 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompositional Generalization with Grounded Language Models
Jun 07, 2024



Grounded language models use external sources of information, such as knowledge graphs, to meet some of the general challenges associated with pre-training. By extending previous work on compositional generalization in semantic parsing, we allow for a controlled evaluation of the degree to which these models learn and generalize from patterns in knowledge graphs. We develop a procedure for generating natural language questions paired with knowledge graphs that targets different aspects of compositionality and further avoids grounding the language models in information already encoded implicitly in their weights. We evaluate existing methods for combining language models with knowledge graphs and find them to struggle with generalization to sequences of unseen lengths and to novel combinations of seen base components. While our experimental results provide some insight into the expressive power of these models, we hope our work and released datasets motivate future research on how to better combine language models with structured knowledge representations.
It's Difficult to be Neutral -- Human and LLM-based Sentiment Annotation of Patient Comments
Apr 29, 2024Sentiment analysis is an important tool for aggregating patient voices, in order to provide targeted improvements in healthcare services. A prerequisite for this is the availability of in-domain data annotated for sentiment. This article documents an effort to add sentiment annotations to free-text comments in patient surveys collected by the Norwegian Institute of Public Health (NIPH). However, annotation can be a time-consuming and resource-intensive process, particularly when it requires domain expertise. We therefore also evaluate a possible alternative to human annotation, using large language models (LLMs) as annotators. We perform an extensive evaluation of the approach for two openly available pretrained LLMs for Norwegian, experimenting with different configurations of prompts and in-context learning, comparing their performance to human annotators. We find that even for zero-shot runs, models perform well above the baseline for binary sentiment, but still cannot compete with human annotators on the full dataset.
Text-To-KG Alignment: Comparing Current Methods on Classification Tasks
Jun 05, 2023



In contrast to large text corpora, knowledge graphs (KG) provide dense and structured representations of factual information. This makes them attractive for systems that supplement or ground the knowledge found in pre-trained language models with an external knowledge source. This has especially been the case for classification tasks, where recent work has focused on creating pipeline models that retrieve information from KGs like ConceptNet as additional context. Many of these models consist of multiple components, and although they differ in the number and nature of these parts, they all have in common that for some given text query, they attempt to identify and retrieve a relevant subgraph from the KG. Due to the noise and idiosyncrasies often found in KGs, it is not known how current methods compare to a scenario where the aligned subgraph is completely relevant to the query. In this work, we try to bridge this knowledge gap by reviewing current approaches to text-to-KG alignment and evaluating them on two datasets where manually created graphs are available, providing insights into the effectiveness of current methods.
NorBench -- A Benchmark for Norwegian Language Models
May 06, 2023



We present NorBench: a streamlined suite of NLP tasks and probes for evaluating Norwegian language models (LMs) on standardized data splits and evaluation metrics. We also introduce a range of new Norwegian language models (both encoder and encoder-decoder based). Finally, we compare and analyze their performance, along with other existing LMs, across the different benchmark tests of NorBench.
Entity-Level Sentiment Analysis (ELSA): An exploratory task survey
Apr 27, 2023



This paper explores the task of identifying the overall sentiment expressed towards volitional entities (persons and organizations) in a document -- what we refer to as Entity-Level Sentiment Analysis (ELSA). While identifying sentiment conveyed towards an entity is well researched for shorter texts like tweets, we find little to no research on this specific task for longer texts with multiple mentions and opinions towards the same entity. This lack of research would be understandable if ELSA can be derived from existing tasks and models. To assess this, we annotate a set of professional reviews for their overall sentiment towards each volitional entity in the text. We sample from data already annotated for document-level, sentence-level, and target-level sentiment in a multi-domain review corpus, and our results indicate that there is no single proxy task that provides this overall sentiment we seek for the entities at a satisfactory level of performance. We present a suite of experiments aiming to assess the contribution towards ELSA provided by document-, sentence-, and target-level sentiment analysis, and provide a discussion of their shortcomings. We show that sentiment in our dataset is expressed not only with an entity mention as target, but also towards targets with a sentiment-relevant relation to a volitional entity. In our data, these relations extend beyond anaphoric coreference resolution, and our findings call for further research of the topic. Finally, we also present a survey of previous relevant work.
Measuring Normative and Descriptive Biases in Language Models Using Census Data
Apr 12, 2023



