 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEstLLM: Enhancing Estonian Capabilities in Multilingual LLMs via Continued Pretraining and Post-Training
Mar 02, 2026Large language models (LLMs) are predominantly trained on English-centric data, resulting in uneven performance for smaller languages. We study whether continued pretraining (CPT) can substantially improve Estonian capabilities in a pretrained multilingual LLM while preserving its English and general reasoning performance. Using Llama 3.1 8B as the main base model, we perform CPT on a mixture that increases Estonian exposure while approximating the original training distribution through English replay and the inclusion of code, mathematics, and instruction-like data. We subsequently apply supervised fine-tuning, preference optimization, and chat vector merging to introduce robust instruction-following behavior. Evaluation on a comprehensive suite of Estonian benchmarks shows consistent gains in linguistic competence, knowledge, reasoning, translation quality, and instruction-following compared to the original base model and its instruction-tuned variant, while maintaining competitive performance on English benchmarks. These findings indicate that CPT, with an appropriately balanced data mixture, together with post-training alignment, can substantially improve single-language capabilities in pretrained multilingual LLMs.
Structure-Tags Improve Text Classification for Scholarly Document Quality Prediction
Apr 30, 2020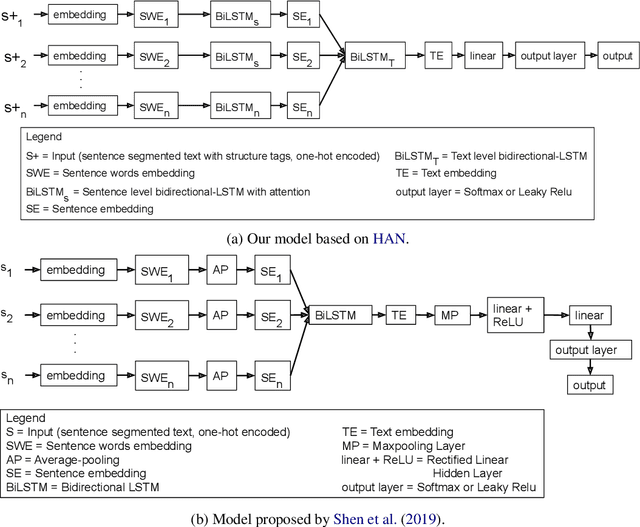

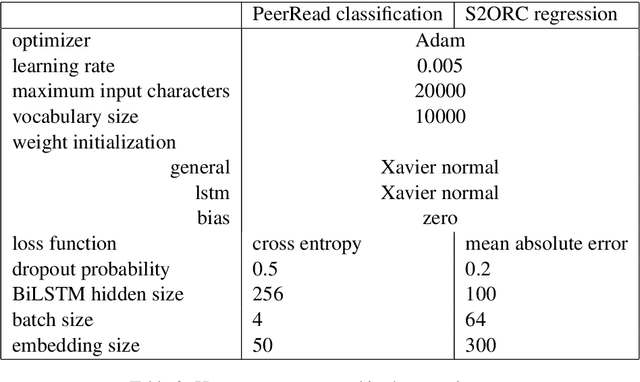
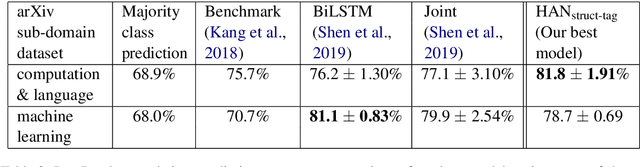
Training recurrent neural networks on long texts, in particular scholarly documents, causes problems for learning. While hierarchical attention networks (HANs) are effective in solving these problems, they still lose important information about the structure of the text. To tackle these problems, we propose the use of HANs combined with structure-tags which mark the role of sentences in the document. Adding tags to sentences, marking them as corresponding to title, abstract or main body text, yields improvements over the state-of-the-art for scholarly document quality prediction: substantial gains on average against other models and consistent improvements over HANs without structure-tags. The proposed system is applied to the task of accept/reject prediction on the PeerRead dataset and compared against a recent BiLSTM-based model and joint textual+visual model. It gains 4.7% accuracy over the best of both models on the computation and language domain and loses 2.4% against the best of both on the machine learning domain. Compared to plain HANs, accuracy increases on both domains, with 1.5% and 2% respectively. We also obtain improvements when introducing the tags for prediction of the number of citations for 88k scientific publications that we compiled from the Allen AI S2ORC dataset. For our HAN-system with structure-tags we reach 28.5% explained variance, an improvement of 1.0% over HANs without structure-tags.