 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Will It Drape Like? Capturing Fabric Mechanics from Depth Images
Apr 13, 2023We propose a method to estimate the mechanical parameters of fabrics using a casual capture setup with a depth camera. Our approach enables to create mechanically-correct digital representations of real-world textile materials, which is a fundamental step for many interactive design and engineering applications. As opposed to existing capture methods, which typically require expensive setups, video sequences, or manual intervention, our solution can capture at scale, is agnostic to the optical appearance of the textile, and facilitates fabric arrangement by non-expert operators. To this end, we propose a sim-to-real strategy to train a learning-based framework that can take as input one or multiple images and outputs a full set of mechanical parameters. Thanks to carefully designed data augmentation and transfer learning protocols, our solution generalizes to real images despite being trained only on synthetic data, hence successfully closing the sim-to-real loop.Key in our work is to demonstrate that evaluating the regression accuracy based on the similarity at parameter space leads to an inaccurate distances that do not match the human perception. To overcome this, we propose a novel metric for fabric drape similarity that operates on the image domain instead on the parameter space, allowing us to evaluate our estimation within the context of a similarity rank. We show that out metric correlates with human judgments about the perception of drape similarity, and that our model predictions produce perceptually accurate results compared to the ground truth parameters.
SeamlessGAN: Self-Supervised Synthesis of Tileable Texture Maps
Jan 13, 2022

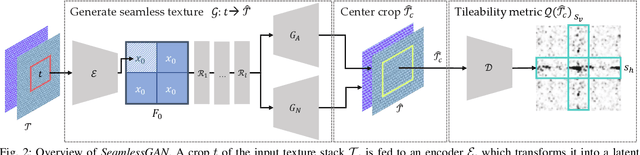
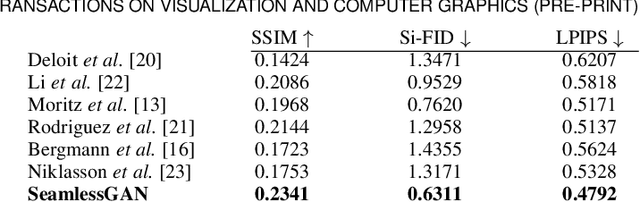
We present SeamlessGAN, a method capable of automatically generating tileable texture maps from a single input exemplar. In contrast to most existing methods, focused solely on solving the synthesis problem, our work tackles both problems, synthesis and tileability, simultaneously. Our key idea is to realize that tiling a latent space within a generative network trained using adversarial expansion techniques produces outputs with continuity at the seam intersection that can be then be turned into tileable images by cropping the central area. Since not every value of the latent space is valid to produce high-quality outputs, we leverage the discriminator as a perceptual error metric capable of identifying artifact-free textures during a sampling process. Further, in contrast to previous work on deep texture synthesis, our model is designed and optimized to work with multi-layered texture representations, enabling textures composed of multiple maps such as albedo, normals, etc. We extensively test our design choices for the network architecture, loss function and sampling parameters. We show qualitatively and quantitatively that our approach outperforms previous methods and works for textures of different types.
