 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlaytesting: What is Beyond Personas
Jul 26, 2021
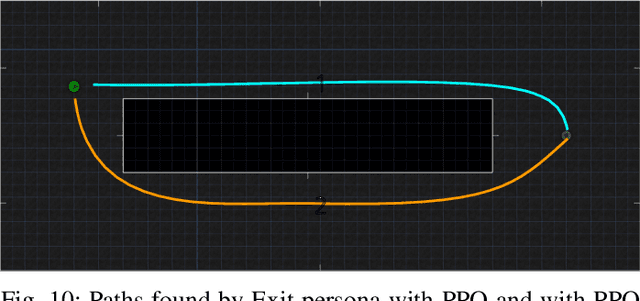
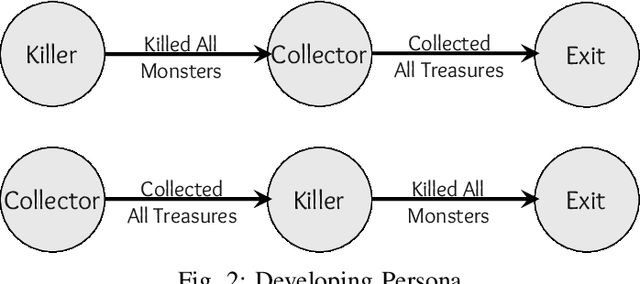
Playtesting is an essential step in the game design process. Game designers use the feedback from playtests to refine their design. Game designers may employ procedural personas to automate the playtesting process. In this paper, we present two approaches to improve automated playtesting. First, we propose a goal-based persona model, which we call developing persona -- developing persona proposes a dynamic persona model, whereas the current persona models are static. Game designers can use the developing persona to model the changes that a player undergoes while playing a game. Additionally, a human playtester knows which paths she has tested before, and during the consequent tests, she may test different paths. However, RL agents disregard the previously generated trajectories. We propose a novel methodology that helps Reinforcement Learning (RL) agents to generate distinct trajectories than the previous trajectories. We refer to this methodology as Alternative Path Finder (APF). We present a generic APF framework that can be applied to all RL agents. APF is trained with the previous trajectories, and APF distinguishes the novel states from similar states. We use the General Video Game Artificial Intelligence (GVG-AI) and VizDoom frameworks to test our proposed methodologies. We use Proximal Policy Optimization (PPO) RL agent during experiments. First, we show that the playtest data generated by the developing persona cannot be generated using the procedural personas. Second, we present the alternative paths found using APF. We show that the APF penalizes the previous paths and rewards the distinct paths.
Relational-Grid-World: A Novel Relational Reasoning Environment and An Agent Model for Relational Information Extraction
