 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Unsupervised Domain Adaptation for Neural Networks via Moment Alignment
May 28, 2018
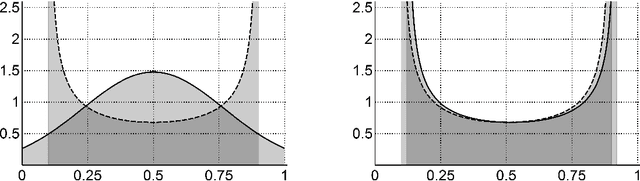


A novel approach for unsupervised domain adaptation for neural networks is proposed that relies on metric-based regularization of the learning process. The metric-based regularization aims at domain-invariant latent feature representations by means of maximizing the similarity between domain-specific activation distributions. The proposed metric results from modifying an integral probability metric such that it becomes translation-invariant on a polynomial function space. The metric has an intuitive interpretation in the dual space as the sum of differences of higher order central moments of the corresponding activation distributions. Error minimization guarantees are proven for the continuous case. As demonstrated by an analysis of standard benchmark experiments for sentiment analysis, object recognition and digit recognition, the outlined approach is robust regarding parameter changes and achieves higher classification accuracies than comparable approaches.
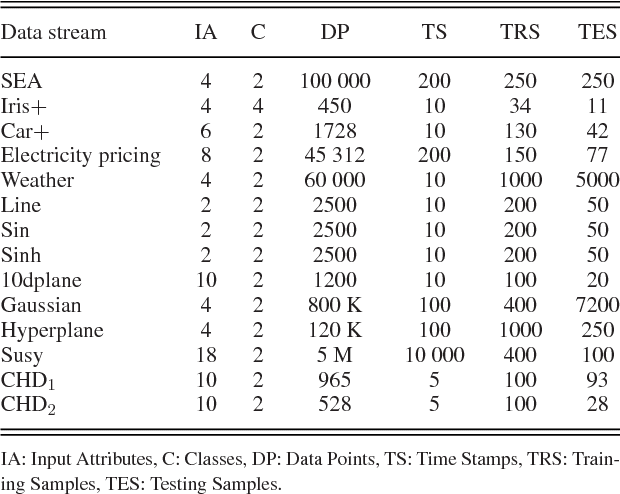
An Online RFID Localization in the Manufacturing Shopfloor
May 20, 2018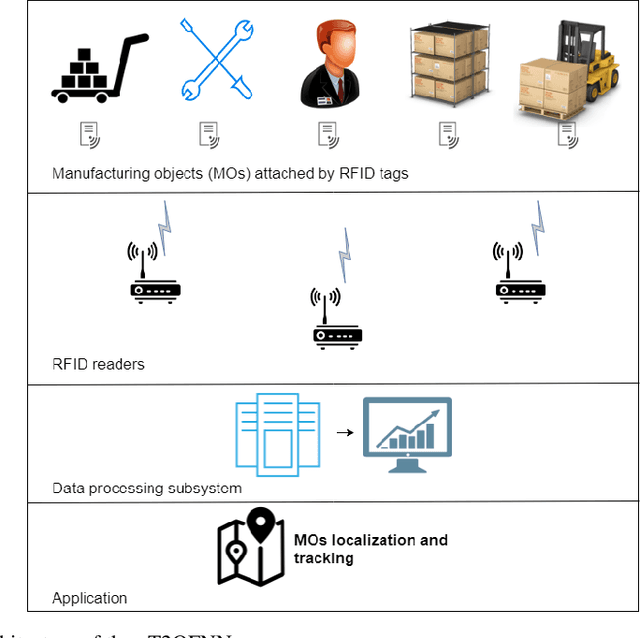
