 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGrounding Spatial Relations in Text-Only Language Models
Mar 20, 2024



This paper shows that text-only Language Models (LM) can learn to ground spatial relations like "left of" or "below" if they are provided with explicit location information of objects and they are properly trained to leverage those locations. We perform experiments on a verbalized version of the Visual Spatial Reasoning (VSR) dataset, where images are coupled with textual statements which contain real or fake spatial relations between two objects of the image. We verbalize the images using an off-the-shelf object detector, adding location tokens to every object label to represent their bounding boxes in textual form. Given the small size of VSR, we do not observe any improvement when using locations, but pretraining the LM over a synthetic dataset automatically derived by us improves results significantly when using location tokens. We thus show that locations allow LMs to ground spatial relations, with our text-only LMs outperforming Vision-and-Language Models and setting the new state-of-the-art for the VSR dataset. Our analysis show that our text-only LMs can generalize beyond the relations seen in the synthetic dataset to some extent, learning also more useful information than that encoded in the spatial rules we used to create the synthetic dataset itself.
Improving Explicit Spatial Relationships in Text-to-Image Generation through an Automatically Derived Dataset
Mar 01, 2024



Existing work has observed that current text-to-image systems do not accurately reflect explicit spatial relations between objects such as 'left of' or 'below'. We hypothesize that this is because explicit spatial relations rarely appear in the image captions used to train these models. We propose an automatic method that, given existing images, generates synthetic captions that contain 14 explicit spatial relations. We introduce the Spatial Relation for Generation (SR4G) dataset, which contains 9.9 millions image-caption pairs for training, and more than 60 thousand captions for evaluation. In order to test generalization we also provide an 'unseen' split, where the set of objects in the train and test captions are disjoint. SR4G is the first dataset that can be used to spatially fine-tune text-to-image systems. We show that fine-tuning two different Stable Diffusion models (denoted as SD$_{SR4G}$) yields up to 9 points improvements in the VISOR metric. The improvement holds in the 'unseen' split, showing that SD$_{SR4G}$ is able to generalize to unseen objects. SD$_{SR4G}$ improves the state-of-the-art with fewer parameters, and avoids complex architectures. Our analysis shows that improvement is consistent for all relations. The dataset and the code will be publicly available.
PixT3: Pixel-based Table To Text generation
Nov 16, 2023



Table-to-Text has been traditionally approached as a linear language to text problem. However, visually represented tables are rich in visual information and serve as a concise, effective form of representing data and its relationships. When using text-based approaches, after the linearization process, this information is either lost or represented in a space inefficient manner. This inefficiency has remained a constant challenge for text-based approaches making them struggle with large tables. In this paper, we demonstrate that image representation of tables are more space-efficient than the typical textual linearizations, and multi-modal approaches are competitive in Table-to-Text tasks. We present PixT3, a multimodal table-to-text model that outperforms the state-of-the-art (SotA) in the ToTTo benchmark in a pure Table-to-Text setting while remaining competitive in controlled Table-to-Text scenarios. It also generalizes better in unseen datasets, outperforming ToTTo SotA in all generation settings. Additionally, we introduce a new intermediate training curriculum to reinforce table structural awareness, leading to improved generation and overall faithfulness of the models.
NLP Evaluation in trouble: On the Need to Measure LLM Data Contamination for each Benchmark
Oct 27, 2023In this position paper, we argue that the classical evaluation on Natural Language Processing (NLP) tasks using annotated benchmarks is in trouble. The worst kind of data contamination happens when a Large Language Model (LLM) is trained on the test split of a benchmark, and then evaluated in the same benchmark. The extent of the problem is unknown, as it is not straightforward to measure. Contamination causes an overestimation of the performance of a contaminated model in a target benchmark and associated task with respect to their non-contaminated counterparts. The consequences can be very harmful, with wrong scientific conclusions being published while other correct ones are discarded. This position paper defines different levels of data contamination and argues for a community effort, including the development of automatic and semi-automatic measures to detect when data from a benchmark was exposed to a model, and suggestions for flagging papers with conclusions that are compromised by data contamination.
Automatic Logical Forms improve fidelity in Table-to-Text generation
Oct 26, 2023