Jul 12, 2020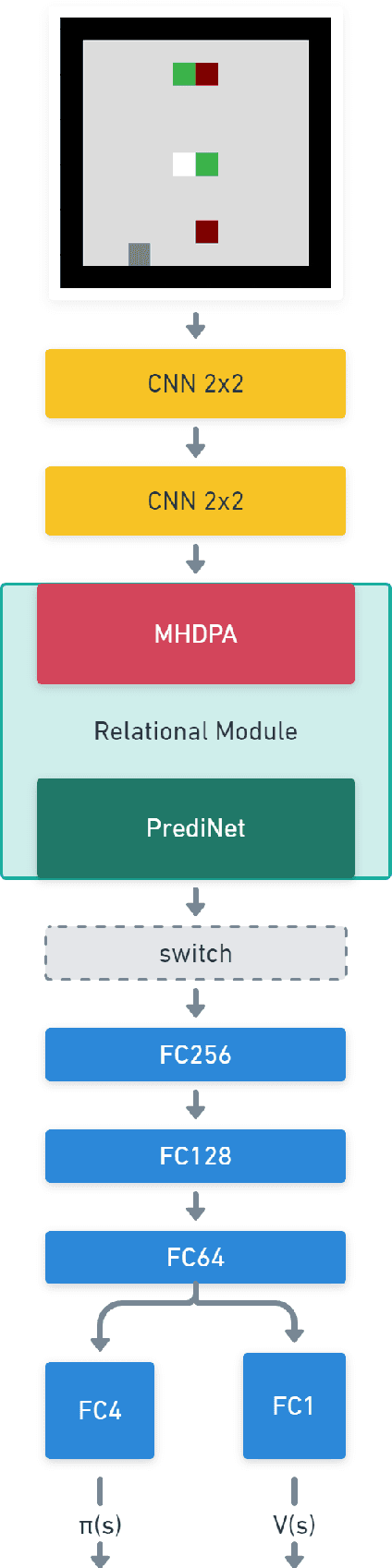
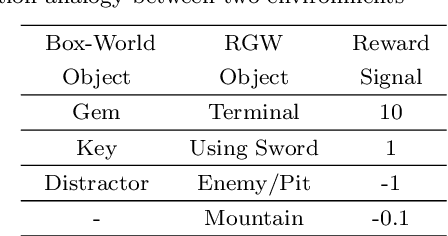
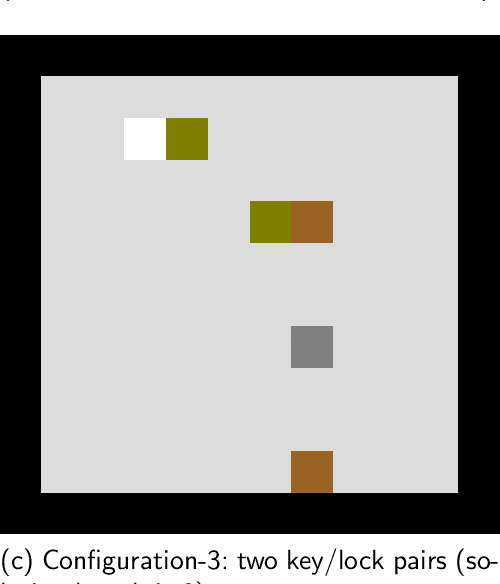
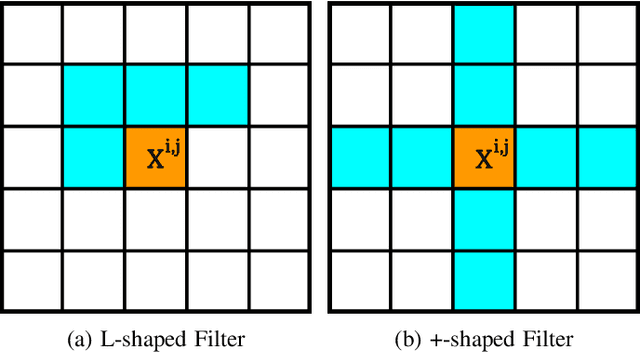
Reinforcement learning (RL) agents are often designed specifically for a particular problem and they generally have uninterpretable working processes. Statistical methods-based agent algorithms can be improved in terms of generalizability and interpretability using symbolic Artificial Intelligence (AI) tools such as logic programming. In this study, we present a model-free RL architecture that is supported with explicit relational representations of the environmental objects. For the first time, we use the PrediNet network architecture in a dynamic decision-making problem rather than image-based tasks, and Multi-Head Dot-Product Attention Network (MHDPA) as a baseline for performance comparisons. We tested two networks in two environments ---i.e., the baseline Box-World environment and our novel environment, Relational-Grid-World (RGW). With the procedurally generated RGW environment, which is complex in terms of visual perceptions and combinatorial selections, it is easy to measure the relational representation performance of the RL agents. The experiments were carried out using different configurations of the environment so that the presented module and the environment were compared with the baselines. We reached similar policy optimization performance results with the PrediNet architecture and MHDPA; additionally, we achieved to extract the propositional representation explicitly ---which makes the agent's statistical policy logic more interpretable and tractable. This flexibility in the agent's policy provides convenience for designing non-task-specific agent architectures. The main contributions of this study are two-fold ---an RL agent that can explicitly perform relational reasoning, and a new environment that measures the relational reasoning capabilities of RL agents.