We investigate in this paper how distributions of occupations with respect to gender is reflected in pre-trained language models. Such distributions are not always aligned to normative ideals, nor do they necessarily reflect a descriptive assessment of reality. In this paper, we introduce an approach for measuring to what degree pre-trained language models are aligned to normative and descriptive occupational distributions. To this end, we use official demographic information about gender--occupation distributions provided by the national statistics agencies of France, Norway, United Kingdom, and the United States. We manually generate template-based sentences combining gendered pronouns and nouns with occupations, and subsequently probe a selection of ten language models covering the English, French, and Norwegian languages. The scoring system we introduce in this work is language independent, and can be used on any combination of template-based sentences, occupations, and languages. The approach could also be extended to other dimensions of national census data and other demographic variables.
Trained on 100 million words and still in shape: BERT meets British National Corpus
Mar 29, 2023While modern masked language models (LMs) are trained on ever larger corpora, we here explore the effects of down-scaling training to a modestly-sized but representative, well-balanced, and publicly available English text source -- the British National Corpus. We show that pre-training on this carefully curated corpus can reach better performance than the original BERT model. We argue that this type of corpora has great potential as a language modeling benchmark. To showcase this potential, we present fair, reproducible and data-efficient comparative studies of LMs, in which we evaluate several training objectives and model architectures and replicate previous empirical results in a systematic way. We propose an optimized LM architecture called LTG-BERT.
Direct parsing to sentiment graphs
Mar 24, 2022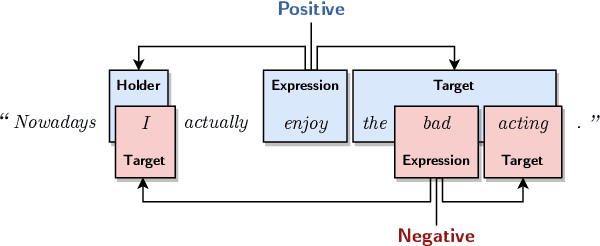
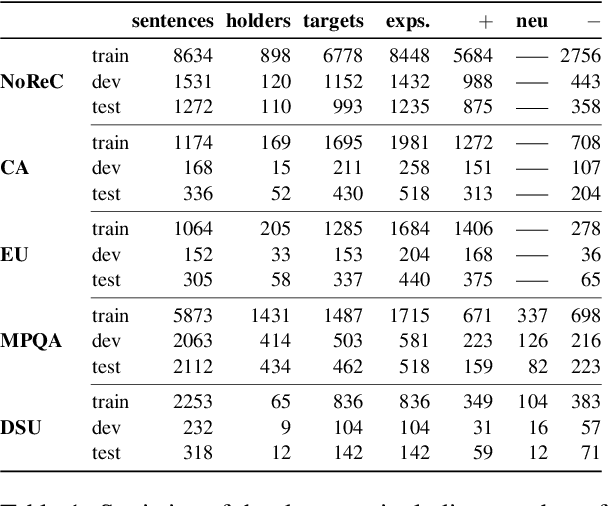
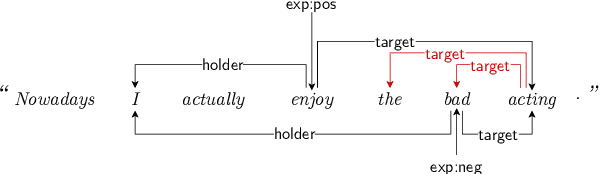
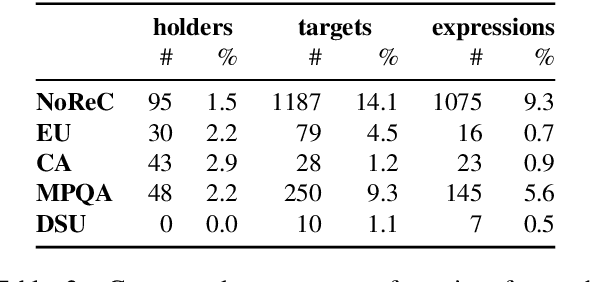
