 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMCTED: A Machine-Learning-Ready Dataset for Digital Elevation Model Generation From Mars Imagery
Sep 09, 2025This work presents a new dataset for the Martian digital elevation model prediction task, ready for machine learning applications called MCTED. The dataset has been generated using a comprehensive pipeline designed to process high-resolution Mars orthoimage and DEM pairs from Day et al., yielding a dataset consisting of 80,898 data samples. The source images are data gathered by the Mars Reconnaissance Orbiter using the CTX instrument, providing a very diverse and comprehensive coverage of the Martian surface. Given the complexity of the processing pipelines used in large-scale DEMs, there are often artefacts and missing data points in the original data, for which we developed tools to solve or mitigate their impact. We divide the processed samples into training and validation splits, ensuring samples in both splits cover no mutual areas to avoid data leakage. Every sample in the dataset is represented by the optical image patch, DEM patch, and two mask patches, indicating values that were originally missing or were altered by us. This allows future users of the dataset to handle altered elevation regions as they please. We provide statistical insights of the generated dataset, including the spatial distribution of samples, the distributions of elevation values, slopes and more. Finally, we train a small U-Net architecture on the MCTED dataset and compare its performance to a monocular depth estimation foundation model, DepthAnythingV2, on the task of elevation prediction. We find that even a very small architecture trained on this dataset specifically, beats a zero-shot performance of a depth estimation foundation model like DepthAnythingV2. We make the dataset and code used for its generation completely open source in public repositories.
Volumetric Calculation of Quantization Error in 3-D Vision Systems
Oct 16, 2020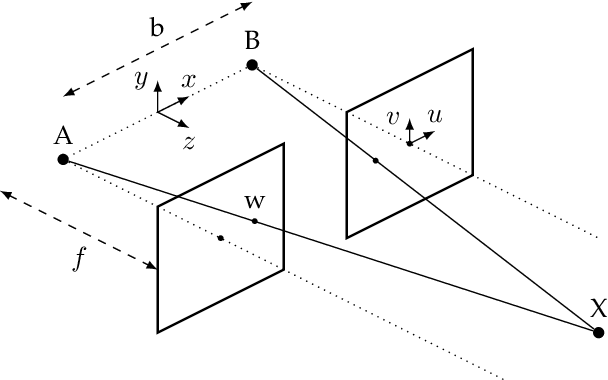

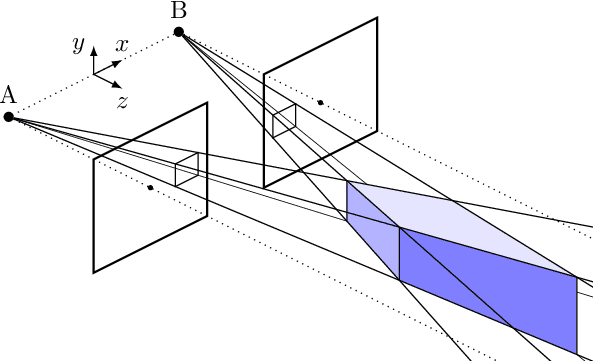
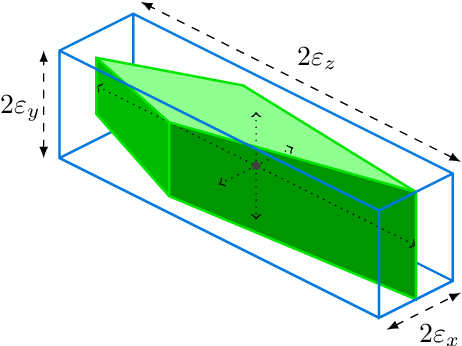
This paper investigates how the inherent quantization of camera sensors introduces uncertainty in the calculated position of an observed feature during 3-D mapping. It is typically assumed that pixels and scene features are points, however, a pixel is a two-dimensional area that maps onto multiple points in the scene. This uncertainty region is a bound for quantization error in the calculated point positions. Earlier studies calculated the volume of two intersecting pixel views, approximated as a cuboid, by projecting pyramids and cones from the pixels into the scene. In this paper, we reverse this approach by generating an array of scene points and calculating which scene points are detected by which pixel in each camera. This enables us to map the uncertainty regions for every pixel correspondence for a given camera system in one calculation, without approximating the complex shapes. The dependence of the volumes of the uncertainty regions on camera baseline length, focal length, pixel size, and distance to object, shows that earlier studies overestimated the quantization error by at least a factor of two. For static camera systems the method can also be used to determine volumetric scene geometry without the need to calculate disparity maps.