 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond the Answer: Decoding the Behavior of LLMs as Scientific Reasoners
Mar 30, 2026As Large Language Models (LLMs) achieve increasingly sophisticated performance on complex reasoning tasks, current architectures serve as critical proxies for the internal heuristics of frontier models. Characterizing emergent reasoning is vital for long-term interpretability and safety. Furthermore, understanding how prompting modulates these processes is essential, as natural language will likely be the primary interface for interacting with AGI systems. In this work, we use a custom variant of Genetic Pareto (GEPA) to systematically optimize prompts for scientific reasoning tasks, and analyze how prompting can affect reasoning behavior. We investigate the structural patterns and logical heuristics inherent in GEPA-optimized prompts, and evaluate their transferability and brittleness. Our findings reveal that gains in scientific reasoning often correspond to model-specific heuristics that fail to generalize across systems, which we call "local" logic. By framing prompt optimization as a tool for model interpretability, we argue that mapping these preferred reasoning structures for LLMs is an important prerequisite for effectively collaborating with superhuman intelligence.
Speech Representations and Phoneme Classification for Preserving the Endangered Language of Ladin
Aug 27, 2021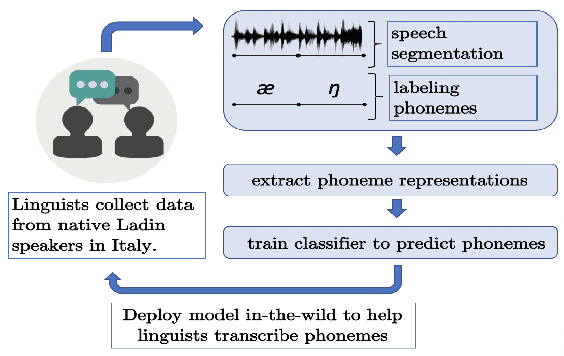
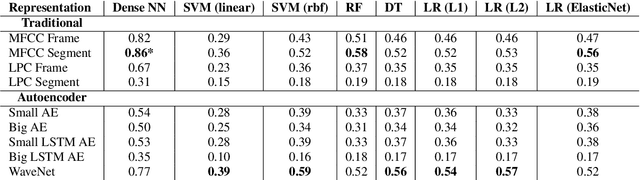
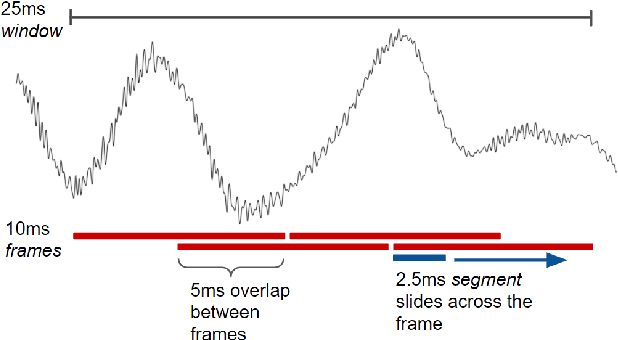
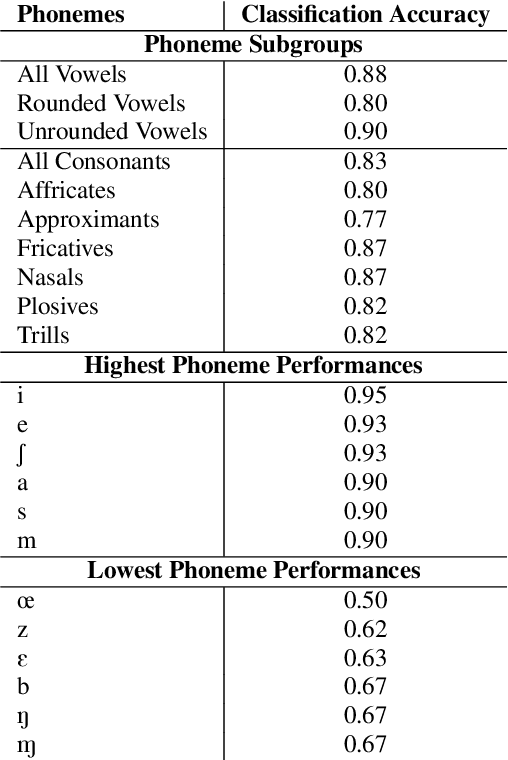
A vast majority of the world's 7,000 spoken languages are predicted to become extinct within this century, including the endangered language of Ladin from the Italian Alps. Linguists who work to preserve a language's phonetic and phonological structure can spend hours transcribing each minute of speech from native speakers. To address this problem in the context of Ladin, our paper presents the first analysis of speech representations and machine learning models for classifying 32 phonemes of Ladin. We experimented with a novel dataset of the Fascian dialect of Ladin, collected from native speakers in Italy. We created frame-level and segment-level speech feature extraction approaches and conducted extensive experiments with 8 different classifiers trained on 9 different speech representations. Our speech representations ranged from traditional features (MFCC, LPC) to features learned with deep neural network models (autoencoders, LSTM autoencoders, and WaveNet). Our highest-performing classifier, trained on MFCC representations of speech signals, achieved an 86% average accuracy across all Ladin phonemes. We also obtained average accuracies above 77% for all Ladin phoneme subgroups examined. Our findings contribute insights for learning discriminative Ladin phoneme representations and demonstrate the potential for leveraging machine learning and speech signal processing to preserve Ladin and other endangered languages.