A Survey on Intrinsic Images: Delving Deep Into Lambert and Beyond
Dec 07, 2021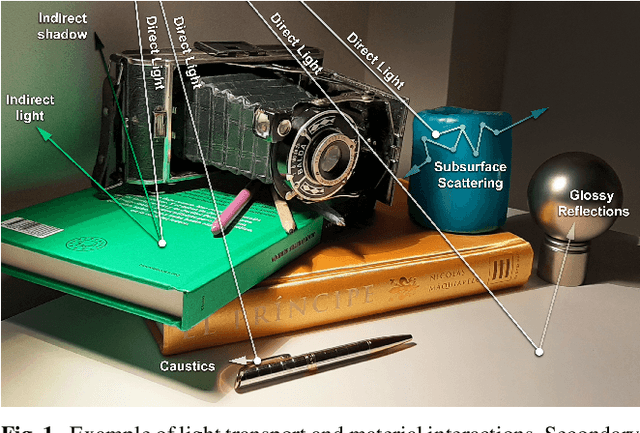
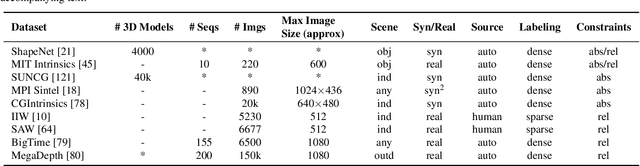
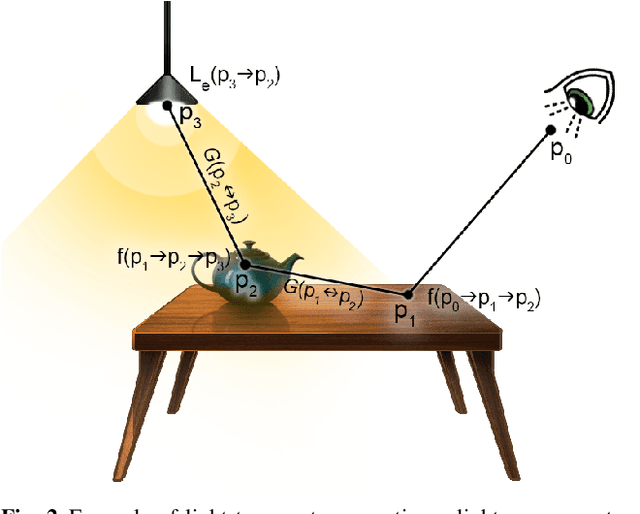
Intrinsic imaging or intrinsic image decomposition has traditionally been described as the problem of decomposing an image into two layers: a reflectance, the albedo invariant color of the material; and a shading, produced by the interaction between light and geometry. Deep learning techniques have been broadly applied in recent years to increase the accuracy of those separations. In this survey, we overview those results in context of well-known intrinsic image data sets and relevant metrics used in the literature, discussing their suitability to predict a desirable intrinsic image decomposition. Although the Lambertian assumption is still a foundational basis for many methods, we show that there is increasing awareness on the potential of more sophisticated physically-principled components of the image formation process, that is, optically accurate material models and geometry, and more complete inverse light transport estimations. We classify these methods in terms of the type of decomposition, considering the priors and models used, as well as the learning architecture and methodology driving the decomposition process. We also provide insights about future directions for research, given the recent advances in neural, inverse and differentiable rendering techniques.
Neural Photometry-guided Visual Attribute Transfer
Dec 05, 2021
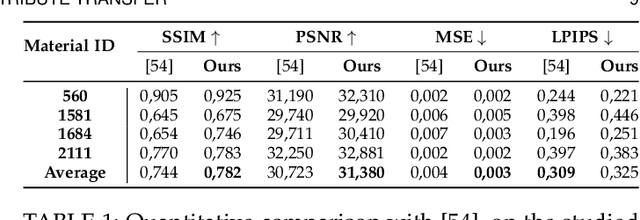
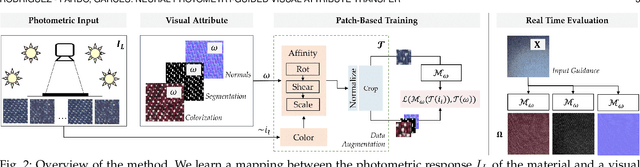

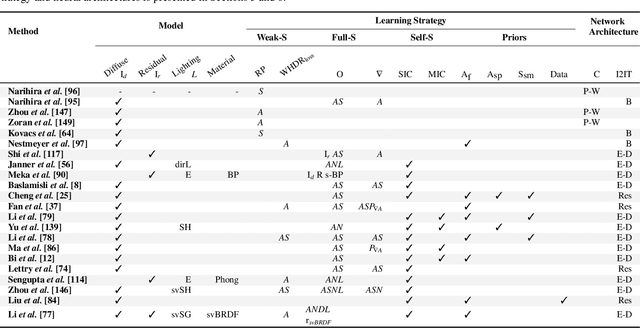
We present a deep learning-based method for propagating spatially-varying visual material attributes (e.g. texture maps or image stylizations) to larger samples of the same or similar materials. For training, we leverage images of the material taken under multiple illuminations and a dedicated data augmentation policy, making the transfer robust to novel illumination conditions and affine deformations. Our model relies on a supervised image-to-image translation framework and is agnostic to the transferred domain; we showcase a semantic segmentation, a normal map, and a stylization. Following an image analogies approach, the method only requires the training data to contain the same visual structures as the input guidance. Our approach works at interactive rates, making it suitable for material edit applications. We thoroughly evaluate our learning methodology in a controlled setup providing quantitative measures of performance. Last, we demonstrate that training the model on a single material is enough to generalize to materials of the same type without the need for massive datasets.