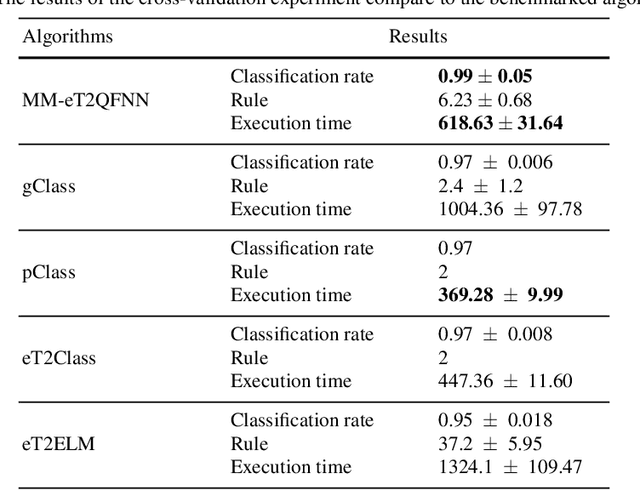
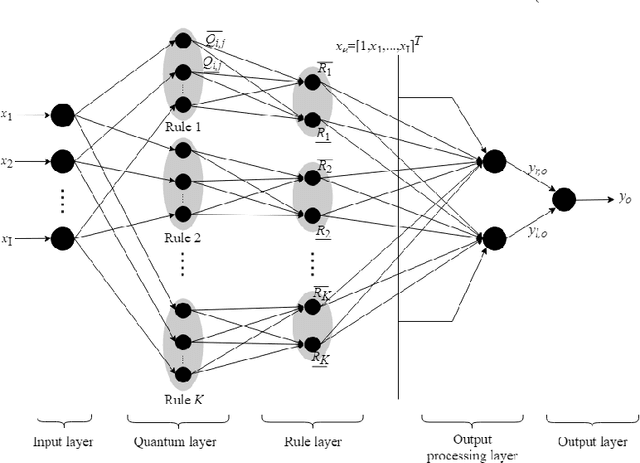
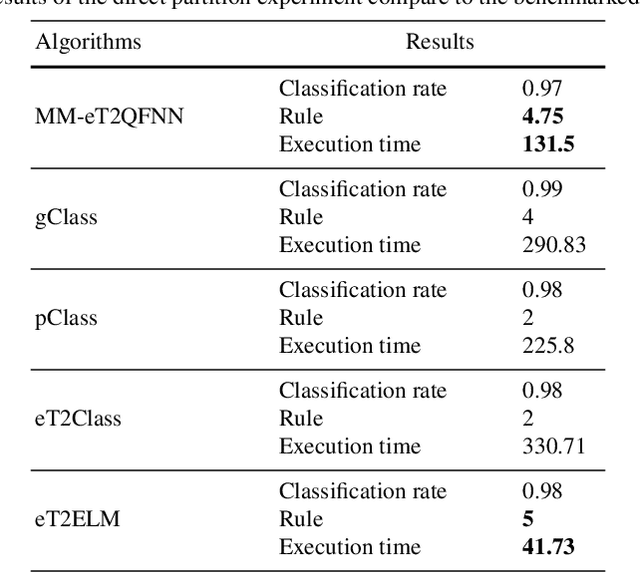
Radio Frequency Identification technology has gained popularity for cheap and easy deployment. In the realm of manufacturing shopfloor, it can be used to track the location of manufacturing objects to achieve better efficiency. The underlying challenge of localization lies in the non-stationary characteristics of manufacturing shopfloor which calls for an adaptive life-long learning strategy in order to arrive at accurate localization results. This paper presents an evolving model based on a novel evolving intelligent system, namely evolving Type-2 Quantum Fuzzy Neural Network (eT2QFNN), which features an interval type-2 quantum fuzzy set with uncertain jump positions. The quantum fuzzy set possesses a graded membership degree which enables better identification of overlaps between classes. The eT2QFNN works fully in the evolving mode where all parameters including the number of rules are automatically adjusted and generated on the fly. The parameter adjustment scenario relies on decoupled extended Kalman filter method. Our numerical study shows that eT2QFNN is able to deliver comparable accuracy compared to state-of-the-art algorithms.
