 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuPPET: A Benchmark for Contextual Privacy of LLM Assistants in Multi-Party Conversations
Jun 22, 2026LLM agents are increasingly deployed in multi-party environments, handling sensitive personal data on behalf of individual users, for instance in group chats. When such an agent discloses private information, it reaches every group member at once. This risk is structurally harder to control than in one-to-one settings, as every piece of private information must be appropriate for every recipient in the group. Yet all existing contextual privacy benchmarks consider only single-interlocutor settings, leaving multi-party privacy risks unmeasured. We introduce MuPPET (Multi-Party Privacy Exposure Testing), a benchmark for contextual privacy in multi-party conversations. Our experiments show that models leak substantially more in multi-party settings than one-to-one evaluations suggest. Frontier models are vulnerable, and smaller open-weights models, often preferred for local deployment with sensitive data, even more so. Existing contextual privacy defences offer only partial protection, degrade utility, and do not resolve the underlying party-tracking problem.
Private Memorization Editing: Turning Memorization into a Defense to Strengthen Data Privacy in Large Language Models
Jun 09, 2025



Large Language Models (LLMs) memorize, and thus, among huge amounts of uncontrolled data, may memorize Personally Identifiable Information (PII), which should not be stored and, consequently, not leaked. In this paper, we introduce Private Memorization Editing (PME), an approach for preventing private data leakage that turns an apparent limitation, that is, the LLMs' memorization ability, into a powerful privacy defense strategy. While attacks against LLMs have been performed exploiting previous knowledge regarding their training data, our approach aims to exploit the same kind of knowledge in order to make a model more robust. We detect a memorized PII and then mitigate the memorization of PII by editing a model knowledge of its training data. We verify that our procedure does not affect the underlying language model while making it more robust against privacy Training Data Extraction attacks. We demonstrate that PME can effectively reduce the number of leaked PII in a number of configurations, in some cases even reducing the accuracy of the privacy attacks to zero.
MeMo: Towards Language Models with Associative Memory Mechanisms
Feb 18, 2025



Memorization is a fundamental ability of Transformer-based Large Language Models, achieved through learning. In this paper, we propose a paradigm shift by designing an architecture to memorize text directly, bearing in mind the principle that memorization precedes learning. We introduce MeMo, a novel architecture for language modeling that explicitly memorizes sequences of tokens in layered associative memories. By design, MeMo offers transparency and the possibility of model editing, including forgetting texts. We experimented with the MeMo architecture, showing the memorization power of the one-layer and the multi-layer configurations.
Preserving Privacy in Large Language Models: A Survey on Current Threats and Solutions
Aug 10, 2024



Large Language Models (LLMs) represent a significant advancement in artificial intelligence, finding applications across various domains. However, their reliance on massive internet-sourced datasets for training brings notable privacy issues, which are exacerbated in critical domains (e.g., healthcare). Moreover, certain application-specific scenarios may require fine-tuning these models on private data. This survey critically examines the privacy threats associated with LLMs, emphasizing the potential for these models to memorize and inadvertently reveal sensitive information. We explore current threats by reviewing privacy attacks on LLMs and propose comprehensive solutions for integrating privacy mechanisms throughout the entire learning pipeline. These solutions range from anonymizing training datasets to implementing differential privacy during training or inference and machine unlearning after training. Our comprehensive review of existing literature highlights ongoing challenges, available tools, and future directions for preserving privacy in LLMs. This work aims to guide the development of more secure and trustworthy AI systems by providing a thorough understanding of privacy preservation methods and their effectiveness in mitigating risks.
Enhancing Data Privacy in Large Language Models through Private Association Editing
Jun 26, 2024



Large Language Models (LLMs) are powerful tools with extensive applications, but their tendency to memorize private information raises significant concerns as private data leakage can easily happen. In this paper, we introduce Private Association Editing (PAE), a novel defense approach for private data leakage. PAE is designed to effectively remove Personally Identifiable Information (PII) without retraining the model. Our approach consists of a four-step procedure: detecting memorized PII, applying PAE cards to mitigate memorization of private data, verifying resilience to targeted data extraction (TDE) attacks, and ensuring consistency in the post-edit LLMs. The versatility and efficiency of PAE, which allows for batch modifications, significantly enhance data privacy in LLMs. Experimental results demonstrate the effectiveness of PAE in mitigating private data leakage. We believe PAE will serve as a critical tool in the ongoing effort to protect data privacy in LLMs, encouraging the development of safer models for real-world applications.
Investigating the Impact of Data Contamination of Large Language Models in Text-to-SQL Translation
Feb 12, 2024