Table-to-text systems generate natural language statements from structured data like tables. While end-to-end techniques suffer from low factual correctness (fidelity), a previous study reported gains when using manual logical forms (LF) that represent the selected content and the semantics of the target text. Given the manual step, it was not clear whether automatic LFs would be effective, or whether the improvement came from content selection alone. We present TlT which, given a table and a selection of the content, first produces LFs and then the textual statement. We show for the first time that automatic LFs improve quality, with an increase in fidelity of 30 points over a comparable system not using LFs. Our experiments allow to quantify the remaining challenges for high factual correctness, with automatic selection of content coming first, followed by better Logic-to-Text generation and, to a lesser extent, better Table-to-Logic parsing.
Unsupervised Domain Adaption for Neural Information Retrieval
Oct 13, 2023Neural information retrieval requires costly annotated data for each target domain to be competitive. Synthetic annotation by query generation using Large Language Models or rule-based string manipulation has been proposed as an alternative, but their relative merits have not been analysed. In this paper, we compare both methods head-to-head using the same neural IR architecture. We focus on the BEIR benchmark, which includes test datasets from several domains with no training data, and explore two scenarios: zero-shot, where the supervised system is trained in a large out-of-domain dataset (MS-MARCO); and unsupervised domain adaptation, where, in addition to MS-MARCO, the system is fine-tuned in synthetic data from the target domain. Our results indicate that Large Language Models outperform rule-based methods in all scenarios by a large margin, and, more importantly, that unsupervised domain adaptation is effective compared to applying a supervised IR system in a zero-shot fashion. In addition we explore several sizes of open Large Language Models to generate synthetic data and find that a medium-sized model suffices. Code and models are publicly available for reproducibility.
GoLLIE: Annotation Guidelines improve Zero-Shot Information-Extraction
Oct 06, 2023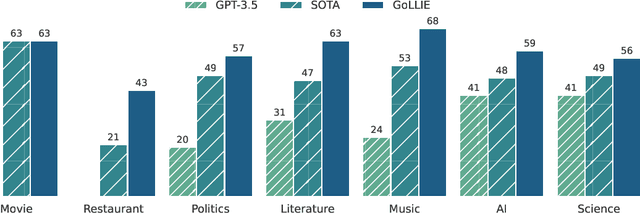
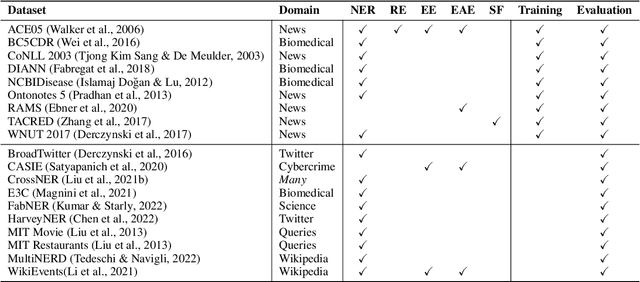

