 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn The Robustness of a Neural Network
Aug 07, 2017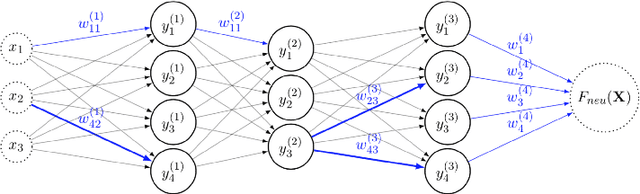
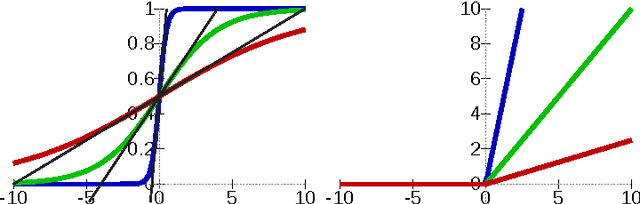
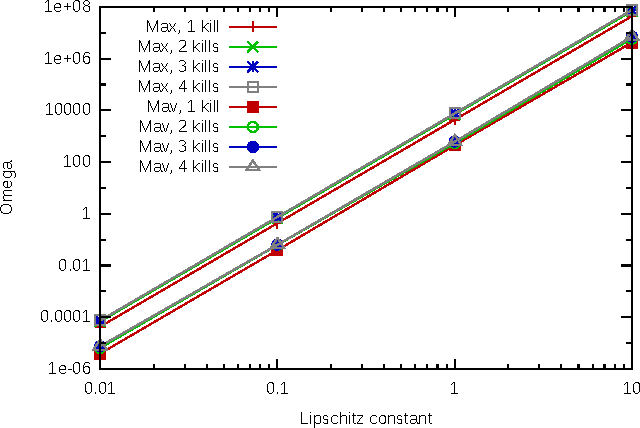
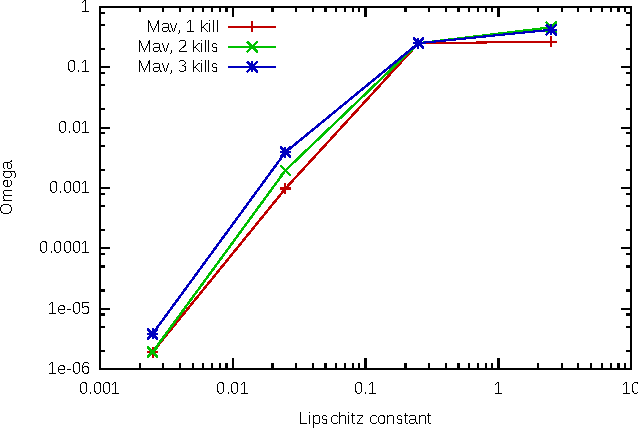
With the development of neural networks based machine learning and their usage in mission critical applications, voices are rising against the \textit{black box} aspect of neural networks as it becomes crucial to understand their limits and capabilities. With the rise of neuromorphic hardware, it is even more critical to understand how a neural network, as a distributed system, tolerates the failures of its computing nodes, neurons, and its communication channels, synapses. Experimentally assessing the robustness of neural networks involves the quixotic venture of testing all the possible failures, on all the possible inputs, which ultimately hits a combinatorial explosion for the first, and the impossibility to gather all the possible inputs for the second. In this paper, we prove an upper bound on the expected error of the output when a subset of neurons crashes. This bound involves dependencies on the network parameters that can be seen as being too pessimistic in the average case. It involves a polynomial dependency on the Lipschitz coefficient of the neurons activation function, and an exponential dependency on the depth of the layer where a failure occurs. We back up our theoretical results with experiments illustrating the extent to which our prediction matches the dependencies between the network parameters and robustness. Our results show that the robustness of neural networks to the average crash can be estimated without the need to neither test the network on all failure configurations, nor access the training set used to train the network, both of which are practically impossible requirements.