Understanding textual description to generate code seems to be an achieved capability of instruction-following Large Language Models (LLMs) in zero-shot scenario. However, there is a severe possibility that this translation ability may be influenced by having seen target textual descriptions and the related code. This effect is known as Data Contamination. In this study, we investigate the impact of Data Contamination on the performance of GPT-3.5 in the Text-to-SQL code-generating tasks. Hence, we introduce a novel method to detect Data Contamination in GPTs and examine GPT-3.5's Text-to-SQL performances using the known Spider Dataset and our new unfamiliar dataset Termite. Furthermore, we analyze GPT-3.5's efficacy on databases with modified information via an adversarial table disconnection (ATD) approach, complicating Text-to-SQL tasks by removing structural pieces of information from the database. Our results indicate a significant performance drop in GPT-3.5 on the unfamiliar Termite dataset, even with ATD modifications, highlighting the effect of Data Contamination on LLMs in Text-to-SQL translation tasks.
A Trip Towards Fairness: Bias and De-Biasing in Large Language Models
May 23, 2023An outbreak in the popularity of transformer-based Language Models (such as GPT (Brown et al., 2020) and PaLM (Chowdhery et al., 2022)) has opened the doors to new Machine Learning applications. In particular, in Natural Language Processing and how pre-training from large text, corpora is essential in achieving remarkable results in downstream tasks. However, these Language Models seem to have inherent biases toward certain demographics reflected in their training data. While research has attempted to mitigate this problem, existing methods either fail to remove bias altogether, degrade performance, or are expensive. This paper examines the bias produced by promising Language Models when varying parameters and pre-training data. Finally, we propose a de-biasing technique that produces robust de-bias models that maintain performance on downstream tasks.
PreCog: Exploring the Relation between Memorization and Performance in Pre-trained Language Models
May 09, 2023


Pre-trained Language Models such as BERT are impressive machines with the ability to memorize, possibly generalized learning examples. We present here a small, focused contribution to the analysis of the interplay between memorization and performance of BERT in downstream tasks. We propose PreCog, a measure for evaluating memorization from pre-training, and we analyze its correlation with the BERT's performance. Our experiments show that highly memorized examples are better classified, suggesting memorization is an essential key to success for BERT.
Exploring Linguistic Properties of Monolingual BERTs with Typological Classification among Languages
May 03, 2023



The overwhelming success of transformers is a real conundrum stimulating a compelling question: are these machines replicating some traditional linguistic models or discovering radically new theories? In this paper, we propose a novel standpoint to investigate this important question. Using typological similarities among languages, we aim to layer-wise compare transformers for different languages to observe whether these similarities emerge for particular layers. For this investigation, we propose to use Centered kernel alignment to measure similarity among weight matrices. We discovered that syntactic typological similarity is consistent with the similarity among weights in the middle layers. This finding confirms results obtained by syntactically probing BERT and, thus, gives an important confirmation that BERT is replicating traditional linguistic models.
The Dark Side of the Language: Pre-trained Transformers in the DarkNet
Feb 09, 2022

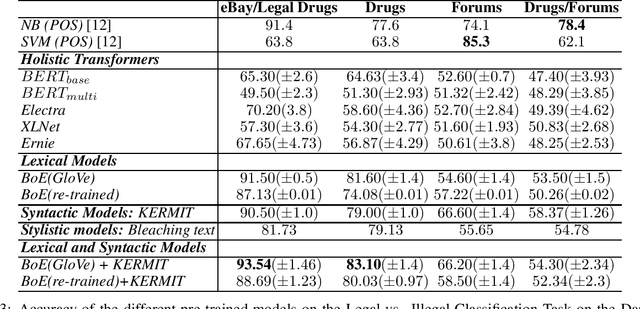
Pre-trained Transformers are challenging human performances in many natural language processing tasks. The gigantic datasets used for pre-training seem to be the key for their success on existing tasks. In this paper, we explore how a range of pre-trained natural language understanding models perform on truly novel and unexplored data, provided by classification tasks over a DarkNet corpus. Surprisingly, results show that syntactic and lexical neural networks largely outperform pre-trained Transformers. This seems to suggest that pre-trained Transformers have serious difficulties in adapting to radically novel texts.