Fully Convolutional Graph Neural Networks for Parametric Virtual Try-On
Sep 09, 2020
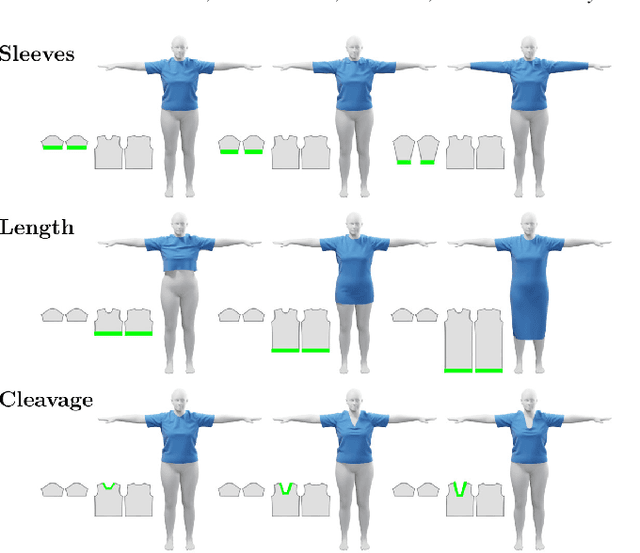
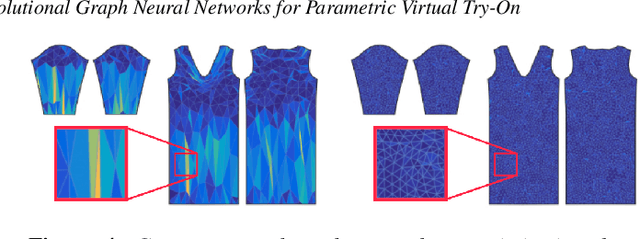
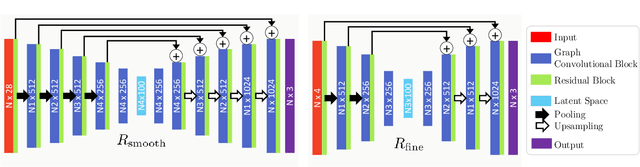
We present a learning-based approach for virtual try-on applications based on a fully convolutional graph neural network. In contrast to existing data-driven models, which are trained for a specific garment or mesh topology, our fully convolutional model can cope with a large family of garments, represented as parametric predefined 2D panels with arbitrary mesh topology, including long dresses, shirts, and tight tops. Under the hood, our novel geometric deep learning approach learns to drape 3D garments by decoupling the three different sources of deformations that condition the fit of clothing: garment type, target body shape, and material. Specifically, we first learn a regressor that predicts the 3D drape of the input parametric garment when worn by a mean body shape. Then, after a mesh topology optimization step where we generate a sufficient level of detail for the input garment type, we further deform the mesh to reproduce deformations caused by the target body shape. Finally, we predict fine-scale details such as wrinkles that depend mostly on the garment material. We qualitatively and quantitatively demonstrate that our fully convolutional approach outperforms existing methods in terms of generalization capabilities and memory requirements, and therefore it opens the door to more general learning-based models for virtual try-on applications.
SoftSMPL: Data-driven Modeling of Nonlinear Soft-tissue Dynamics for Parametric Humans
Apr 01, 2020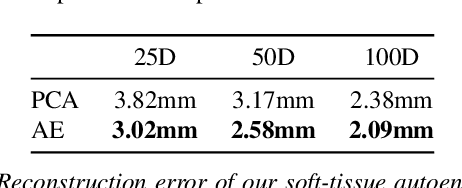
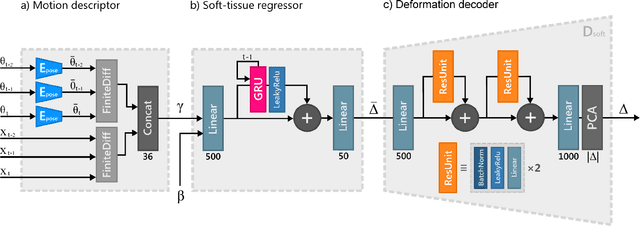
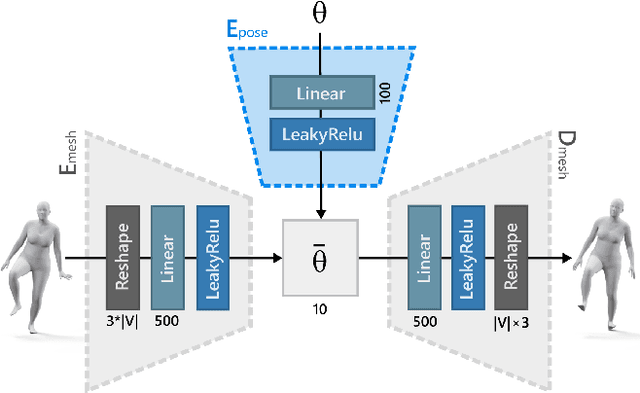
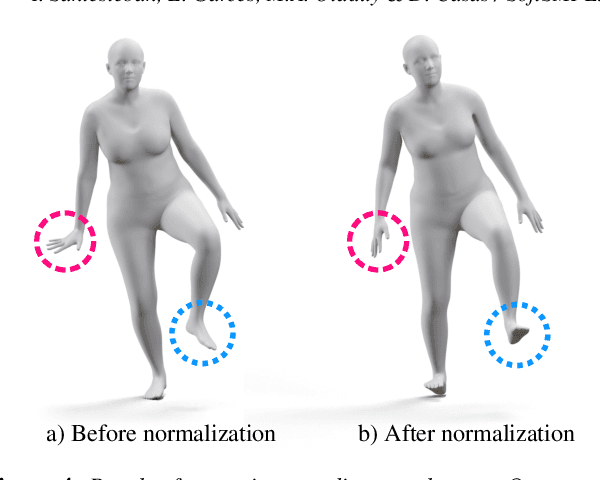
We present SoftSMPL, a learning-based method to model realistic soft-tissue dynamics as a function of body shape and motion. Datasets to learn such task are scarce and expensive to generate, which makes training models prone to overfitting. At the core of our method there are three key contributions that enable us to model highly realistic dynamics and better generalization capabilities than state-of-the-art methods, while training on the same data. First, a novel motion descriptor that disentangles the standard pose representation by removing subject-specific features; second, a