 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexible RISs: Learning-based Array Manifold Estimation and Phase-shift Optimization
Feb 13, 2026Reconfigurable intelligent surfaces (RISs) are envisioned as a key enabler for next-generation wireless networks, offering programmable control over propagation environments. While extensive research focuses on planar RIS architectures, practical deployments often involve non-planar surfaces, such as structural columns or curved facades, where standard planar beamforming models fail. Moreover, existing analytical solutions for curved RISs are often restricted to specific, pre-defined array manifold geometries. To address this limitation, this paper proposes a novel deep learning (DL) framework for optimizing the phase shifts of non-planar RISs. We first introduce a low-dimensional parametric model to capture arbitrary surface curvature effectively. Based on this, we design a neural network (NN) that utilizes a sparse set of received power measurements to estimate the surface geometry and derive the optimal phase configuration. Simulation results demonstrate that the proposed algorithm converges fast and significantly outperforms conventional planar beamforming designs, validating its robustness against arbitrary surface curvature. We also analyze the impact of the measurement location error on the algorithm's performance.
Can Small and Reasoning Large Language Models Score Journal Articles for Research Quality and Do Averaging and Few-shot Help?
Oct 25, 2025Assessing published academic journal articles is a common task for evaluations of departments and individuals. Whilst it is sometimes supported by citation data, Large Language Models (LLMs) may give more useful indications of article quality. Evidence of this capability exists for two of the largest LLM families, ChatGPT and Gemini, and the medium sized LLM Gemma3 27b, but it is unclear whether smaller LLMs and reasoning models have similar abilities. This is important because larger models may be slow and impractical in some situations, and reasoning models may perform differently. Four relevant questions are addressed with Gemma3 variants, Llama4 Scout, Qwen3, Magistral Small and DeepSeek R1, on a dataset of 2,780 medical, health and life science papers in 6 fields, with two different gold standards, one novel. The results suggest that smaller (open weights) and reasoning LLMs have similar performance to ChatGPT 4o-mini and Gemini 2.0 Flash, but that 1b parameters may often, and 4b sometimes, be too few. Moreover, averaging scores from multiple identical queries seems to be a universally successful strategy, and few-shot prompts (four examples) tended to help but the evidence was equivocal. Reasoning models did not have a clear advantage. Overall, the results show, for the first time, that smaller LLMs >4b, including reasoning models, have a substantial capability to score journal articles for research quality, especially if score averaging is used.
Mapping Research Topics in Software Testing: A Bibliometric Analysis
Sep 09, 2021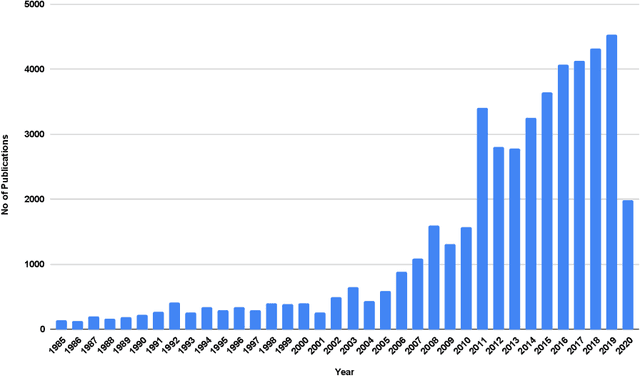
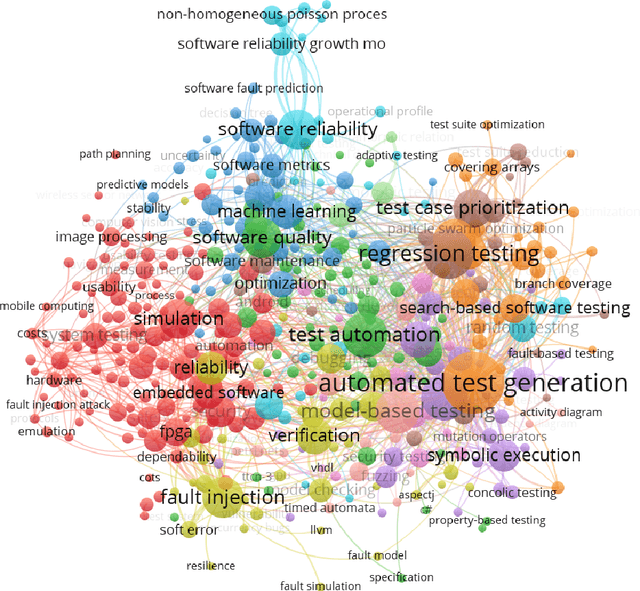
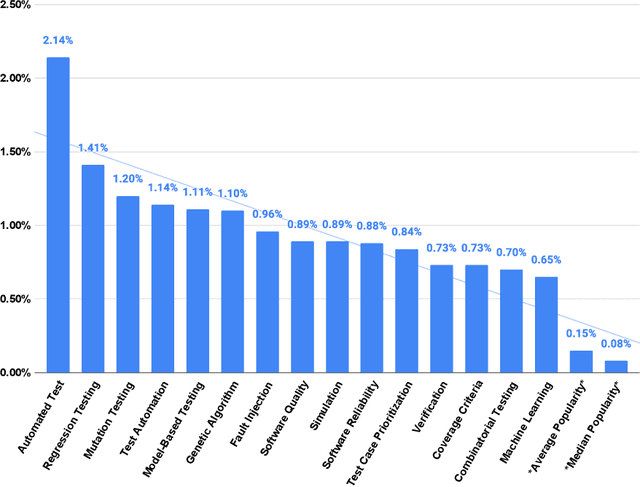

In this study, we apply co-word analysis - a text mining technique based on the co-occurrence of terms - to map the topology of software testing research topics, with the goal of providing current and prospective researchers with a map, and observations about the evolution, of the software testing field. Our analysis enables the mapping of software testing research into clusters of connected topics, from which emerge a total of 16 high-level research themes and a further 18 subthemes. This map also suggests topics that are growing in importance, including topics related to web and mobile applications and artificial intelligence. Exploration of author and country-based collaboration patterns offers similar insight into the implicit and explicit factors that influence collaboration and suggests emerging sources of collaboration for future work. We make our observations - and the underlying mapping of research topics and research collaborations - available so that researchers can gain a deeper understanding of the topology of the software testing field, inspiration regarding new areas and connections to explore, and collaborators who will broaden their perspectives.