 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAge Predictors Through the Lens of Generalization, Bias Mitigation, and Interpretability: Reflections on Causal Implications
Mar 17, 2026Chronological age predictors often fail to achieve out-of-distribution (OOD) gen- eralization due to exogenous attributes such as race, gender, or tissue. Learning an invariant representation with respect to those attributes is therefore essential to improve OOD generalization and prevent overly optimistic results. In predic- tive settings, these attributes motivate bias mitigation; in causal analyses, they appear as confounders; and when protected, their suppression leads to fairness. We coherently explore these concepts with theoretical rigor and discuss the scope of an interpretable neural network model based on adversarial representation learning. Using publicly available mouse transcriptomic datasets, we illustrate the behavior of this model relative to conventional machine learning models. We observe that the outcome of this model is consistent with the predictive results of a published study demonstrating the effects of Elamipretide on mouse skeletal and cardiac muscle. We conclude by discussing the limitations of deriving causal interpretation from such purely predictive models.
A causal learning framework for the analysis and interpretation of COVID-19 clinical data
May 14, 2021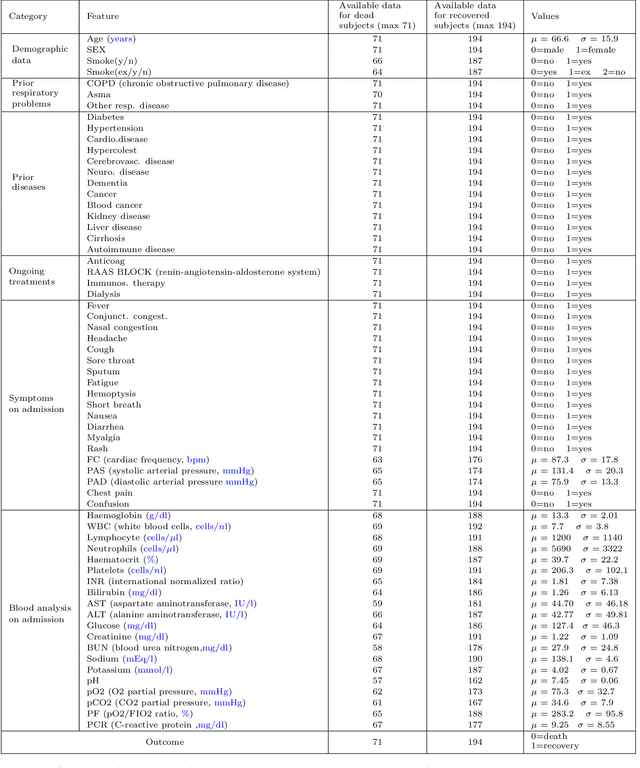
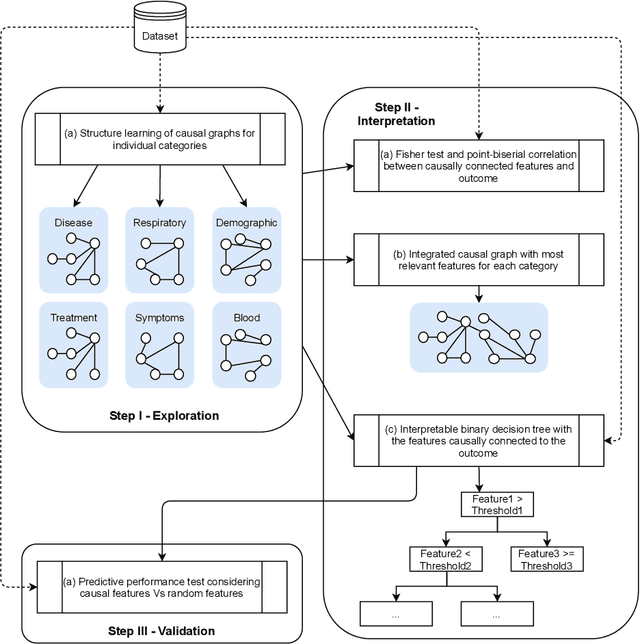