neural-network-based recurrent regressor that generalizes to unseen shapes and motions; and third, a highly efficient nonlinear deformation subspace capable of representing soft-tissue deformations of arbitrary shapes. We demonstrate qualitative and quantitative improvements over existing methods and, additionally, we show the robustness of our method on a variety of motion capture databases.
A Similarity Measure for Material Appearance
May 04, 2019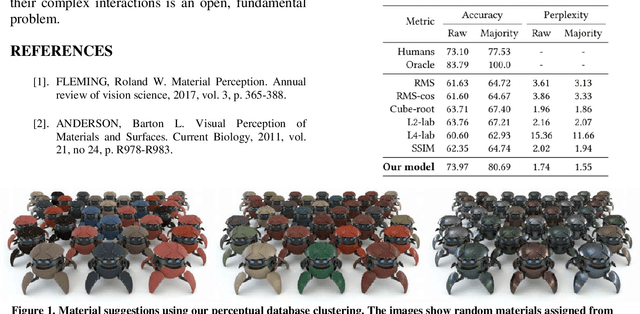
We present a model to measure the similarity in appearance between different materials, which correlates with human similarity judgments. We first create a database of 9,000 rendered images depicting objects with varying materials, shape and illumination. We then gather data on perceived similarity from crowdsourced experiments; our analysis of over 114,840 answers suggests that indeed a shared perception of appearance similarity exists. We feed this data to a deep learning architecture with a novel loss function, which learns a feature space for materials that correlates with such perceived appearance similarity. Our evaluation shows that our model outperforms existing metrics. Last, we demonstrate several applications enabled by our metric, including appearance-based search for material suggestions, database visualization, clustering and summarization, and gamut mapping.
* 12 pages, 17 figures
Learning icons appearance similarity
Feb 01, 2019

Selecting an optimal set of icons is a crucial step in the pipeline of visual design to structure and navigate through content. However, designing the icons sets is usually a difficult task for which expert knowledge is required. In this work, to ease the process of icon set selection to the users, we propose a similarity metric which captures the properties of style and visual identity. We train a Siamese Neural Network with an online dataset of icons organized in visually coherent collections that are used to adaptively sample training data and optimize the training process. As the dataset contains noise, we further collect human-rated information on the perception of icon's similarity which will be used for evaluating and testing the proposed model. We present several results and applications based on searches, kernel visualizations and optimized set proposals that can be helpful for designers and non-expert users while exploring large collections of icons.