When Neurons Fail
Jun 27, 2017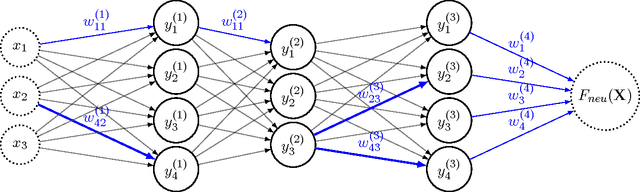
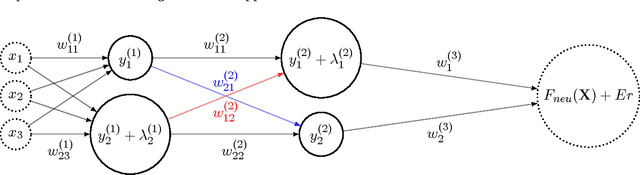
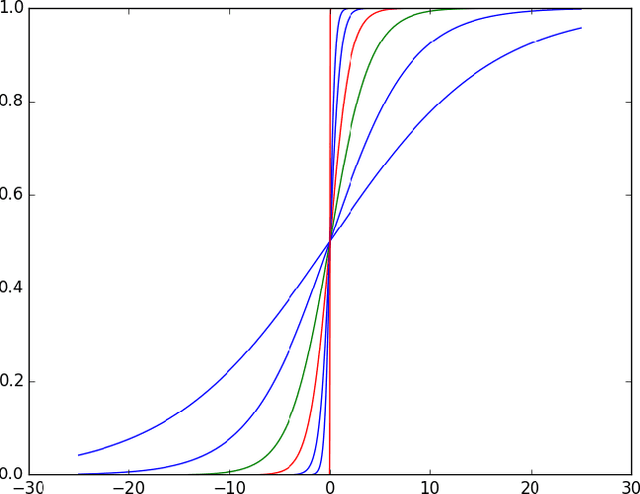
We view a neural network as a distributed system of which neurons can fail independently, and we evaluate its robustness in the absence of any (recovery) learning phase. We give tight bounds on the number of neurons that can fail without harming the result of a computation. To determine our bounds, we leverage the fact that neural activation functions are Lipschitz-continuous. Our bound is on a quantity, we call the \textit{Forward Error Propagation}, capturing how much error is propagated by a neural network when a given number of components is failing, computing this quantity only requires looking at the topology of the network, while experimentally assessing the robustness of a network requires the costly experiment of looking at all the possible inputs and testing all the possible configurations of the network corresponding to different failure situations, facing a discouraging combinatorial explosion. We distinguish the case of neurons that can fail and stop their activity (crashed neurons) from the case of neurons that can fail by transmitting arbitrary values (Byzantine neurons). Interestingly, as we show in the paper, our bound can easily be extended to the case where synapses can fail. We show how our bound can be leveraged to quantify the effect of memory cost reduction on the accuracy of a neural network, to estimate the amount of information any neuron needs from its preceding layer, enabling thereby a boosting scheme that prevents neurons from waiting for unnecessary signals. We finally discuss the trade-off between neural networks robustness and learning cost.
Dynamic Safe Interruptibility for Decentralized Multi-Agent Reinforcement Learning
May 22, 2017In reinforcement learning, agents learn by performing actions and observing their outcomes. Sometimes, it is desirable for a human operator to \textit{interrupt} an agent in order to prevent dangerous situations from happening. Yet, as part of their learning process, agents may link these interruptions, that impact their reward, to specific states and deliberately avoid them. The situation is particularly challenging in a multi-agent context because agents might not only learn from their own past interruptions, but also from those of other agents. Orseau and Armstrong defined \emph{safe interruptibility} for one learner, but their work does not naturally extend to multi-agent systems. This paper introduces \textit{dynamic safe interruptibility}, an alternative definition more suited to decentralized learning problems, and studies this notion in two learning frameworks: \textit{joint action learners} and \textit{independent learners}. We give realistic sufficient conditions on the learning algorithm to enable dynamic safe interruptibility in the case of joint action learners, yet show that these conditions are not sufficient for independent learners. We show however that if agents can detect interruptions, it is possible to prune the observations to ensure dynamic safe interruptibility even for independent learners.
Byzantine-Tolerant Machine Learning
Mar 08, 2017
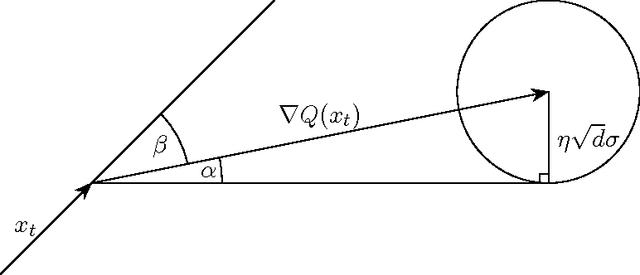
The growth of data, the need for scalability and the complexity of models used in modern machine learning calls for distributed implementations. Yet, as of today, distributed machine learning frameworks have largely ignored the possibility of arbitrary (i.e., Byzantine) failures. In this paper, we study the robustness to Byzantine failures at the fundamental level of stochastic gradient descent (SGD), the heart of most machine learning algorithms. Assuming a set of $n$ workers, up to $f$ of them being Byzantine, we ask how robust can SGD be, without limiting the dimension, nor the size of the parameter space. We first show that no gradient descent update rule based on a linear combination of the vectors proposed by the workers (i.e, current approaches) tolerates a single Byzantine failure. We then formulate a resilience property of the update rule capturing the basic requirements to guarantee convergence despite $f$ Byzantine workers. We finally propose Krum, an update rule that satisfies the resilience property aforementioned. For a $d$-dimensional learning problem, the time complexity of Krum is $O(n^2 \cdot (d + \log n))$.