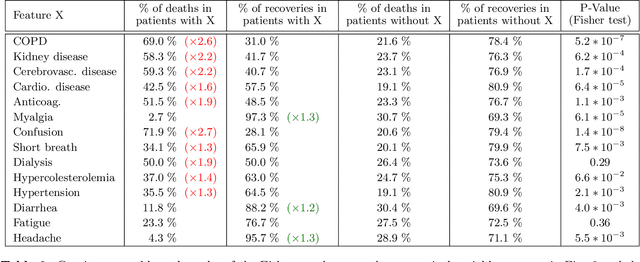
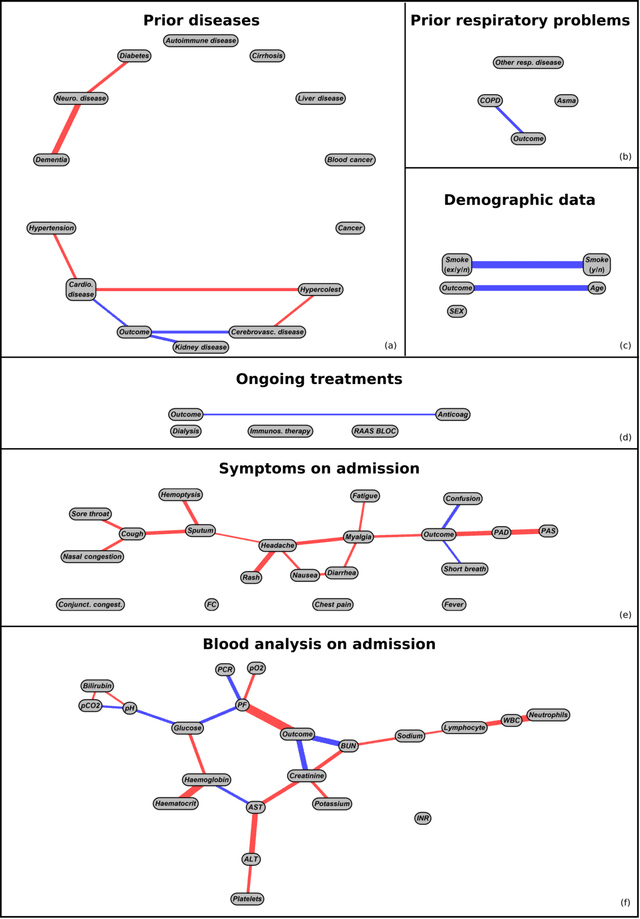
We present a workflow for clinical data analysis that relies on Bayesian Structure Learning (BSL), an unsupervised learning approach, robust to noise and biases, that allows to incorporate prior medical knowledge into the learning process and that provides explainable results in the form of a graph showing the causal connections among the analyzed features. The workflow consists in a multi-step approach that goes from identifying the main causes of patient's outcome through BSL, to the realization of a tool suitable for clinical practice, based on a Binary Decision Tree (BDT), to recognize patients at high-risk with information available already at hospital admission time. We evaluate our approach on a feature-rich COVID-19 dataset, showing that the proposed framework provides a schematic overview of the multi-factorial processes that jointly contribute to the outcome. We discuss how these computational findings are confirmed by current understanding of the COVID-19 pathogenesis. Further, our approach yields to a highly interpretable tool correctly predicting the outcome of 85% of subjects based exclusively on 3 features: age, a previous history of chronic obstructive pulmonary disease and the PaO2/FiO2 ratio at the time of arrival to the hospital. The inclusion of additional information from 4 routine blood tests (Creatinine, Glucose, pO2 and Sodium) increases predictive accuracy to 94.5%.