Using Generative Adversarial Nets on Atari Games for Feature Extraction in Deep Reinforcement Learning
Apr 06, 2020Deep Reinforcement Learning (DRL) has been successfully applied in several research domains such as robot navigation and automated video game playing. However, these methods require excessive computation and interaction with the environment, so enhancements on sample efficiency are required. The main reason for this requirement is that sparse and delayed rewards do not provide an effective supervision for representation learning of deep neural networks. In this study, Proximal Policy Optimization (PPO) algorithm is augmented with Generative Adversarial Networks (GANs) to increase the sample efficiency by enforcing the network to learn efficient representations without depending on sparse and delayed rewards as supervision. The results show that an increased performance can be obtained by jointly training a DRL agent with a GAN discriminator. ---- Derin Pekistirmeli Ogrenme, robot navigasyonu ve otomatiklestirilmis video oyunu oynama gibi arastirma alanlarinda basariyla uygulanmaktadir. Ancak, kullanilan yontemler ortam ile fazla miktarda etkilesim ve hesaplama gerektirmekte ve bu nedenle de ornek verimliligi yonunden iyilestirmelere ihtiyac duyulmaktadir. Bu gereksinimin en onemli nedeni, gecikmeli ve seyrek odul sinyallerinin derin yapay sinir aglarinin etkili betimlemeler ogrenebilmesi icin yeterli bir denetim saglayamamasidir. Bu calismada, Proksimal Politika Optimizasyonu algoritmasi Uretici Cekismeli Aglar (UCA) ile desteklenerek derin yapay sinir aglarinin seyrek ve gecikmeli odul sinyallerine bagimli olmaksizin etkili betimlemeler ogrenmesi tesvik edilmektedir. Elde edilen sonuclar onerilen algoritmanin ornek verimliliginde artis elde ettigini gostermektedir.
Enhancing the Monte Carlo Tree Search Algorithm for Video Game Testing