Online Tool Condition Monitoring Based on Parsimonious Ensemble+
Nov 06, 2017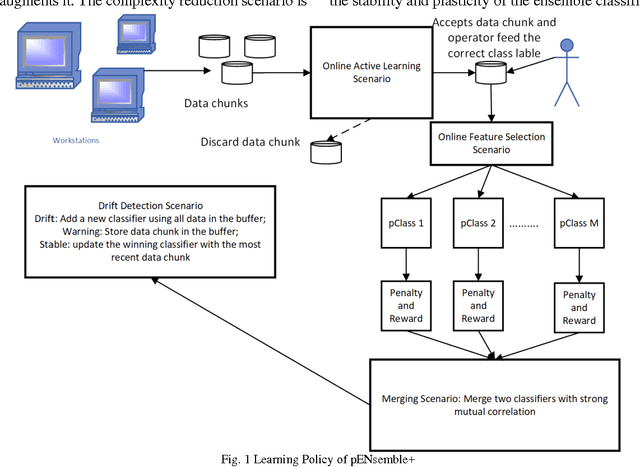
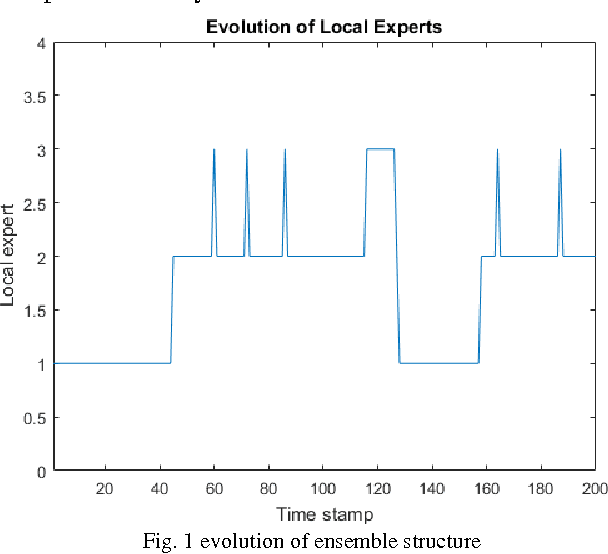
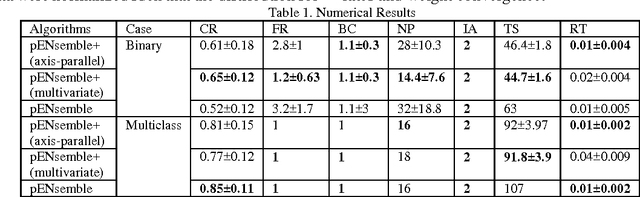
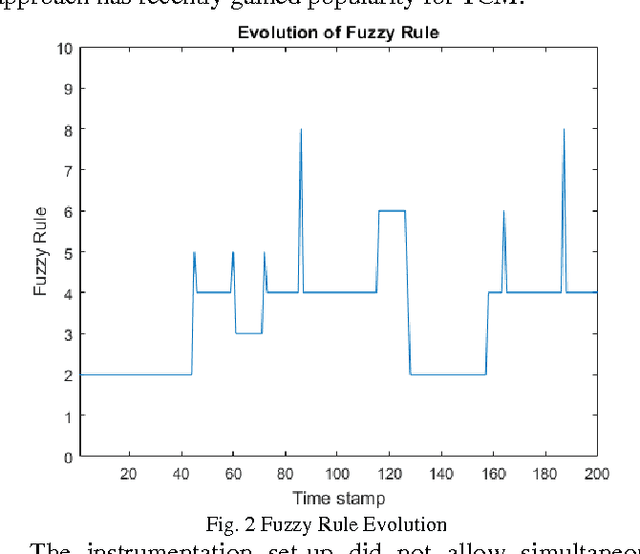
Accurate diagnosis of tool wear in metal turning process remains an open challenge for both scientists and industrial practitioners because of inhomogeneities in workpiece material, nonstationary machining settings to suit production requirements, and nonlinear relations between measured variables and tool wear. Common methodologies for tool condition monitoring still rely on batch approaches which cannot cope with a fast sampling rate of metal cutting process. Furthermore they require a retraining process to be completed from scratch when dealing with a new set of machining parameters. This paper presents an online tool condition monitoring approach based on Parsimonious Ensemble+, pENsemble+. The unique feature of pENsemble+ lies in its highly flexible principle where both ensemble structure and base-classifier structure can automatically grow and shrink on the fly based on the characteristics of data streams. Moreover, the online feature selection scenario is integrated to actively sample relevant input attributes. The paper presents advancement of a newly developed ensemble learning algorithm, pENsemble+, where online active learning scenario is incorporated to reduce operator labelling effort. The ensemble merging scenario is proposed which allows reduction of ensemble complexity while retaining its diversity. Experimental studies utilising real-world manufacturing data streams and comparisons with well known algorithms were carried out. Furthermore, the efficacy of pENsemble was examined using benchmark concept drift data streams. It has been found that pENsemble+ incurs low structural complexity and results in a significant reduction of operator labelling effort.