Addressing Fairness, Bias and Class Imbalance in Machine Learning: the FBI-loss
May 13, 2021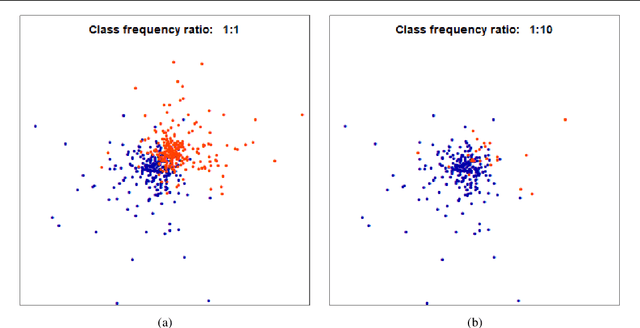
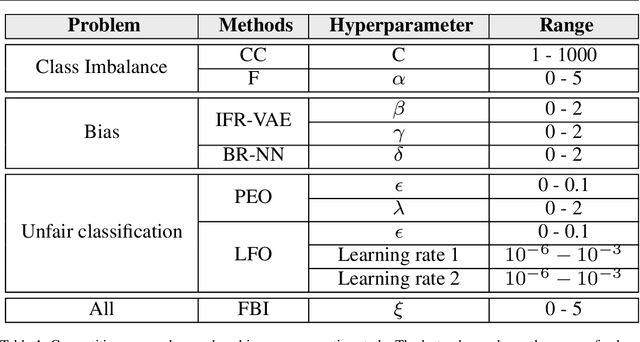
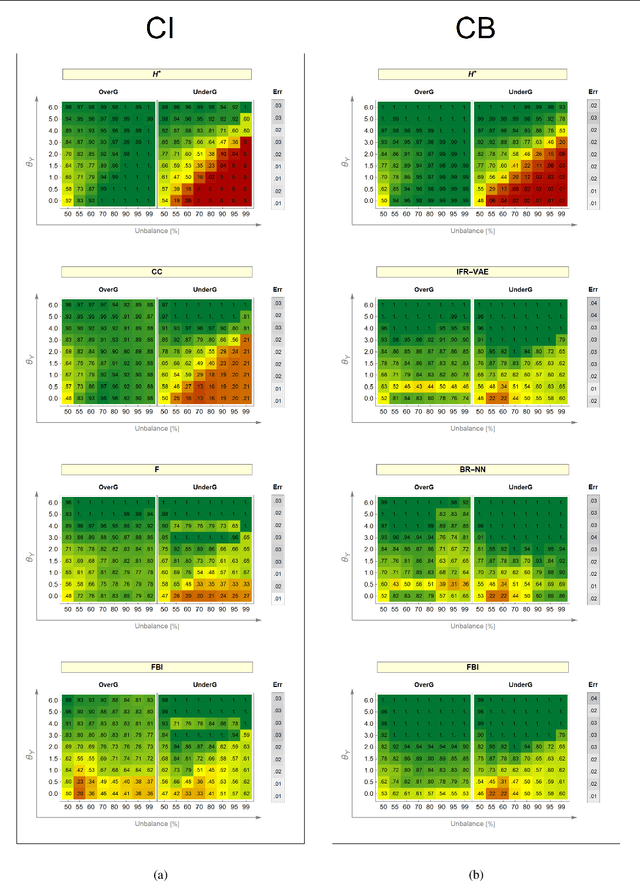
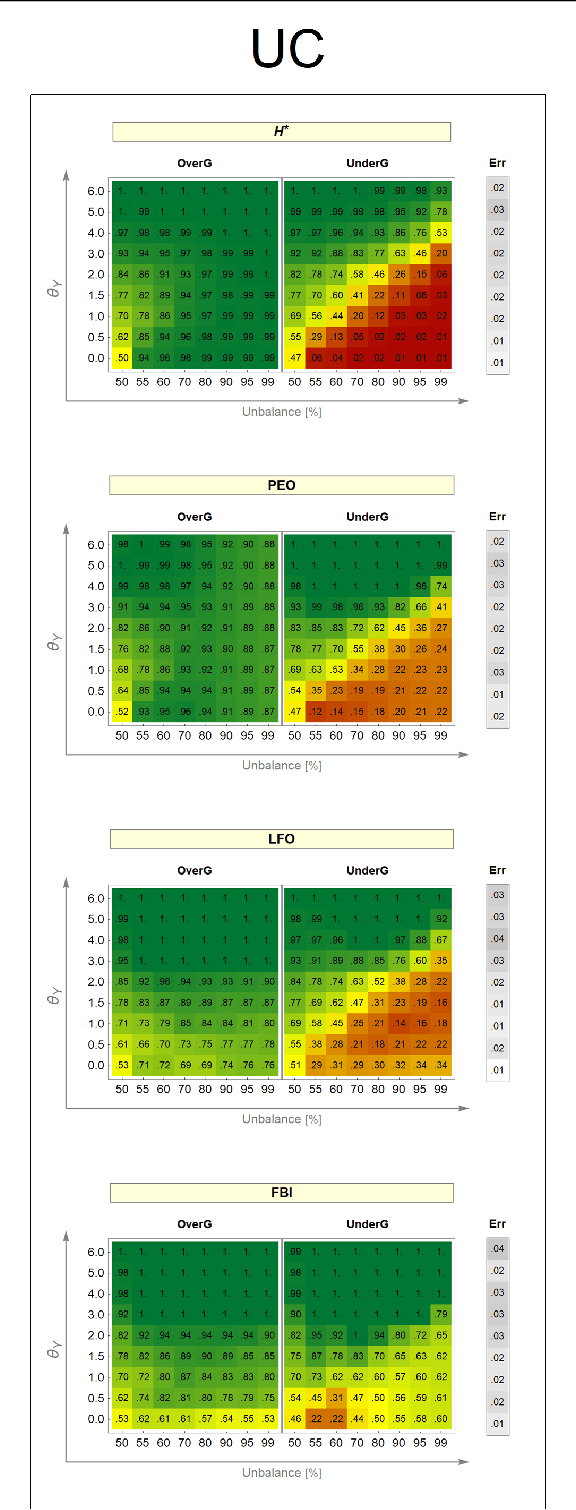
Resilience to class imbalance and confounding biases, together with the assurance of fairness guarantees are highly desirable properties of autonomous decision-making systems with real-life impact. Many different targeted solutions have been proposed to address separately these three problems, however a unifying perspective seems to be missing. With this work, we provide a general formalization, showing that they are different expressions of unbalance. Following this intuition, we formulate a unified loss correction to address issues related to Fairness, Biases and Imbalances (FBI-loss). The correction capabilities of the proposed approach are assessed on three real-world benchmarks, each associated to one of the issues under consideration, and on a family of synthetic data in order to better investigate the effectiveness of our loss on tasks with different complexities. The empirical results highlight that the flexible formulation of the FBI-loss leads also to competitive performances with respect to literature solutions specialised for the single problems.
Measuring the effects of confounders in medical supervised classification problems: the Confounding Index (CI)