* 12 pages, 11 figures
BRDF Estimation of Complex Materials with Nested Learning
Nov 22, 2018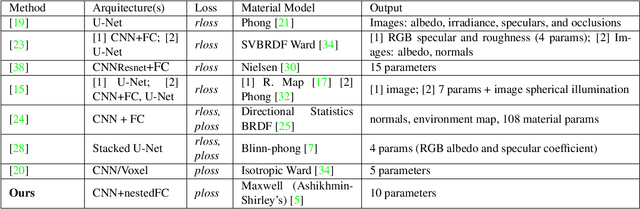

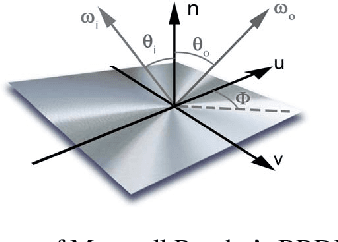
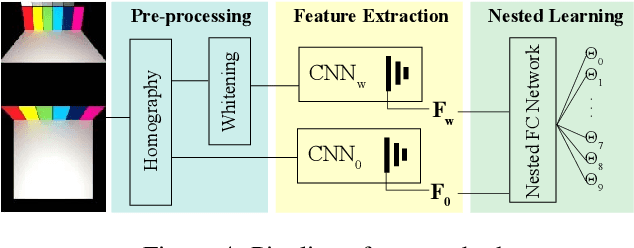
The estimation of the optical properties of a material from RGB-images is an important but extremely ill-posed problem in Computer Graphics. While recent works have successfully approached this problem even from just a single photograph, significant simplifications of the material model are assumed, limiting the usability of such methods. The detection of complex material properties such as anisotropy or Fresnel effect remains an unsolved challenge. We propose a novel method that predicts the model parameters of an artist-friendly, physically-based BRDF, from only two low-resolution shots of the material. Thanks to a novel combination of deep neural networks in a nested architecture, we are able to handle the ambiguities given by the non-orthogonality and non-convexity of the parameter space. To train the network, we generate a novel dataset of physically-based synthetic images. We prove that our model can recover new properties like anisotropy, index of refraction and a second reflectance color, for materials that have tinted specular reflections or whose albedo changes at glancing angles.
Convolutional sparse coding for capturing high speed video content
Jun 13, 2018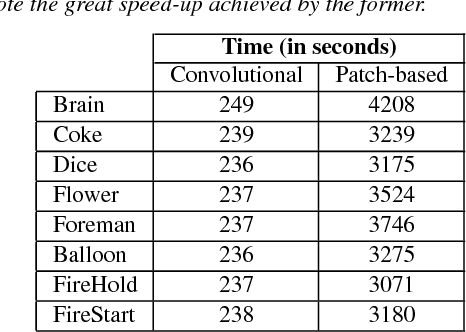
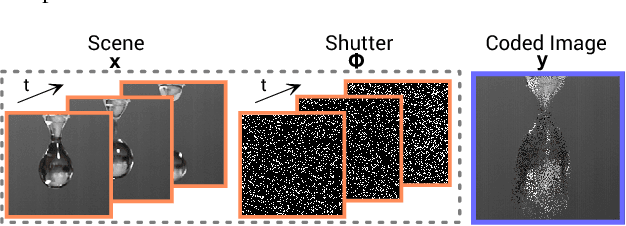

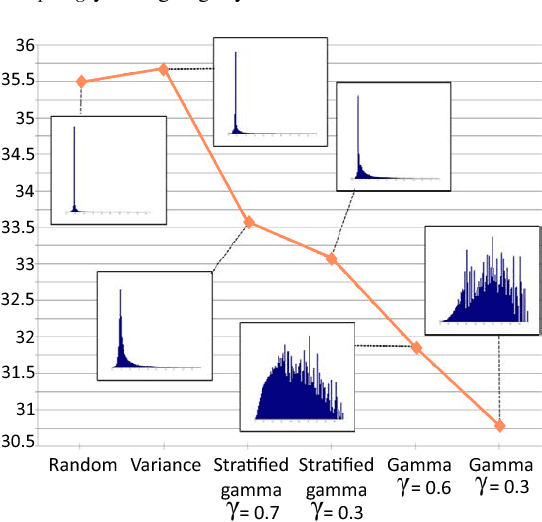
Video capture is limited by the trade-off between spatial and temporal resolution: when capturing videos of high temporal resolution, the spatial resolution decreases due to bandwidth limitations in the capture system. Achieving both high spatial and temporal resolution is only possible with highly specialized and very expensive hardware, and even then the same basic trade-off remains. The recent introduction of compressive sensing and sparse reconstruction techniques allows for the capture of single-shot high-speed video, by coding the temporal information in a single frame, and then reconstructing the full video sequence from this single coded image and a trained dictionary of image patches. In this paper, we first analyze this approach, and find insights that help improve the quality of the reconstructed videos. We then introduce a novel technique, based on convolutional sparse coding (CSC), and show how it outperforms the state-of-the-art, patch-based approach in terms of flexibility and efficiency, due to the convolutional nature of its filter banks. The key idea for CSC high-speed video acquisition is extending the basic formulation by imposing an additional constraint in the temporal dimension, which enforces sparsity of the first-order derivatives over time.