Central Moment Discrepancy (CMD) for Domain-Invariant Representation Learning
Jul 04, 2017
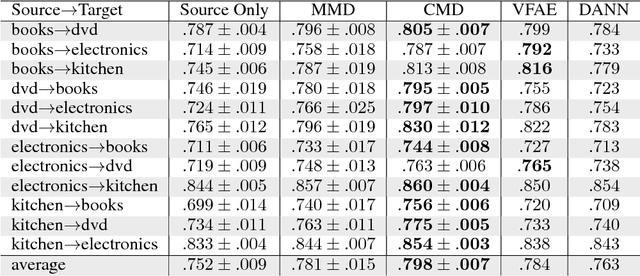
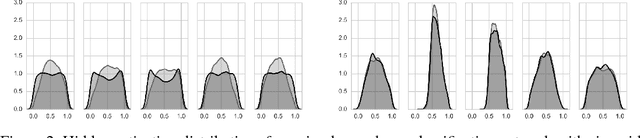
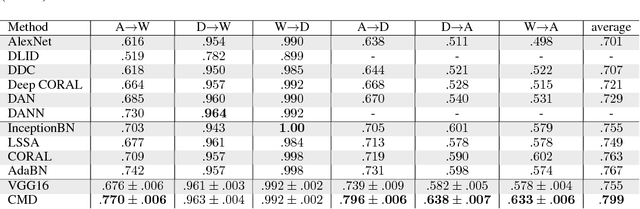
The learning of domain-invariant representations in the context of domain adaptation with neural networks is considered. We propose a new regularization method that minimizes the discrepancy between domain-specific latent feature representations directly in the hidden activation space. Although some standard distribution matching approaches exist that can be interpreted as the matching of weighted sums of moments, e.g. Maximum Mean Discrepancy (MMD), an explicit order-wise matching of higher order moments has not been considered before. We propose to match the higher order central moments of probability distributions by means of order-wise moment differences. Our model does not require computationally expensive distance and kernel matrix computations. We utilize the equivalent representation of probability distributions by moment sequences to define a new distance function, called Central Moment Discrepancy (CMD). We prove that CMD is a metric on the set of probability distributions on a compact interval. We further prove that convergence of probability distributions on compact intervals w.r.t. the new metric implies convergence in distribution of the respective random variables. We test our approach on two different benchmark data sets for object recognition (Office) and sentiment analysis of product reviews (Amazon reviews). CMD achieves a new state-of-the-art performance on most domain adaptation tasks of Office and outperforms networks trained with MMD, Variational Fair Autoencoders and Domain Adversarial Neural Networks on Amazon reviews. In addition, a post-hoc parameter sensitivity analysis shows that the new approach is stable w.r.t. parameter changes in a certain interval. The source code of the experiments is publicly available.