This paper demonstrates how a graph-based semantic parser can be applied to the task of structured sentiment analysis, directly predicting sentiment graphs from text. We advance the state of the art on 4 out of 5 standard benchmark sets. We release the source code, models and predictions.
Structured Sentiment Analysis as Dependency Graph Parsing
May 30, 2021
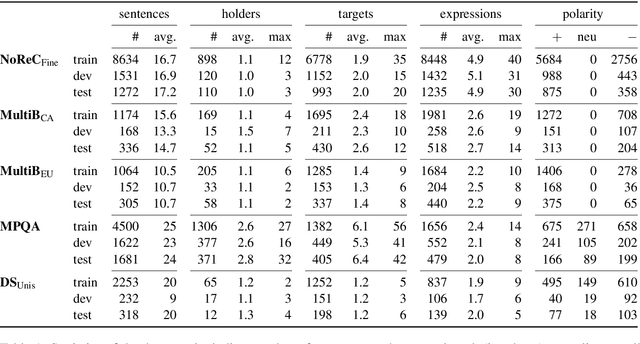
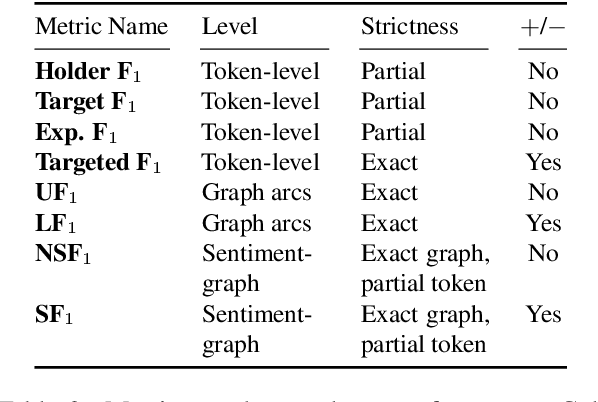
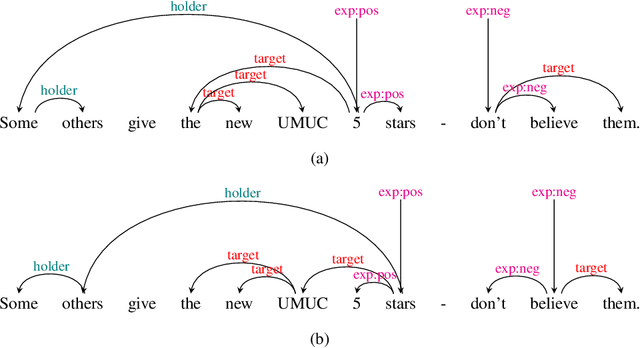
Structured sentiment analysis attempts to extract full opinion tuples from a text, but over time this task has been subdivided into smaller and smaller sub-tasks, e,g,, target extraction or targeted polarity classification. We argue that this division has become counterproductive and propose a new unified framework to remedy the situation. We cast the structured sentiment problem as dependency graph parsing, where the nodes are spans of sentiment holders, targets and expressions, and the arcs are the relations between them. We perform experiments on five datasets in four languages (English, Norwegian, Basque, and Catalan) and show that this approach leads to strong improvements over state-of-the-art baselines. Our analysis shows that refining the sentiment graphs with syntactic dependency information further improves results.
Large-Scale Contextualised Language Modelling for Norwegian
Apr 13, 2021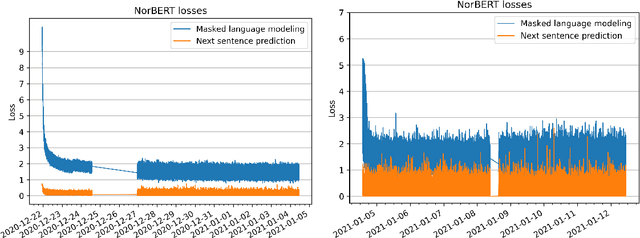
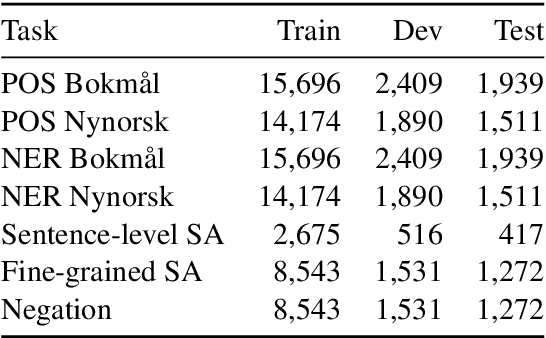
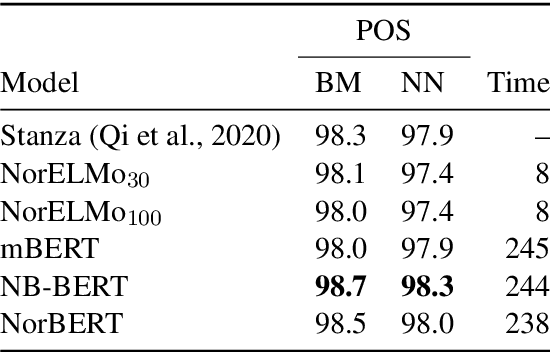
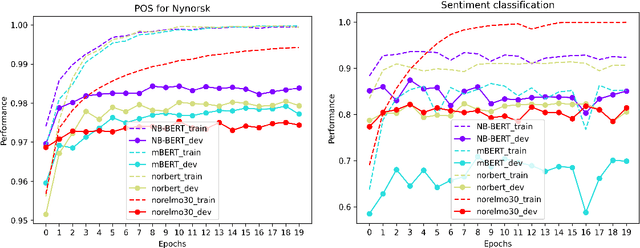
We present the ongoing NorLM initiative to support the creation and use of very large contextualised language models for Norwegian (and in principle other Nordic languages), including a ready-to-use software environment, as well as an experience report for data preparation and training. This paper introduces the first large-scale monolingual language models for Norwegian, based on both the ELMo and BERT frameworks. In addition to detailing the training process, we present contrastive benchmark results on a suite of NLP tasks for Norwegian. For additional background and access to the data, models, and software, please see http://norlm.nlpl.eu