 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantification of pulmonary involvement in COVID-19 pneumonia by means of a cascade oftwo U-nets: training and assessment on multipledatasets using different annotation criteria
May 06, 2021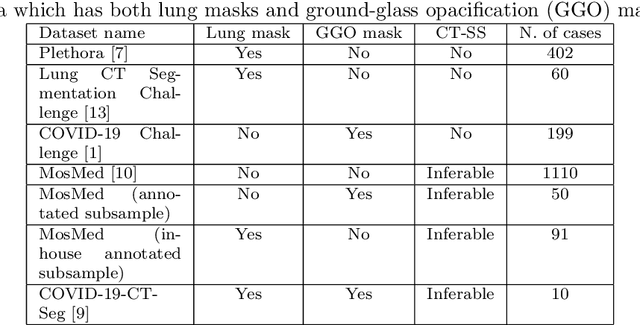
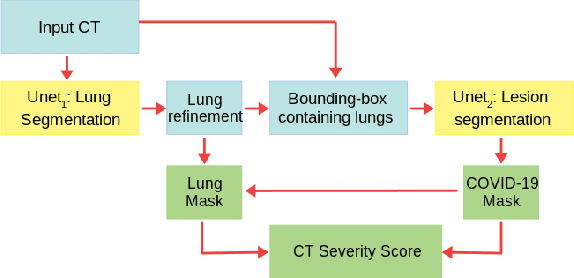
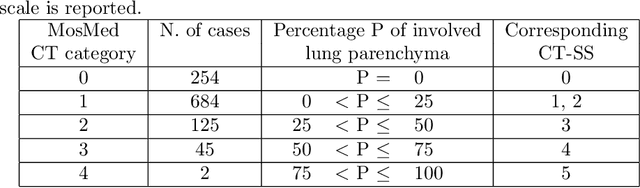
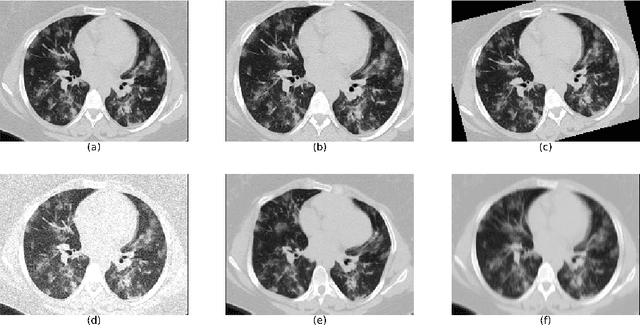
The automatic assignment of a severity score to the CT scans of patients affected by COVID-19 pneumonia could reduce the workload in radiology departments. This study aims at exploiting Artificial intelligence (AI) for the identification, segmentation and quantification of COVID-19 pulmonary lesions. We investigated the effects of using multiple datasets, heterogeneously populated and annotated according to different criteria. We developed an automated analysis pipeline, the LungQuant system, based on a cascade of two U-nets. The first one (U-net_1) is devoted to the identification of the lung parenchyma, the second one (U-net_2) acts on a bounding box enclosing the segmented lungs to identify the areas affected by COVID-19 lesions. Different public datasets were used to train the U-nets and to evaluate their segmentation performances, which have been quantified in terms of the Dice index. The accuracy in predicting the CT-Severity Score (CT-SS) of the LungQuant system has been also evaluated. Both Dice and accuracy showed a dependency on the quality of annotations of the available data samples. On an independent and publicly available benchmark dataset, the Dice values measured between the masks predicted by LungQuant system and the reference ones were 0.95$\pm$0.01 and 0.66$\pm$0.13 for the segmentation of lungs and COVID-19 lesions, respectively. The accuracy of 90% in the identification of the CT-SS on this benchmark dataset was achieved. We analysed the impact of using data samples with different annotation criteria in training an AI-based quantification system for pulmonary involvement in COVID-19 pneumonia. In terms of the Dice index, the U-net segmentation quality strongly depends on the quality of the lesion annotations. Nevertheless, the CT-SS can be accurately predicted on independent validation sets, demonstrating the satisfactory generalization ability of the LungQuant.
Measuring the effects of confounders in medical supervised classification problems: the Confounding Index (CI)
May 21, 2019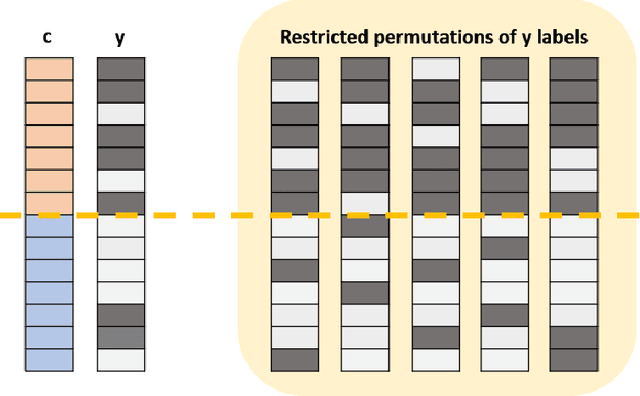

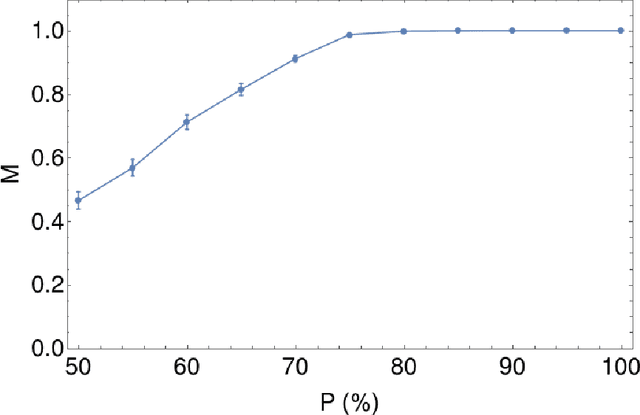
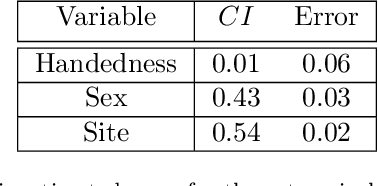
Over the years, there has been growing interest in using Machine Learning techniques for biomedical data processing. When tackling these tasks, one needs to bear in mind that biomedical data depends on a variety of characteristics, such as demographic aspects (age, gender, etc) or the acquisition technology, which might be unrelated with the target of the analysis. In supervised tasks, failing to match the ground truth targets with respect to such characteristics, called confounders, may lead to very misleading estimates of the predictive performance. Many strategies have been proposed to handle confounders, ranging from data selection, to normalization techniques, up to the use of training algorithm for learning with imbalanced data. However, all these solutions require the confounders to be known a priori. To this aim, we introduce a novel index that is able to measure the confounding effect of a data attribute in a bias-agnostic way. This index can be used to quantitatively compare the confounding effects of different variables and to inform correction methods such as normalization procedures or ad-hoc-prepared learning algorithms. The effectiveness of this index is validated on both simulated data and real-world neuroimaging data.