Evolving Ensemble Fuzzy Classifier
May 18, 2017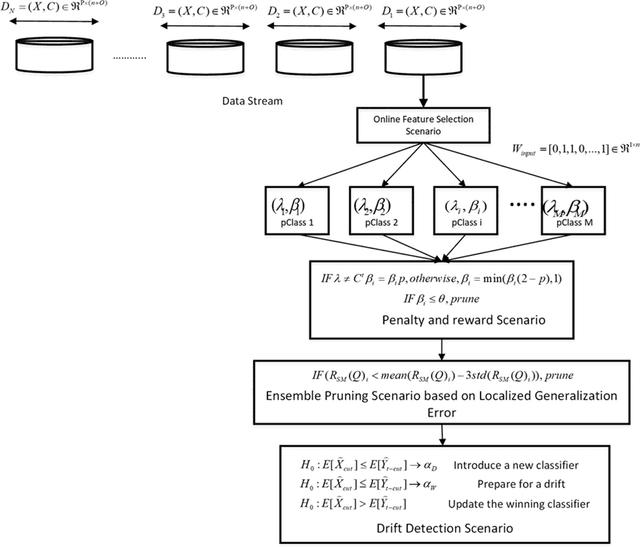
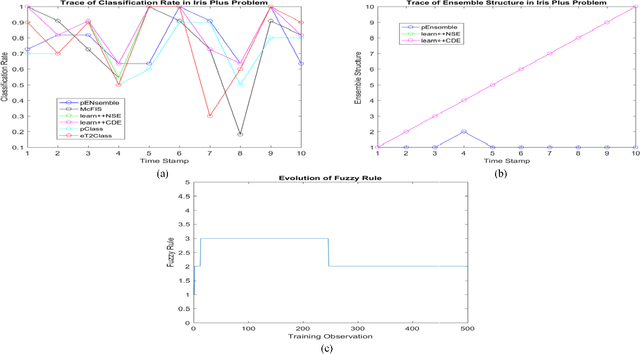
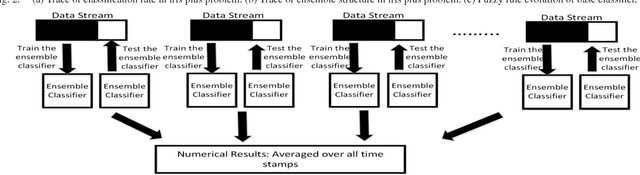
The concept of ensemble learning offers a promising avenue in learning from data streams under complex environments because it addresses the bias and variance dilemma better than its single model counterpart and features a reconfigurable structure, which is well suited to the given context. While various extensions of ensemble learning for mining non-stationary data streams can be found in the literature, most of them are crafted under a static base classifier and revisits preceding samples in the sliding window for a retraining step. This feature causes computationally prohibitive complexity and is not flexible enough to cope with rapidly changing environments. Their complexities are often demanding because it involves a large collection of offline classifiers due to the absence of structural complexities reduction mechanisms and lack of an online feature selection mechanism. A novel evolving ensemble classifier, namely Parsimonious Ensemble pENsemble, is proposed in this paper. pENsemble differs from existing architectures in the fact that it is built upon an evolving classifier from data streams, termed Parsimonious Classifier pClass. pENsemble is equipped by an ensemble pruning mechanism, which estimates a localized generalization error of a base classifier. A dynamic online feature selection scenario is integrated into the pENsemble. This method allows for dynamic selection and deselection of input features on the fly. pENsemble adopts a dynamic ensemble structure to output a final classification decision where it features a novel drift detection scenario to grow the ensemble structure. The efficacy of the pENsemble has been numerically demonstrated through rigorous numerical studies with dynamic and evolving data streams where it delivers the most encouraging performance in attaining a tradeoff between accuracy and complexity.
