 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Scalable and Near-Optimal Conformance Checking Approach for Long Traces
Jun 08, 2024Long traces and large event logs that originate from sensors and prediction models are becoming more common in our data-rich world. In such circumstances, conformance checking, a key task in process mining, can become computationally infeasible due to the exponential complexity of finding an optimal alignment. This paper introduces a novel sliding window approach to address these scalability challenges while preserving the interpretability of alignment-based methods. By breaking down traces into manageable subtraces and iteratively aligning each with the process model, our method significantly reduces the search space. The approach uses global information that captures structural properties of the trace and the process model to make informed alignment decisions, discarding unpromising alignments even if they are optimal for a local subtrace. This improves the overall accuracy of the results. Experimental evaluations demonstrate that the proposed method consistently finds optimal alignments in most cases and highlight its scalability. This is further supported by a theoretical complexity analysis, which shows the reduced growth of the search space compared to other common conformance checking methods. This work provides a valuable contribution towards efficient conformance checking for large-scale process mining applications.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
Trace Recovery from Stochastically Known Logs
Jun 25, 2022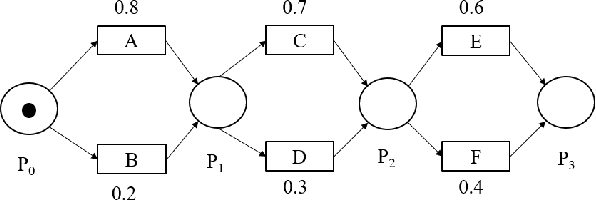
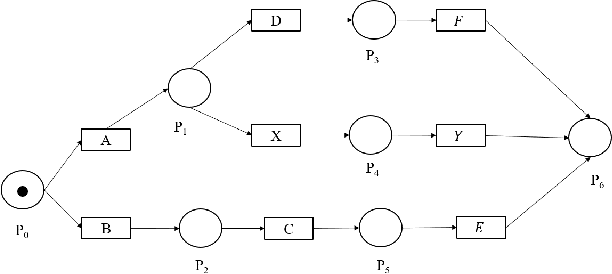
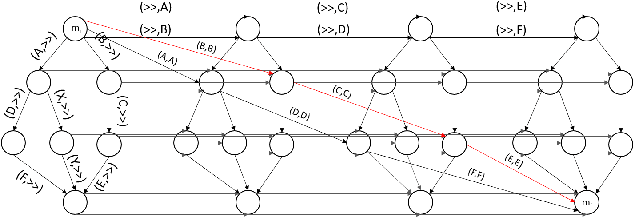
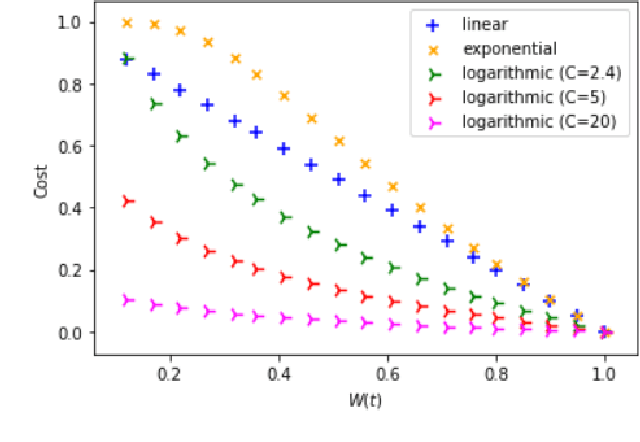
In this work we propose an algorithm for trace recovery from stochastically known logs, a setting that is becoming more common with the increasing number of sensors and predictive models that generate uncertain data. The suggested approach calculates the conformance between a process model and a stochastically known trace and recovers the best alignment within this stochastic trace as the true trace. The paper offers an analysis of the impact of various cost models on trace recovery accuracy and makes use of a product multi-graph to compare alternative trace recovery options. The average accuracy of our approach, evaluated using two publicly available datasets, is impressive, with an average recovery accuracy score of 90-97%, significantly improving a common heuristic that chooses the most likely value for each uncertain activity. We believe that the effectiveness of the proposed algorithm in recovering correct traces from stochastically known logs may be a powerful aid for developing credible decision-making tools in uncertain settings.
Conformance Checking Over Stochastically Known Logs
Mar 14, 2022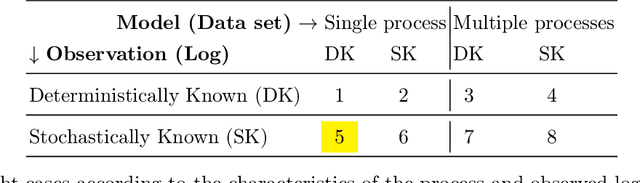
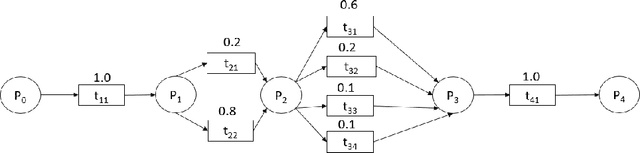
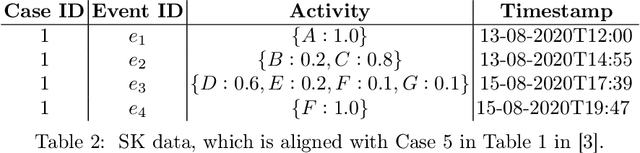
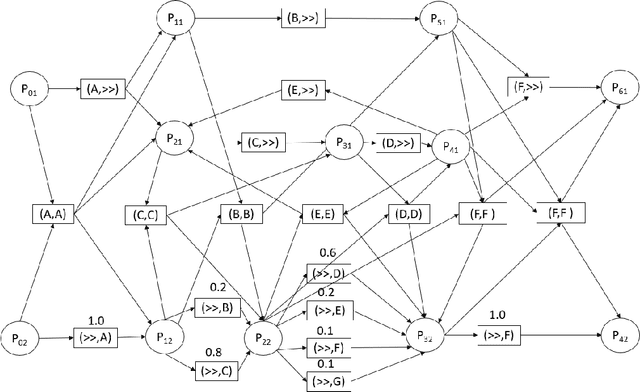
With the growing number of devices, sensors and digital systems, data logs may become uncertain due to, e.g., sensor reading inaccuracies or incorrect interpretation of readings by processing programs. At times, such uncertainties can be captured stochastically, especially when using probabilistic data classification models. In this work we focus on conformance checking, which compares a process model with an event log, when event logs are stochastically known. Building on existing alignment-based conformance checking fundamentals, we mathematically define a stochastic trace model, a stochastic synchronous product, and a cost function that reflects the uncertainty of events in a log. Then, we search for an optimal alignment over the reachability graph of the stochastic synchronous product for finding an optimal alignment between a model and a stochastic process observation. Via structured experiments with two well-known process mining benchmarks, we explore the behavior of the suggested stochastic conformance checking approach and compare it to a standard alignment-based approach as well as to an approach that creates a lower bound on performance. We envision the proposed stochastic conformance checking approach as a viable process mining component for future analysis of stochastic event logs.