 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGaze4HRI: Zero-shot Benchmarking Gaze Estimation Neural-Networks for Human-Robot Interaction
May 06, 2026While zero-shot appearance-based 3D gaze estimation offers significant cost-efficiency by directly mapping RGB images to gaze vectors, its reliability in Human-Robot Interaction (HRI) settings remains uncertain. Existing benchmarks frequently overlook fundamental HRI conditions, such as dynamic camera viewpoints and moving targets in video. Furthermore, current cross-dataset evaluations often suffer from a complexity gap, where methods trained on diverse datasets are tested on significantly smaller and less varied sets, failing to assess true robustness. To bridge these gaps, we introduce Gaze4HRI, a large-scale dataset (50+ subjects, 3,000+ videos, 600,000+ frames) designed to evaluate state-of-the-art performance against critical HRI variables: illumination, head-gaze conflict, as well as the motion of camera and gaze target in video. Our benchmark reveals that all evaluated methods fail in at least one condition, identifying steeply-downward gaze as a universal failure point. Notably, PureGaze trained on the ETH-X-Gaze dataset uniquely maintains resilience across all other conditions. These results challenge the recent focus in the literature on complex spatial-temporal modeling and Transformer-based architectures. Instead, our findings suggest that extensive data diversity, as exemplified by the ETH-X-Gaze dataset, serves as the primary driver of zero-shot robustness in unconstrained environments, while resilience-enhancing frameworks, such as PureGaze's self-adversarial loss for gaze feature purification, provide a substantial further improvement. Ultimately, this study establishes a rigorous benchmark that provides practical guidelines for practitioners as well as reshaping future research. The dataset and codes are available at https://gazeforhri.github.io.
Investigating Bias and Fairness in Appearance-based Gaze Estimation
Apr 12, 2026While appearance-based gaze estimation has achieved significant improvements in accuracy and domain adaptation, the fairness of these systems across different demographic groups remains largely unexplored. To date, there is no comprehensive benchmark quantifying algorithmic bias in gaze estimation. This paper presents the first extensive evaluation of fairness in appearance-based gaze estimation, focusing on ethnicity and gender attributes. We establish a fairness baseline by analyzing state-of-the-art models using standard fairness metrics, revealing significant performance disparities. Furthermore, we evaluate the effectiveness of existing bias mitigation strategies when applied to the gaze domain and show that their fairness contributions are limited. We summarize key insights and open issues. Overall, our work calls for research into developing robust, equitable gaze estimators. To support future research and reproducibility, we publicly release our annotations, code, and trained models at: github.com/akgulburak/gaze-estimation-fairness
AssembleRL: Learning to Assemble Furniture from Their Point Clouds
Sep 15, 2022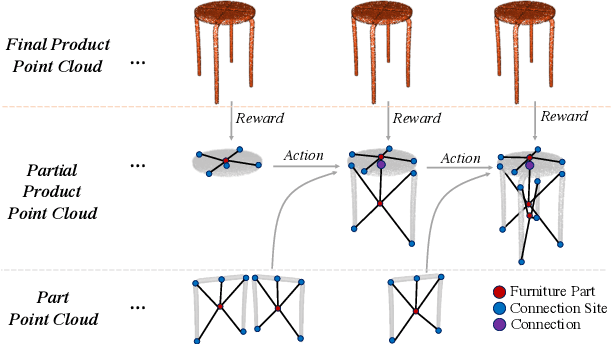
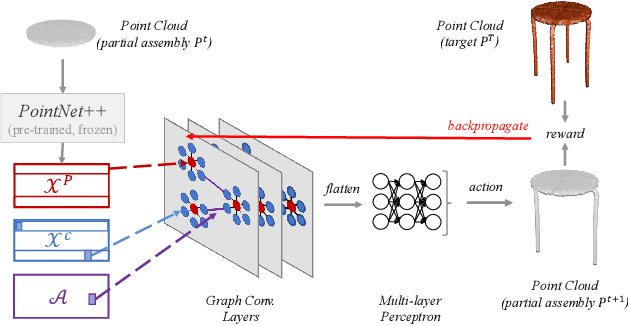
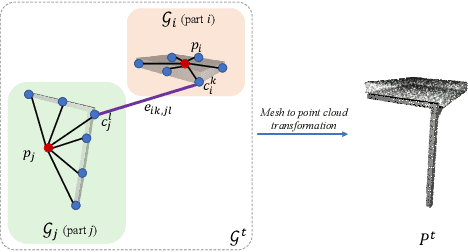
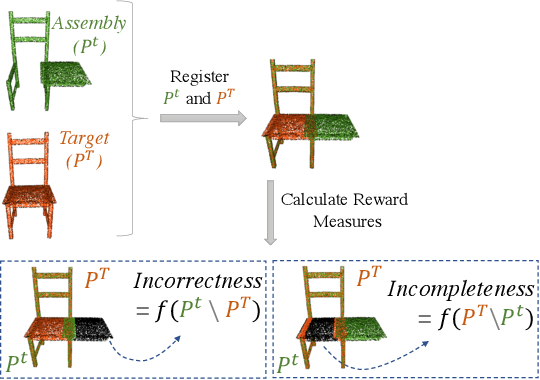
The rise of simulation environments has enabled learning-based approaches for assembly planning, which is otherwise a labor-intensive and daunting task. Assembling furniture is especially interesting since furniture are intricate and pose challenges for learning-based approaches. Surprisingly, humans can solve furniture assembly mostly given a 2D snapshot of the assembled product. Although recent years have witnessed promising learning-based approaches for furniture assembly, they assume the availability of correct connection labels for each assembly step, which are expensive to obtain in practice. In this paper, we alleviate this assumption and aim to solve furniture assembly with as little human expertise and supervision as possible. To be specific, we assume the availability of the assembled point cloud, and comparing the point cloud of the current assembly and the point cloud of the target product, obtain a novel reward signal based on two measures: Incorrectness and incompleteness. We show that our novel reward signal can train a deep network to successfully assemble different types of furniture. Code and networks available here: https://github.com/METU-KALFA/AssembleRL