Metacognitive Learning Approach for Online Tool Condition Monitoring
May 06, 2017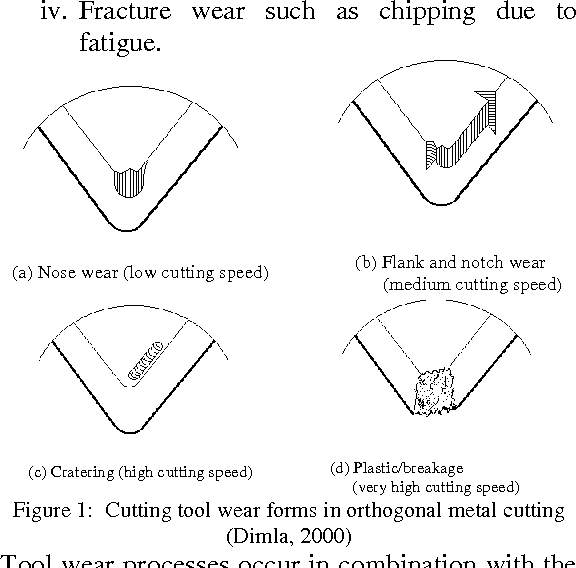
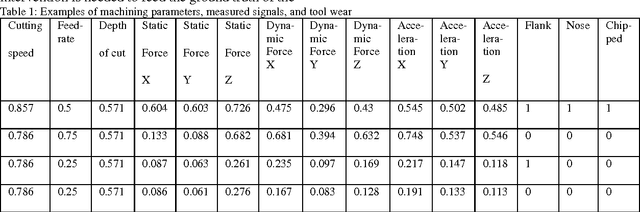
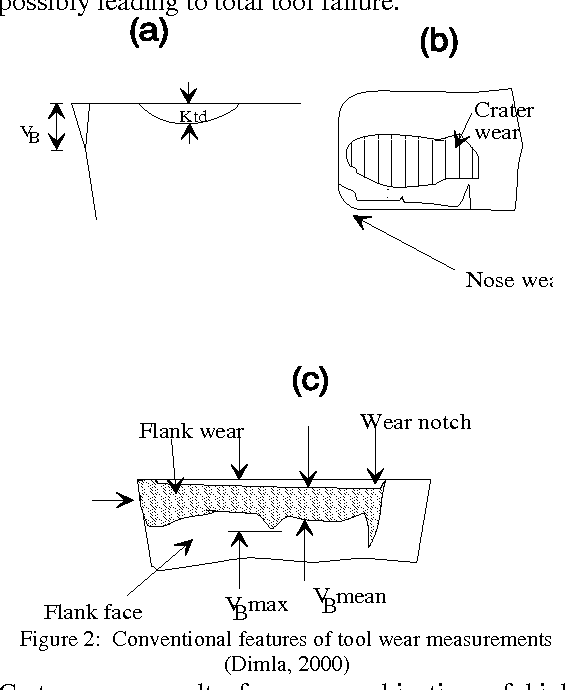
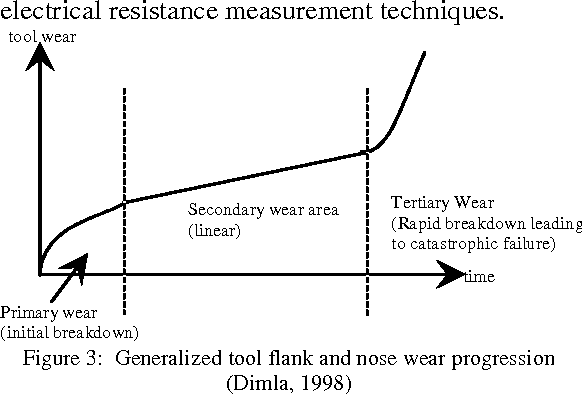
As manufacturing processes become increasingly automated, so should tool condition monitoring (TCM) as it is impractical to have human workers monitor the state of the tools continuously. Tool condition is crucial to ensure the good quality of products: Worn tools affect not only the surface quality but also the dimensional accuracy, which means higher reject rate of the products. Therefore, there is an urgent need to identify tool failures before it occurs on the fly. While various versions of intelligent tool condition monitoring have been proposed, most of them suffer from a cognitive nature of traditional machine learning algorithms. They focus on the how to learn process without paying attention to other two crucial issues: what to learn, and when to learn. The what to learn and the when to learn provide self regulating mechanisms to select the training samples and to determine time instants to train a model. A novel tool condition monitoring approach based on a psychologically plausible concept, namely the metacognitive scaffolding theory, is proposed and built upon a recently published algorithm, recurrent classifier (rClass). The learning process consists of three phases: what to learn, how to learn, when to learn and makes use of a generalized recurrent network structure as a cognitive component. Experimental studies with real-world manufacturing data streams were conducted where rClass demonstrated the highest accuracy while retaining the lowest complexity over its counterparts.