May 21, 2019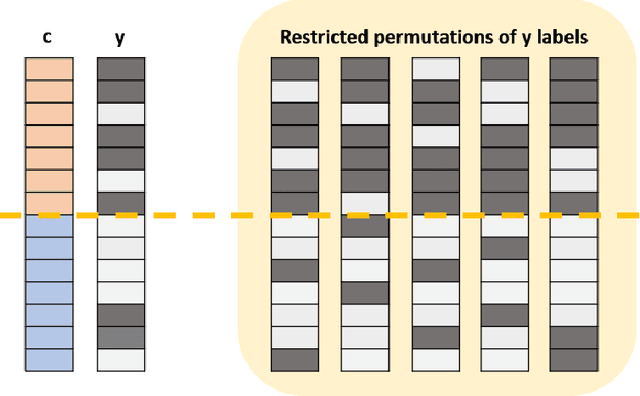

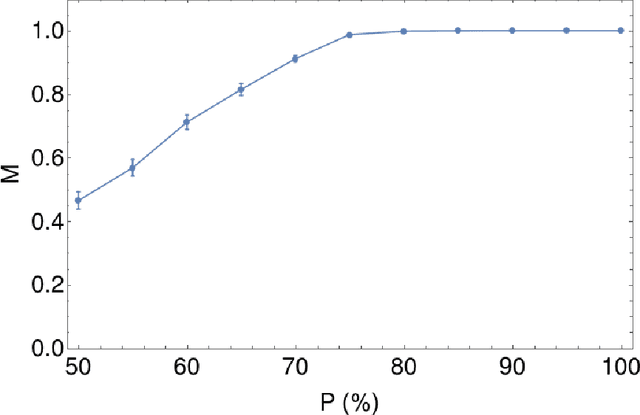
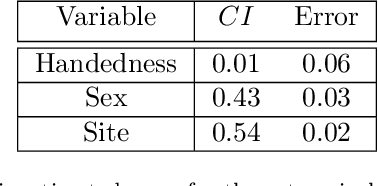
Over the years, there has been growing interest in using Machine Learning techniques for biomedical data processing. When tackling these tasks, one needs to bear in mind that biomedical data depends on a variety of characteristics, such as demographic aspects (age, gender, etc) or the acquisition technology, which might be unrelated with the target of the analysis. In supervised tasks, failing to match the ground truth targets with respect to such characteristics, called confounders, may lead to very misleading estimates of the predictive performance. Many strategies have been proposed to handle confounders, ranging from data selection, to normalization techniques, up to the use of training algorithm for learning with imbalanced data. However, all these solutions require the confounders to be known a priori. To this aim, we introduce a novel index that is able to measure the confounding effect of a data attribute in a bias-agnostic way. This index can be used to quantitatively compare the confounding effects of different variables and to inform correction methods such as normalization procedures or ad-hoc-prepared learning algorithms. The effectiveness of this index is validated on both simulated data and real-world neuroimaging data.