Mar 17, 2020
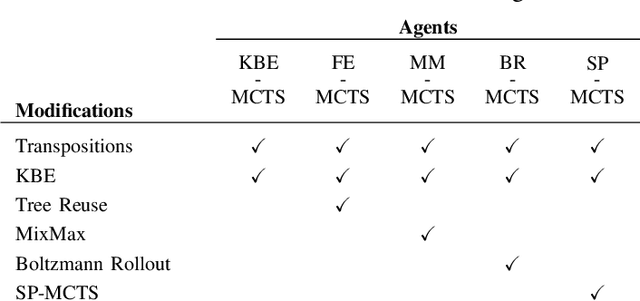
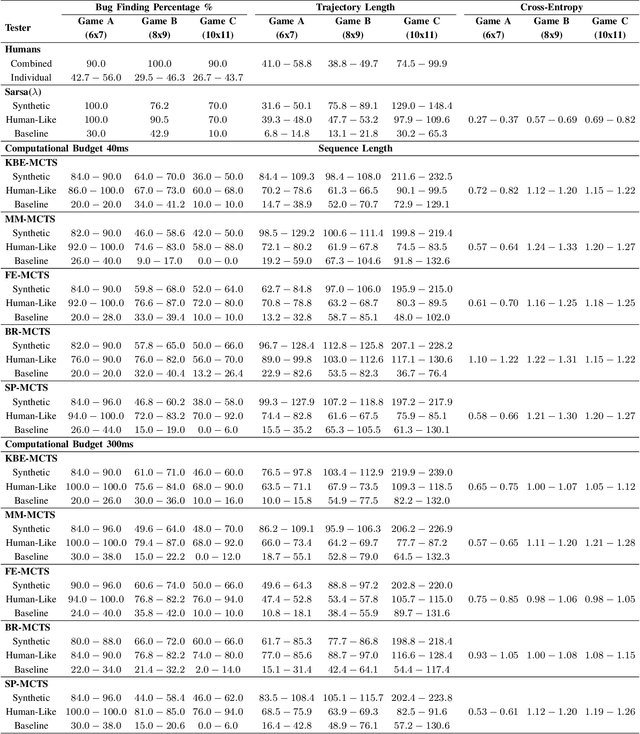
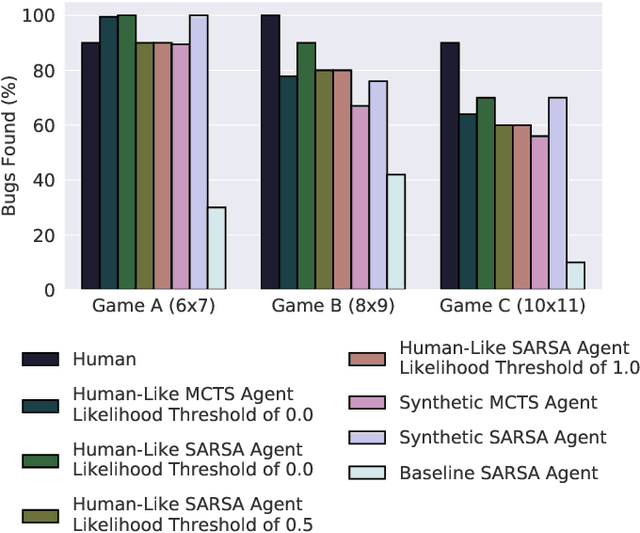
In this paper, we study the effects of several Monte Carlo Tree Search (MCTS) modifications for video game testing. Although MCTS modifications are highly studied in game playing, their impacts on finding bugs are blank. We focused on bug finding in our previous study where we introduced synthetic and human-like test goals and we used these test goals in Sarsa and MCTS agents to find bugs. In this study, we extend the MCTS agent with several modifications for game testing purposes. Furthermore, we present a novel tree reuse strategy. We experiment with these modifications by testing them on three testbed games, four levels each, that contain 45 bugs in total. We use the General Video Game Artificial Intelligence (GVG-AI) framework to create the testbed games and collect 427 human tester trajectories using the GVG-AI framework. We analyze the proposed modifications in three parts: we evaluate their effects on bug finding performances of agents, we measure their success under two different computational budgets, and we assess their effects on human-likeness of the human-like agent. Our results show that MCTS modifications improve the bug finding performance of the agents.
Automated Video Game Testing Using Synthetic and Human-Like Agents
Jun 02, 2019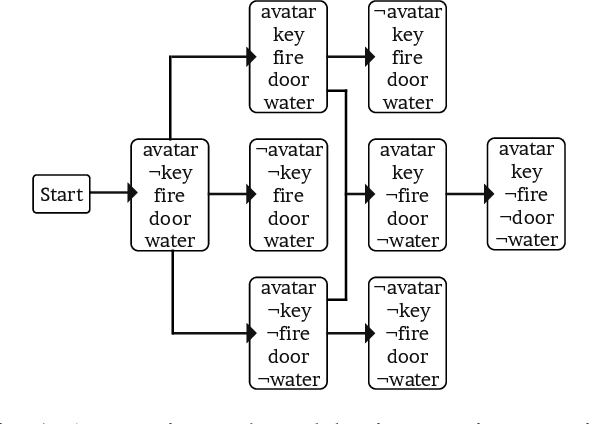

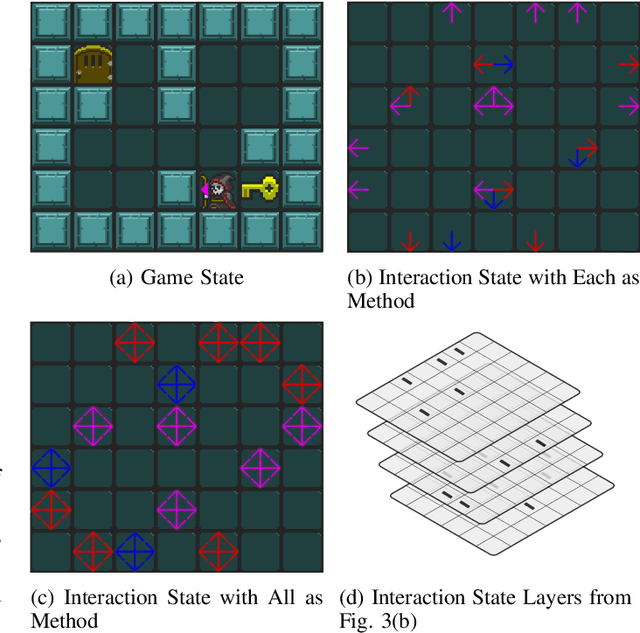
In this paper, we present a new methodology that employs tester agents to automate video game testing. We introduce two types of agents -synthetic and human-like- and two distinct approaches to create them. Our agents are derived from Reinforcement Learning (RL) and Monte Carlo Tree Search (MCTS) agents, but focus on finding defects. The synthetic agent uses test goals