Parsimonious Random Vector Functional Link Network for Data Streams
May 06, 2017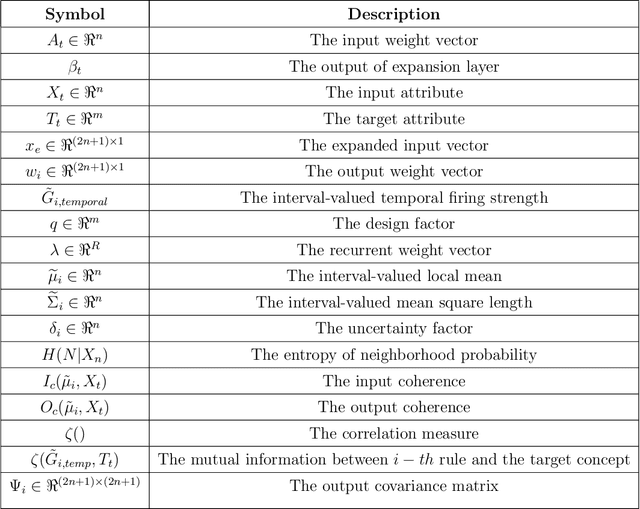
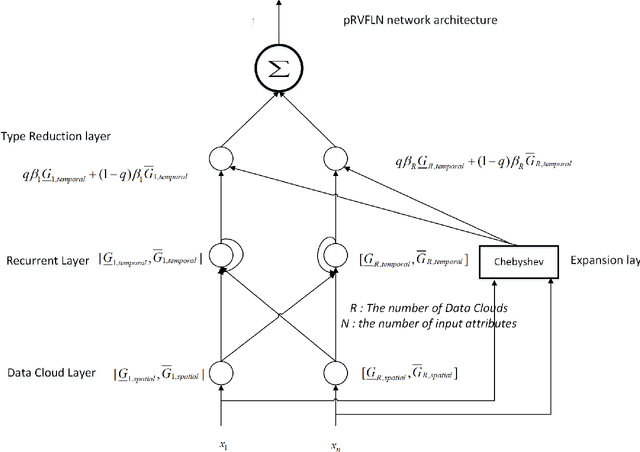
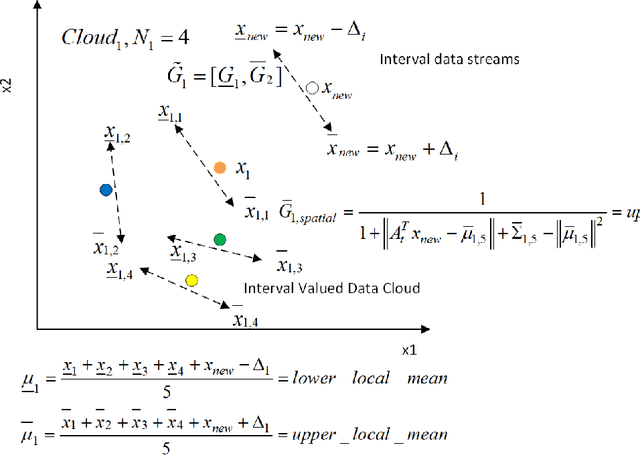
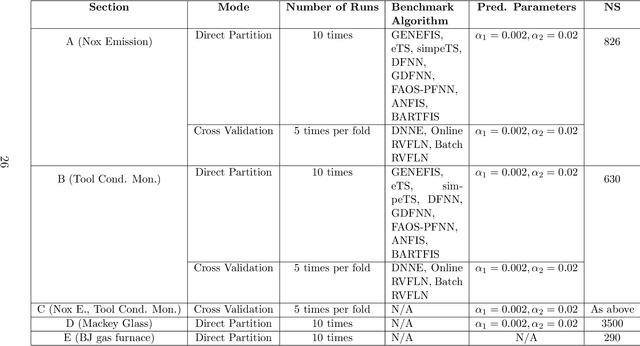
The theory of random vector functional link network (RVFLN) has provided a breakthrough in the design of neural networks (NNs) since it conveys solid theoretical justification of randomized learning. Existing works in RVFLN are hardly scalable for data stream analytics because they are inherent to the issue of complexity as a result of the absence of structural learning scenarios. A novel class of RVLFN, namely parsimonious random vector functional link network (pRVFLN), is proposed in this paper. pRVFLN features an open structure paradigm where its network structure can be built from scratch and can be automatically generated in accordance with degree of nonlinearity and time-varying property of system being modelled. pRVFLN is equipped with complexity reduction scenarios where inconsequential hidden nodes can be pruned and input features can be dynamically selected. pRVFLN puts into perspective an online active learning mechanism which expedites the training process and relieves operator labelling efforts. In addition, pRVFLN introduces a non-parametric type of hidden node, developed using an interval-valued data cloud. The hidden node completely reflects the real data distribution and is not constrained by a specific shape of the cluster. All learning procedures of pRVFLN follow a strictly single-pass learning mode, which is applicable for an online real-time deployment. The efficacy of pRVFLN was rigorously validated through numerous simulations and comparisons with state-of-the art algorithms where it produced the most encouraging numerical results. Furthermore, the robustness of pRVFLN was investigated and a new conclusion is made to the scope of random parameters where it plays vital role to the success of randomized learning.