 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmpirically Understanding the Value of Prediction in Allocation
Feb 09, 2026Institutions increasingly use prediction to allocate scarce resources. From a design perspective, better predictions compete with other investments, such as expanding capacity or improving treatment quality. Here, the big question is not how to solve a specific allocation problem, but rather which problem to solve. In this work, we develop an empirical toolkit to help planners form principled answers to this question and quantify the bottom-line welfare impact of investments in prediction versus other policy levers such as expanding capacity and improving treatment quality. Applying our framework in two real-world case studies on German employment services and poverty targeting in Ethiopia, we illustrate how decision-makers can reliably derive context-specific conclusions about the relative value of prediction in their allocation problem. We make our software toolkit, rvp, and parts of our data available in order to enable future empirical work in this area.
Fairness and representation in satellite-based poverty maps: Evidence of urban-rural disparities and their impacts on downstream policy
May 02, 2023



Poverty maps derived from satellite imagery are increasingly used to inform high-stakes policy decisions, such as the allocation of humanitarian aid and the distribution of government resources. Such poverty maps are typically constructed by training machine learning algorithms on a relatively modest amount of ``ground truth" data from surveys, and then predicting poverty levels in areas where imagery exists but surveys do not. Using survey and satellite data from ten countries, this paper investigates disparities in representation, systematic biases in prediction errors, and fairness concerns in satellite-based poverty mapping across urban and rural lines, and shows how these phenomena affect the validity of policies based on predicted maps. Our findings highlight the importance of careful error and bias analysis before using satellite-based poverty maps in real-world policy decisions.
Can Strategic Data Collection Improve the Performance of Poverty Prediction Models?
Nov 16, 2022

Machine learning-based estimates of poverty and wealth are increasingly being used to guide the targeting of humanitarian aid and the allocation of social assistance. However, the ground truth labels used to train these models are typically borrowed from existing surveys that were designed to produce national statistics -- not to train machine learning models. Here, we test whether adaptive sampling strategies for ground truth data collection can improve the performance of poverty prediction models. Through simulations, we compare the status quo sampling strategies (uniform at random and stratified random sampling) to alternatives that prioritize acquiring training data based on model uncertainty or model performance on sub-populations. Perhaps surprisingly, we find that none of these active learning methods improve over uniform-at-random sampling. We discuss how these results can help shape future efforts to refine machine learning-based estimates of poverty.
Program Targeting with Machine Learning and Mobile Phone Data: Evidence from an Anti-Poverty Intervention in Afghanistan
Jun 22, 2022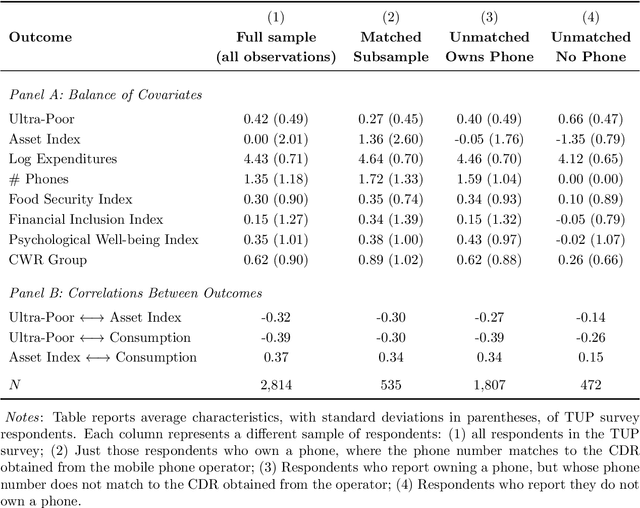
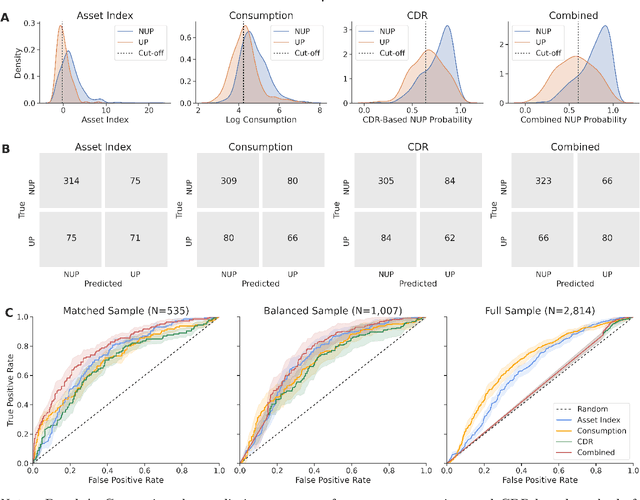
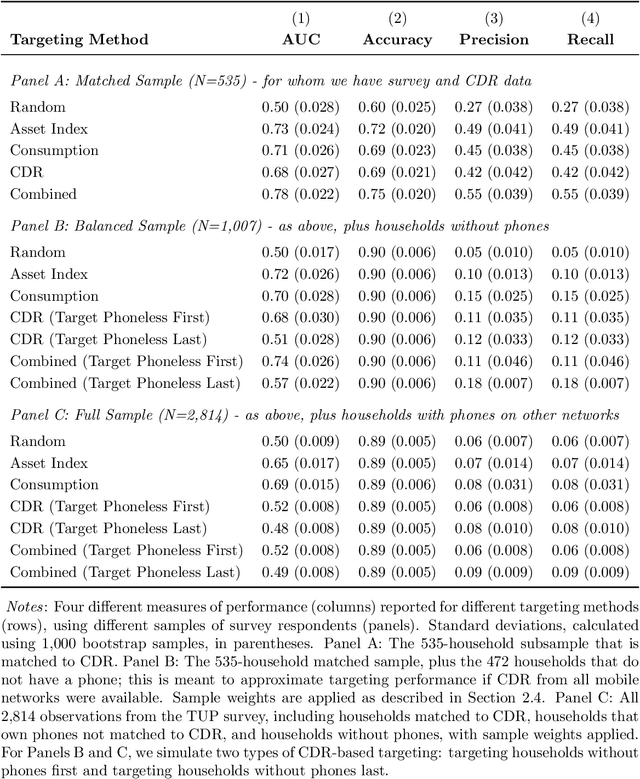
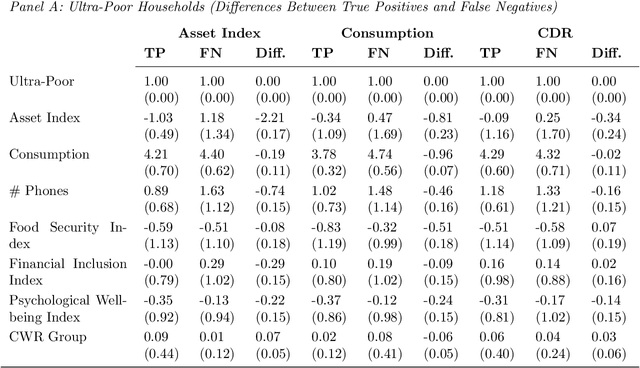
Can mobile phone data improve program targeting? By combining rich survey data from a "big push" anti-poverty program in Afghanistan with detailed mobile phone logs from program beneficiaries, we study the extent to which machine learning methods can accurately differentiate ultra-poor households eligible for program benefits from ineligible households. We show that machine learning methods leveraging mobile phone data can identify ultra-poor households nearly as accurately as survey-based measures of consumption and wealth; and that combining survey-based measures with mobile phone data produces classifications more accurate than those based on a single data source.