 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSONIC: Spectral Oriented Neural Invariant Convolutions
Jan 27, 2026Convolutional Neural Networks (CNNs) rely on fixed-size kernels scanning local patches, which limits their ability to capture global context or long-range dependencies without very deep architectures. Vision Transformers (ViTs), in turn, provide global connectivity but lack spatial inductive bias, depend on explicit positional encodings, and remain tied to the initial patch size. Bridging these limitations requires a representation that is both structured and global. We introduce SONIC (Spectral Oriented Neural Invariant Convolutions), a continuous spectral parameterisation that models convolutional operators using a small set of shared, orientation-selective components. These components define smooth responses across the full frequency domain, yielding global receptive fields and filters that adapt naturally across resolutions. Across synthetic benchmarks, large-scale image classification, and 3D medical datasets, SONIC shows improved robustness to geometric transformations, noise, and resolution shifts, and matches or exceeds convolutional, attention-based, and prior spectral architectures with an order of magnitude fewer parameters. These results demonstrate that continuous, orientation-aware spectral parameterisations provide a principled and scalable alternative to conventional spatial and spectral operators.
Can we trust deep learning models diagnosis? The impact of domain shift in chest radiograph classification
Sep 03, 2019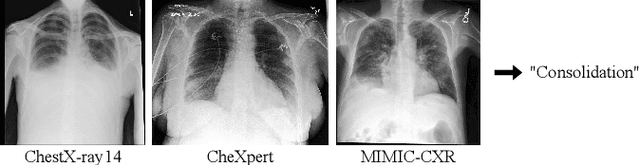

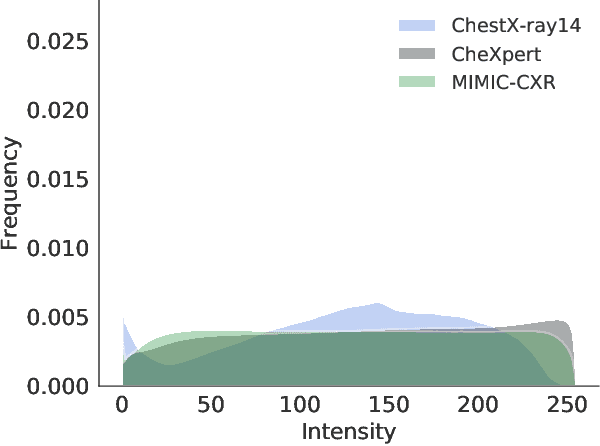
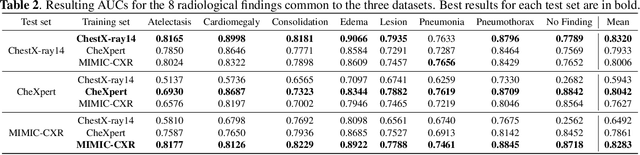
While deep learning models become more widespread, their ability to handle unseen data and generalize for any scenario is yet to be challenged. In medical imaging, there is a high heterogeneity of distributions among images based on the equipment that generate them and their parametrization. This heterogeneity triggers a common issue in machine learning called domain shift, which represents the difference between the training data distribution and the distribution of where a model is employed. A high domain shift tends to implicate in a poor performance from models. In this work, we evaluate the extent of domain shift on three of the largest datasets of chest radiographs. We show how training and testing with different datasets (e.g. training in ChestX-ray14 and testing in CheXpert) drastically affects model performance, posing a big question over the reliability of deep learning models.