 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncovering the Genetic Basis of Glioblastoma Heterogeneity through Multimodal Analysis of Whole Slide Images and RNA Sequencing Data
Oct 23, 2024Glioblastoma is a highly aggressive form of brain cancer characterized by rapid progression and poor prognosis. Despite advances in treatment, the underlying genetic mechanisms driving this aggressiveness remain poorly understood. In this study, we employed multimodal deep learning approaches to investigate glioblastoma heterogeneity using joint image/RNA-seq analysis. Our results reveal novel genes associated with glioblastoma. By leveraging a combination of whole-slide images and RNA-seq, as well as introducing novel methods to encode RNA-seq data, we identified specific genetic profiles that may explain different patterns of glioblastoma progression. These findings provide new insights into the genetic mechanisms underlying glioblastoma heterogeneity and highlight potential targets for therapeutic intervention.
The Overfocusing Bias of Convolutional Neural Networks: A Saliency-Guided Regularization Approach
Sep 25, 2024Despite transformers being considered as the new standard in computer vision, convolutional neural networks (CNNs) still outperform them in low-data regimes. Nonetheless, CNNs often make decisions based on narrow, specific regions of input images, especially when training data is limited. This behavior can severely compromise the model's generalization capabilities, making it disproportionately dependent on certain features that might not represent the broader context of images. While the conditions leading to this phenomenon remain elusive, the primary intent of this article is to shed light on this observed behavior of neural networks. Our research endeavors to prioritize comprehensive insight and to outline an initial response to this phenomenon. In line with this, we introduce Saliency Guided Dropout (SGDrop), a pioneering regularization approach tailored to address this specific issue. SGDrop utilizes attribution methods on the feature map to identify and then reduce the influence of the most salient features during training. This process encourages the network to diversify its attention and not focus solely on specific standout areas. Our experiments across several visual classification benchmarks validate SGDrop's role in enhancing generalization. Significantly, models incorporating SGDrop display more expansive attributions and neural activity, offering a more comprehensive view of input images in contrast to their traditionally trained counterparts.
Read, look and detect: Bounding box annotation from image-caption pairs
Jun 09, 2023



Various methods have been proposed to detect objects while reducing the cost of data annotation. For instance, weakly supervised object detection (WSOD) methods rely only on image-level annotations during training. Unfortunately, data annotation remains expensive since annotators must provide the categories describing the content of each image and labeling is restricted to a fixed set of categories. In this paper, we propose a method to locate and label objects in an image by using a form of weaker supervision: image-caption pairs. By leveraging recent advances in vision-language (VL) models and self-supervised vision transformers (ViTs), our method is able to perform phrase grounding and object detection in a weakly supervised manner. Our experiments demonstrate the effectiveness of our approach by achieving a 47.51% recall@1 score in phrase grounding on Flickr30k Entities and establishing a new state-of-the-art in object detection by achieving 21.1 mAP 50 and 10.5 mAP 50:95 on MS COCO when exclusively relying on image-caption pairs.
Learning Disentangled Representations via Mutual Information Estimation
Dec 09, 2019
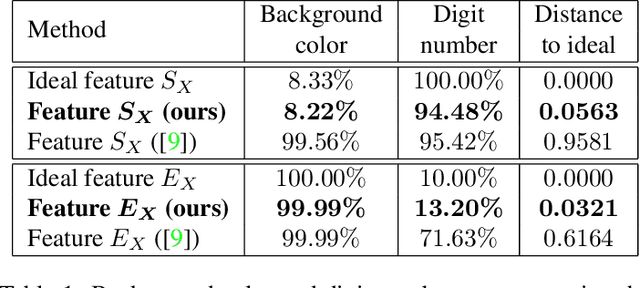
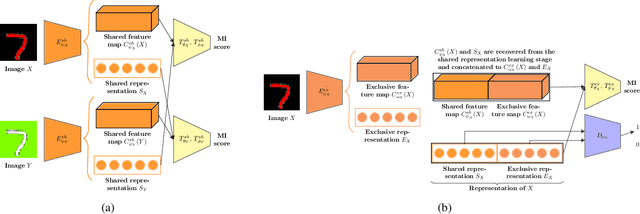
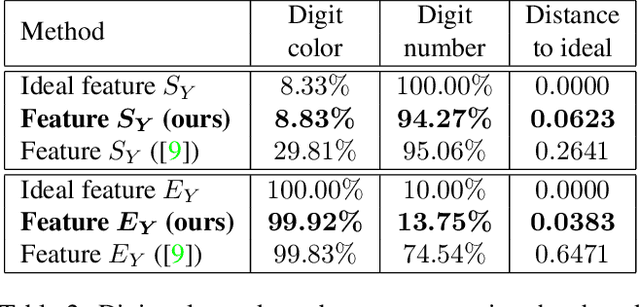
In this paper, we investigate the problem of learning disentangled representations. Given a pair of images sharing some attributes, we aim to create a low-dimensional representation which is split into two parts: a shared representation that captures the common information between the images and an exclusive representation that contains the specific information of each image. To address this issue, we propose a model based on mutual information estimation without relying on image reconstruction or image generation. Mutual information maximization is performed to capture the attributes of data in the shared and exclusive representations while we minimize the mutual information between the shared and exclusive representation to enforce representation disentanglement. We show that these representations are useful to perform downstream tasks such as image classification and image retrieval based on the shared or exclusive component. Moreover, classification results show that our model outperforms the state-of-the-art model based on VAE/GAN approaches in representation disentanglement.