 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivity Detection in Distributed Massive MIMO With Pilot-Hopping and Activity Correlation
Nov 17, 2022Many real-world scenarios for massive machine-type communication involve sensors monitoring a physical phenomenon. As a consequence, the activity pattern of these sensors will be correlated. In this letter, we study how the correlation of user activities can be exploited to improve detection performance in grant-free random access systems where the users transmit pilot-hopping sequences and the detection is performed based on the received energy. We show that we can expect considerable performance gains by adding regularizers, which take the activity correlation into account, to the non-negative least squares, which has been shown to work well for independent user activity.
Combining Reciprocity and CSI Feedback in MIMO Systems
May 04, 2022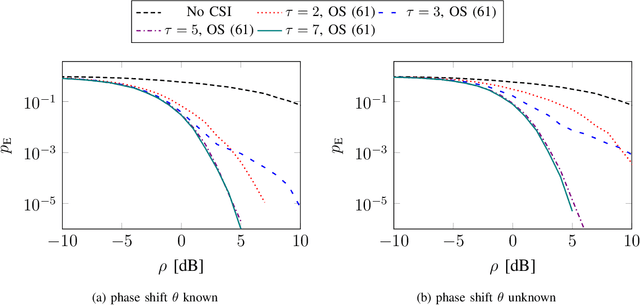
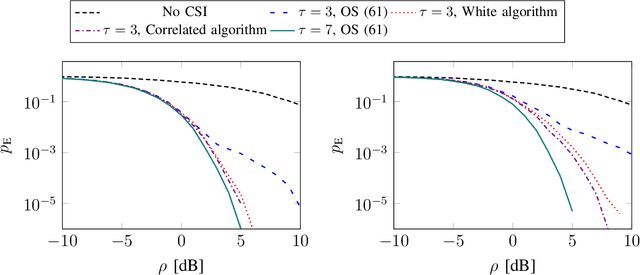
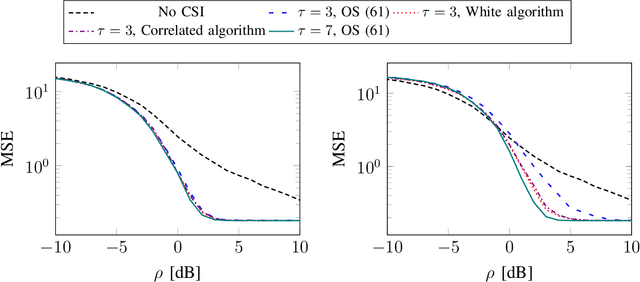
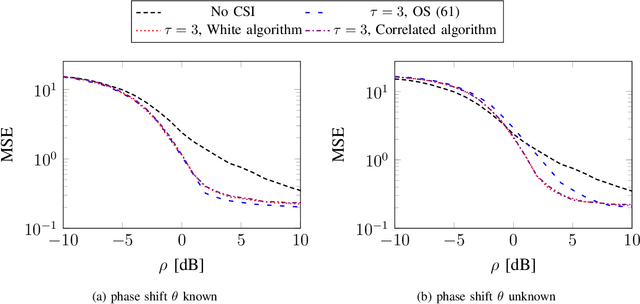
Reciprocity-based time-division duplex (TDD) Massive MIMO (multiple-input multiple-output) systems utilize channel estimates obtained in the uplink to perform precoding in the downlink. However, this method has been criticized of breaking down, in the sense that the channel estimates are not good enough to spatially separate multiple user terminals, at low uplink reference signal signal-to-noise ratios, due to insufficient channel estimation quality. Instead, codebook-based downlink precoding has been advocated for as an alternative solution in order to bypass this problem. We analyze this problem by considering a "grid-of-beams world" with a finite number of possible downlink channel realizations. Assuming that the terminal accurately can detect the downlink channel, we show that in the case where reciprocity holds, carefully designing a mapping between the downlink channel and the uplink reference signals will perform better than both the conventional TDD Massive MIMO and frequency-division duplex (FDD) Massive MIMO approach. We derive elegant metrics for designing this mapping, and further, we propose algorithms that find good sequence mappings.
Optimal MIMO Combining for Blind Federated Edge Learning with Gradient Sparsification
Mar 24, 2022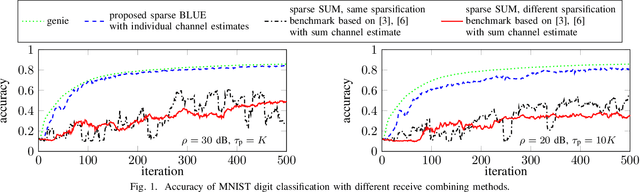
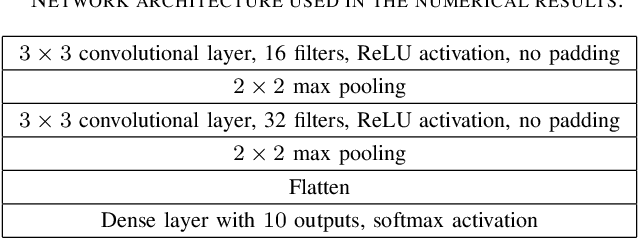
We provide the optimal receive combining strategy for federated learning in multiple-input multiple-output (MIMO) systems. Our proposed algorithm allows the clients to perform individual gradient sparsification which greatly improves performance in scenarios with heterogeneous (non i.i.d.) training data. The proposed method beats the benchmark by a wide margin.