision. In this paper, we address this question Can we design an interpretable 3D visual grounding framework that has the potential to mimic the human perception system?. To this end, we formulate the 3D visual grounding problem as a sequence-to-sequence task by first predicting a chain of anchors and then the final target. Interpretability not only improves the overall performance but also helps us identify failure cases. Following the chain of thoughts approach enables us to decompose the referring task into interpretable intermediate steps, boosting the performance and making our framework extremely data-efficient. Moreover, our proposed framework can be easily integrated into any existing architecture. We validate our approach through comprehensive experiments on the Nr3D, Sr3D, and Scanrefer benchmarks and show consistent performance gains compared to existing methods without requiring manually annotated data. Furthermore, our proposed framework, dubbed CoT3DRef, is significantly data-efficient, whereas on the Sr3D dataset, when trained only on 10% of the data, we match the SOTA performance that trained on the entire data.
HRS-Bench: Holistic, Reliable and Scalable Benchmark for Text-to-Image Models
Apr 11, 2023



In recent years, Text-to-Image (T2I) models have been extensively studied, especially with the emergence of diffusion models that achieve state-of-the-art results on T2I synthesis tasks. However, existing benchmarks heavily rely on subjective human evaluation, limiting their ability to holistically assess the model's capabilities. Furthermore, there is a significant gap between efforts in developing new T2I architectures and those in evaluation. To address this, we introduce HRS-Bench, a concrete evaluation benchmark for T2I models that is Holistic, Reliable, and Scalable. Unlike existing bench-marks that focus on limited aspects, HRS-Bench measures 13 skills that can be categorized into five major categories: accuracy, robustness, generalization, fairness, and bias. In addition, HRS-Bench covers 50 scenarios, including fashion, animals, transportation, food, and clothes. We evaluate nine recent large-scale T2I models using metrics that cover a wide range of skills. A human evaluation aligned with 95% of our evaluations on average was conducted to probe the effectiveness of HRS-Bench. Our experiments demonstrate that existing models often struggle to generate images with the desired count of objects, visual text, or grounded emotions. We hope that our benchmark help ease future text-to-image generation research. The code and data are available at https://eslambakr.github.io/hrsbench.github.io
ImageCaptioner$^2$: Image Captioner for Image Captioning Bias Amplification Assessment
Apr 10, 2023



Most pre-trained learning systems are known to suffer from bias, which typically emerges from the data, the model, or both. Measuring and quantifying bias and its sources is a challenging task and has been extensively studied in image captioning. Despite the significant effort in this direction, we observed that existing metrics lack consistency in the inclusion of the visual signal. In this paper, we introduce a new bias assessment metric, dubbed $ImageCaptioner^2$, for image captioning. Instead of measuring the absolute bias in the model or the data, $ImageCaptioner^2$ pay more attention to the bias introduced by the model w.r.t the data bias, termed bias amplification. Unlike the existing methods, which only evaluate the image captioning algorithms based on the generated captions only, $ImageCaptioner^2$ incorporates the image while measuring the bias. In addition, we design a formulation for measuring the bias of generated captions as prompt-based image captioning instead of using language classifiers. Finally, we apply our $ImageCaptioner^2$ metric across 11 different image captioning architectures on three different datasets, i.e., MS-COCO caption dataset, Artemis V1, and Artemis V2, and on three different protected attributes, i.e., gender, race, and emotions. Consequently, we verify the effectiveness of our $ImageCaptioner^2$ metric by proposing AnonymousBench, which is a novel human evaluation paradigm for bias metrics. Our metric shows significant superiority over the recent bias metric; LIC, in terms of human alignment, where the correlation scores are 80% and 54% for our metric and LIC, respectively. The code is available at https://eslambakr.github.io/imagecaptioner2.github.io/.
Look Around and Refer: 2D Synthetic Semantics Knowledge Distillation for 3D Visual Grounding
Nov 25, 2022



The 3D visual grounding task has been explored with visual and language streams comprehending referential language to identify target objects in 3D scenes. However, most existing methods devote the visual stream to capturing the 3D visual clues using off-the-shelf point clouds encoders. The main question we address in this paper is "can we consolidate the 3D visual stream by 2D clues synthesized from point clouds and efficiently utilize them in training and testing?". The main idea is to assist the 3D encoder by incorporating rich 2D object representations without requiring extra 2D inputs. To this end, we leverage 2D clues, synthetically generated from 3D point clouds, and empirically show their aptitude to boost the quality of the learned visual representations. We validate our approach through comprehensive experiments on Nr3D, Sr3D, and ScanRefer datasets and show consistent performance gains compared to existing methods. Our proposed module, dubbed as Look Around and Refer (LAR), significantly outperforms the state-of-the-art 3D visual grounding techniques on three benchmarks, i.e., Nr3D, Sr3D, and ScanRefer. The code is available at https://eslambakr.github.io/LAR.github.io/.