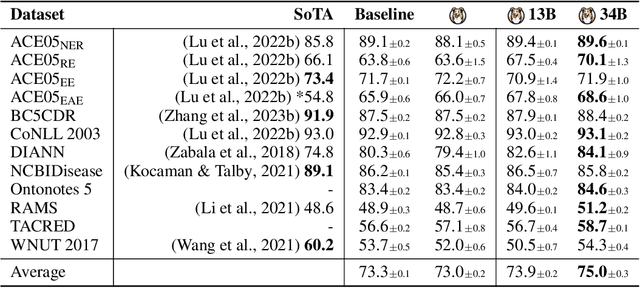
Large Language Models (LLMs) combined with instruction tuning have made significant progress when generalizing to unseen tasks. However, they have been less successful in Information Extraction (IE), lagging behind task-specific models. Typically, IE tasks are characterized by complex annotation guidelines which describe the task and give examples to humans. Previous attempts to leverage such information have failed, even with the largest models, as they are not able to follow the guidelines out-of-the-box. In this paper we propose GoLLIE (Guideline-following Large Language Model for IE), a model able to improve zero-shot results on unseen IE tasks by virtue of being fine-tuned to comply with annotation guidelines. Comprehensive evaluation empirically demonstrates that GoLLIE is able to generalize to and follow unseen guidelines, outperforming previous attempts at zero-shot information extraction. The ablation study shows that detailed guidelines is key for good results.
CombLM: Adapting Black-Box Language Models through Small Fine-Tuned Models
May 23, 2023



Methods for adapting language models (LMs) to new tasks and domains have traditionally assumed white-box access to the model, and work by modifying its parameters. However, this is incompatible with a recent trend in the field, where the highest quality models are only available as black-boxes through inference APIs. Even when the model weights are available, the computational cost of fine-tuning large LMs can be prohibitive for most practitioners. In this work, we present a lightweight method for adapting large LMs to new domains and tasks, assuming no access to their weights or intermediate activations. Our approach fine-tunes a small white-box LM and combines it with the large black-box LM at the probability level through a small network, learned on a small validation set. We validate our approach by adapting a large LM (OPT-30B) to several domains and a downstream task (machine translation), observing improved performance in all cases, of up to 9%, while using a domain expert 23x smaller.
What do Language Models know about word senses? Zero-Shot WSD with Language Models and Domain Inventories
Feb 07, 2023



Language Models are the core for almost any Natural Language Processing system nowadays. One of their particularities is their contextualized representations, a game changer feature when a disambiguation between word senses is necessary. In this paper we aim to explore to what extent language models are capable of discerning among senses at inference time. We performed this analysis by prompting commonly used Languages Models such as BERT or RoBERTa to perform the task of Word Sense Disambiguation (WSD). We leverage the relation between word senses and domains, and cast WSD as a textual entailment problem, where the different hypothesis refer to the domains of the word senses. Our results show that this approach is indeed effective, close to supervised systems.
Lessons learned from the evaluation of Spanish Language Models
Dec 16, 2022
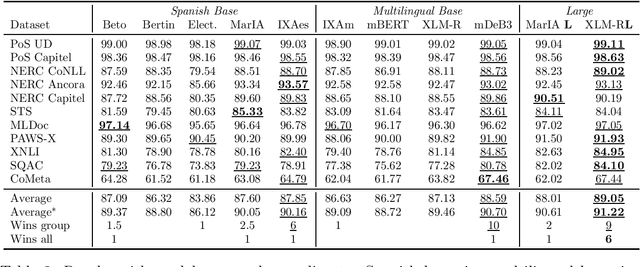

Given the impact of language models on the field of Natural Language Processing, a number of Spanish encoder-only masked language models (aka BERTs) have been trained and released. These models were developed either within large projects using very large private corpora or by means of smaller scale academic efforts leveraging freely available data. In this paper we present a comprehensive head-to-head comparison of language models for Spanish with the following results: (i) Previously ignored multilingual models from large companies fare better than monolingual models, substantially changing the evaluation landscape of language models in Spanish; (ii) Results across the monolingual models are not conclusive, with supposedly smaller and inferior models performing competitively. Based on these empirical results, we argue for the need of more research to understand the factors underlying them. In this sense, the effect of corpus size, quality and pre-training techniques need to be further investigated to be able to obtain Spanish monolingual models significantly better than the multilingual ones released by large private companies, specially in the face of rapid ongoing progress in the field. The recent activity in the development of language technology for Spanish is to be welcomed, but our results show that building language models remains an open, resource-heavy problem which requires to marry resources (monetary and/or computational) with the best research expertise and practice.