generated from game scenarios, and these goals are further modified to examine the effects of unintended game transitions. The human-like agent uses test goals extracted by our proposed multiple greedy-policy inverse reinforcement learning (MGP-IRL) algorithm from tester trajectories. MGPIRL captures multiple policies executed by human testers. These testers' aims are finding defects while interacting with the game to break it, which is considerably different from game playing. We present interaction states to model such interactions. We use our agents to produce test sequences, run the game with these sequences, and check the game for each run with an automated test oracle. We analyze the proposed method in two parts: we compare the success of human-like and synthetic agents in bug finding, and we evaluate the similarity between humanlike agents and human testers. We collected 427 trajectories from human testers using the General Video Game Artificial Intelligence (GVG-AI) framework and created three games with 12 levels that contain 45 bugs. Our experiments reveal that human-like and synthetic agents compete with human testers' bug finding performances. Moreover, we show that MGP-IRL increases the human-likeness of agents while improving the bug finding performance.
Multi-modal Egocentric Activity Recognition using Audio-Visual Features
Jul 02, 2018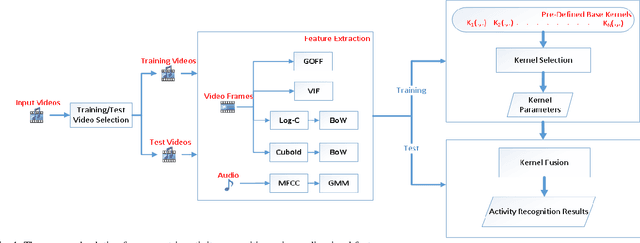
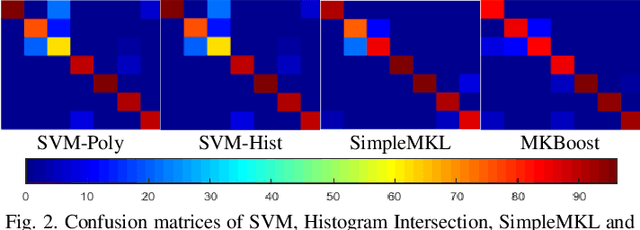
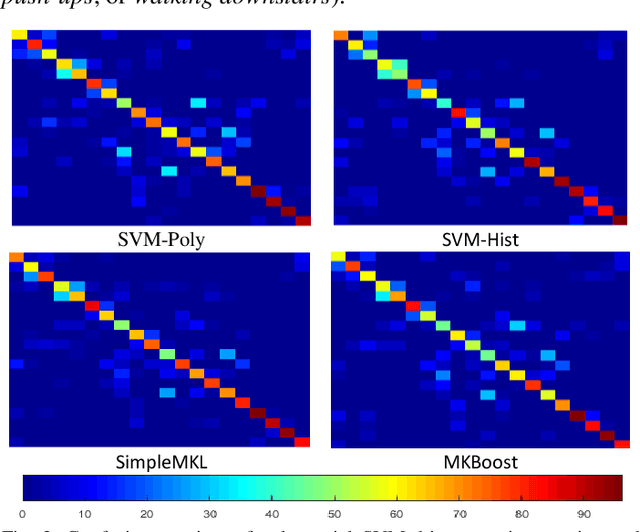
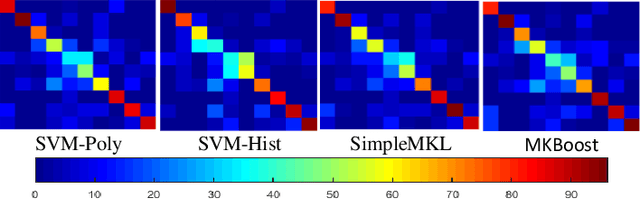
Egocentric activity recognition in first-person videos has an increasing importance with a variety of applications such as lifelogging, summarization, assisted-living and activity tracking. Existing methods for this task are based on interpretation of various sensor information using pre-determined weights for each feature. In this work, we