 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInflation Attitudes of Large Language Models
Dec 16, 2025This paper investigates the ability of Large Language Models (LLMs), specifically GPT-3.5-turbo (GPT), to form inflation perceptions and expectations based on macroeconomic price signals. We compare the LLM's output to household survey data and official statistics, mimicking the information set and demographic characteristics of the Bank of England's Inflation Attitudes Survey (IAS). Our quasi-experimental design exploits the timing of GPT's training cut-off in September 2021 which means it has no knowledge of the subsequent UK inflation surge. We find that GPT tracks aggregate survey projections and official statistics at short horizons. At a disaggregated level, GPT replicates key empirical regularities of households' inflation perceptions, particularly for income, housing tenure, and social class. A novel Shapley value decomposition of LLM outputs suited for the synthetic survey setting provides well-defined insights into the drivers of model outputs linked to prompt content. We find that GPT demonstrates a heightened sensitivity to food inflation information similar to that of human respondents. However, we also find that it lacks a consistent model of consumer price inflation. More generally, our approach could be used to evaluate the behaviour of LLMs for use in the social sciences, to compare different models, or to assist in survey design.
Revealing economic facts: LLMs know more than they say
May 13, 2025We investigate whether the hidden states of large language models (LLMs) can be used to estimate and impute economic and financial statistics. Focusing on county-level (e.g. unemployment) and firm-level (e.g. total assets) variables, we show that a simple linear model trained on the hidden states of open-source LLMs outperforms the models' text outputs. This suggests that hidden states capture richer economic information than the responses of the LLMs reveal directly. A learning curve analysis indicates that only a few dozen labelled examples are sufficient for training. We also propose a transfer learning method that improves estimation accuracy without requiring any labelled data for the target variable. Finally, we demonstrate the practical utility of hidden-state representations in super-resolution and data imputation tasks.
Logistic Regression makes small LLMs strong and explainable "tens-of-shot" classifiers
Aug 06, 2024



For simple classification tasks, we show that users can benefit from the advantages of using small, local, generative language models instead of large commercial models without a trade-off in performance or introducing extra labelling costs. These advantages, including those around privacy, availability, cost, and explainability, are important both in commercial applications and in the broader democratisation of AI. Through experiments on 17 sentence classification tasks (2-4 classes), we show that penalised logistic regression on the embeddings from a small LLM equals (and usually betters) the performance of a large LLM in the "tens-of-shot" regime. This requires no more labelled instances than are needed to validate the performance of the large LLM. Finally, we extract stable and sensible explanations for classification decisions.
Solving Heterogeneous General Equilibrium Economic Models with Deep Reinforcement Learning
Mar 31, 2021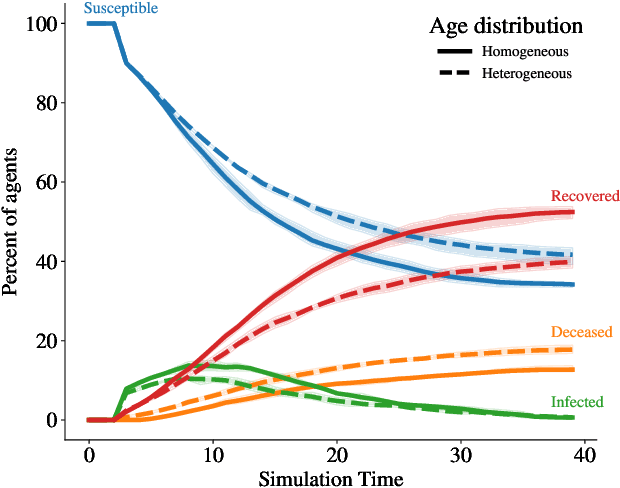
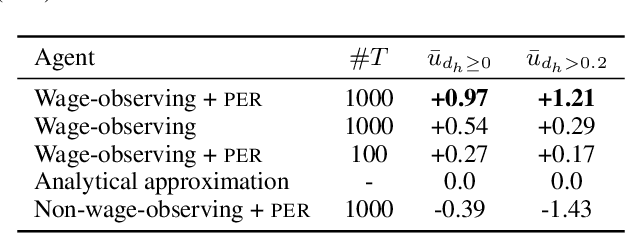
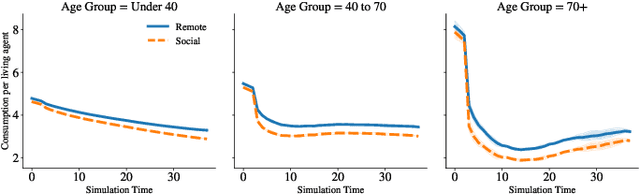
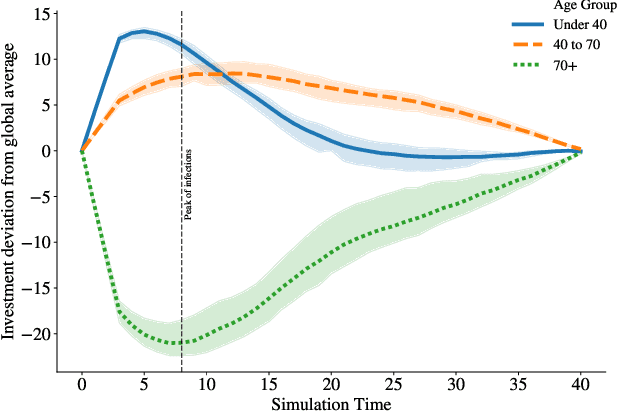
General equilibrium macroeconomic models are a core tool used by policymakers to understand a nation's economy. They represent the economy as a collection of forward-looking actors whose behaviours combine, possibly with stochastic effects, to determine global variables (such as prices) in a dynamic equilibrium. However, standard semi-analytical techniques for solving these models make it difficult to include the important effects of heterogeneous economic actors. The COVID-19 pandemic has further highlighted the importance of heterogeneity, for example in age and sector of employment, in macroeconomic outcomes and the need for models that can more easily incorporate it. We use techniques from reinforcement learning to solve such models incorporating heterogeneous agents in a way that is simple, extensible, and computationally efficient. We demonstrate the method's accuracy and stability on a toy problem for which there is a known analytical solution, its versatility by solving a general equilibrium problem that includes global stochasticity, and its flexibility by solving a combined macroeconomic and epidemiological model to explore the economic and health implications of a pandemic. The latter successfully captures plausible economic behaviours induced by differential health risks by age.