 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSALSA: Single-pass Autoregressive LLM Structured Classification
Oct 26, 2025Despite their impressive generalization capabilities, instruction-tuned Large Language Models often underperform on text classification benchmarks. We introduce SALSA, a coherent pipeline that combines structured prompting, class-to-token mapping, and parameter-efficient fine-tuning, thereby avoiding cold-start training. Each class label is mapped to a distinct output token, and prompts are constructed to elicit a single-token response. During inference, the model's output is projected only onto the logits of the relevant class tokens, enabling efficient and accurate classification in a single forward pass. SALSA achieves state-of-the-art results across diverse benchmarks, demonstrating its robustness and scalability for LLM-based classification applications.
BitFit: Simple Parameter-efficient Fine-tuning for Transformer-based Masked Language-models
Jun 22, 2021
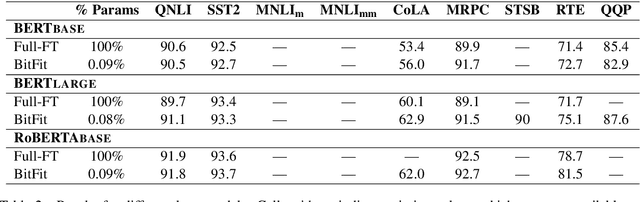

We show that with small-to-medium training data, fine-tuning only the bias terms (or a subset of the bias terms) of pre-trained BERT models is competitive with (and sometimes better than) fine-tuning the entire model. For larger data, bias-only fine-tuning is competitive with other sparse fine-tuning methods. Besides their practical utility, these findings are relevant for the question of understanding the commonly-used process of finetuning: they support the hypothesis that finetuning is mainly about exposing knowledge induced by language-modeling training, rather than learning new task-specific linguistic knowledge.