propose a new framework for egocentric activity recognition problem based on combining audio-visual features with multi-kernel learning (MKL) and multi-kernel boosting (MKBoost). For that purpose, firstly grid optical-flow, virtual-inertia feature, log-covariance, cuboid are extracted from the video. The audio signal is characterized using a "supervector", obtained based on Gaussian mixture modelling of frame-level features, followed by a maximum a-posteriori adaptation. Then, the extracted multi-modal features are adaptively fused by MKL classifiers in which both the feature and kernel selection/weighing and recognition tasks are performed together. The proposed framework was evaluated on a number of egocentric datasets. The results showed that using multi-modal features with MKL outperforms the existing methods.
Boosted Multiple Kernel Learning for First-Person Activity Recognition
Jun 05, 2017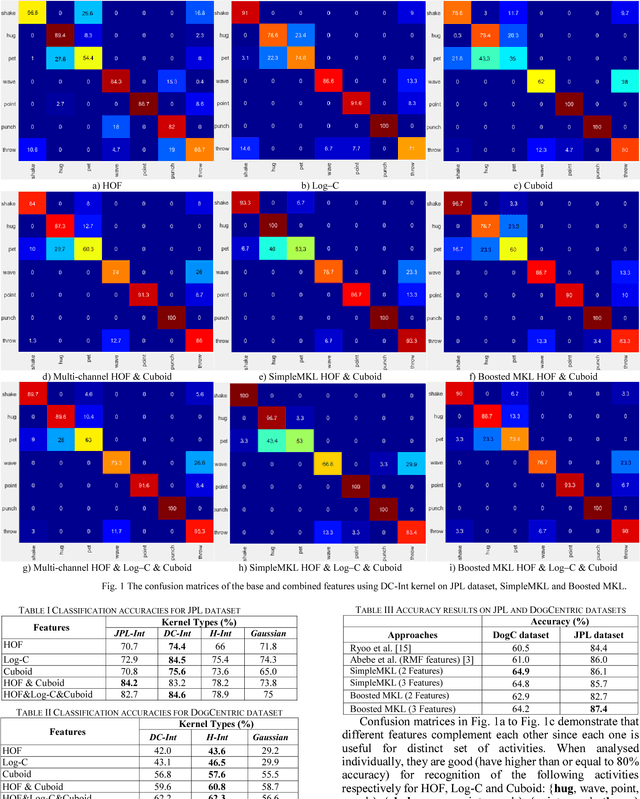
Activity recognition from first-person (ego-centric) videos has recently gained attention due to the increasing ubiquity of the wearable cameras. There has been a surge of efforts adapting existing feature descriptors and designing new descriptors for the first-person videos. An effective activity recognition system requires selection and use of complementary features and appropriate kernels for each feature. In this study, we propose a data-driven framework for first-person activity recognition which effectively selects and combines features and their respective kernels during the training. Our experimental results show that use of Multiple Kernel Learning (MKL) and Boosted MKL in first-person activity recognition problem exhibits improved results in comparison to the state-of-the-art. In addition, these techniques enable the expansion of the framework with new features in an efficient and convenient way.