 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Rank Projections of GCNs Laplacian
Jun 04, 2021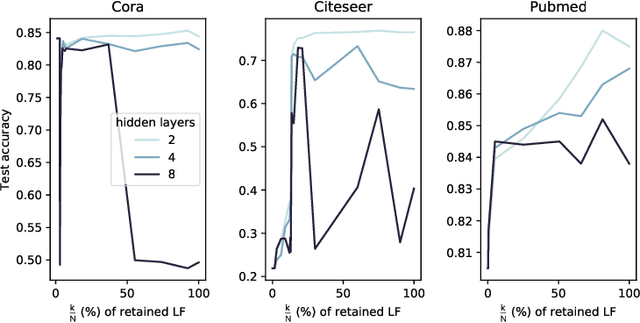
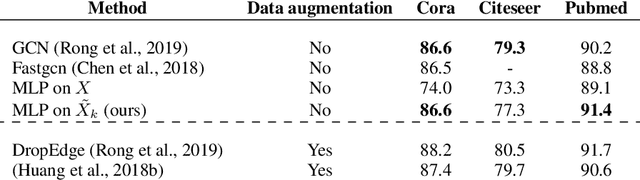
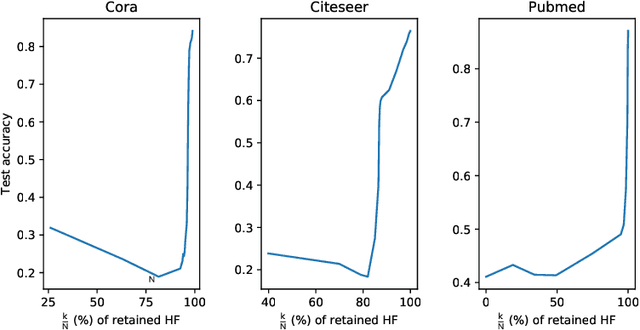

In this work, we study the behavior of standard models for community detection under spectral manipulations. Through various ablation experiments, we evaluate the impact of bandpass filtering on the performance of a GCN: we empirically show that most of the necessary and used information for nodes classification is contained in the low-frequency domain, and thus contrary to images, high frequencies are less crucial to community detection. In particular, it is sometimes possible to obtain accuracies at a state-of-the-art level with simple classifiers that rely only on a few low frequencies.
The Unreasonable Effectiveness of Patches in Deep Convolutional Kernels Methods
Jan 19, 2021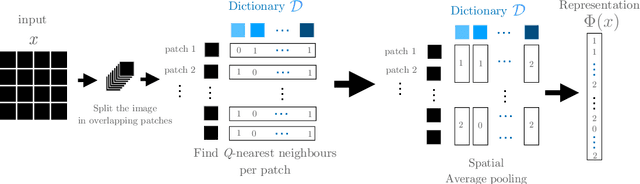
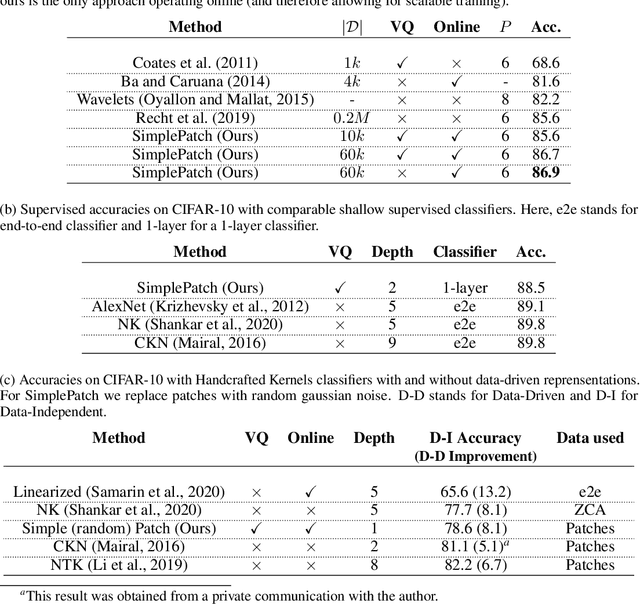

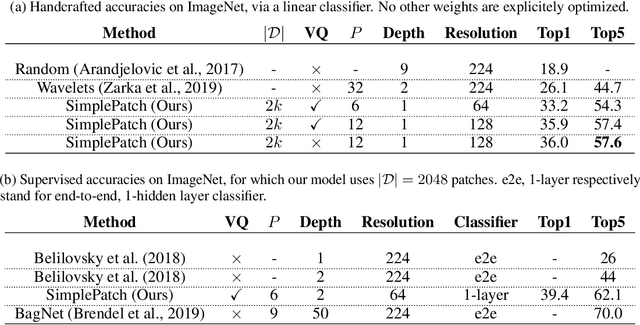
A recent line of work showed that various forms of convolutional kernel methods can be competitive with standard supervised deep convolutional networks on datasets like CIFAR-10, obtaining accuracies in the range of 87-90% while being more amenable to theoretical analysis. In this work, we highlight the importance of a data-dependent feature extraction step that is key to the obtain good performance in convolutional kernel methods. This step typically corresponds to a whitened dictionary of patches, and gives rise to a data-driven convolutional kernel methods. We extensively study its effect, demonstrating it is the key ingredient for high performance of these methods. Specifically, we show that one of the simplest instances of such kernel methods, based on a single layer of image patches followed by a linear classifier is already obtaining classification accuracies on CIFAR-10 in the same range as previous more sophisticated convolutional kernel methods. We scale this method to the challenging ImageNet dataset, showing such a simple approach can exceed all existing non-learned representation methods. This is a new baseline for object recognition without representation learning methods, that initiates the investigation of convolutional kernel models on ImageNet. We conduct experiments to analyze the dictionary that we used, our ablations showing they exhibit low-dimensional properties.
Interferometric Graph Transform: a Deep Unsupervised Graph Representation
Jun 10, 2020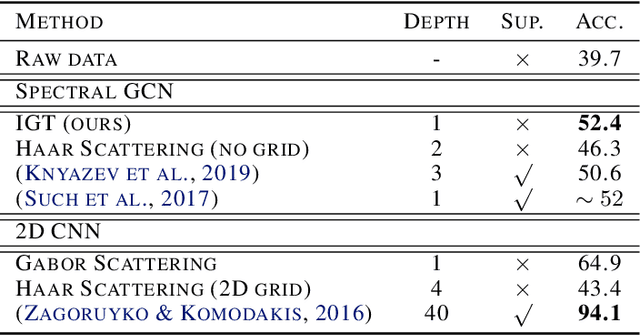

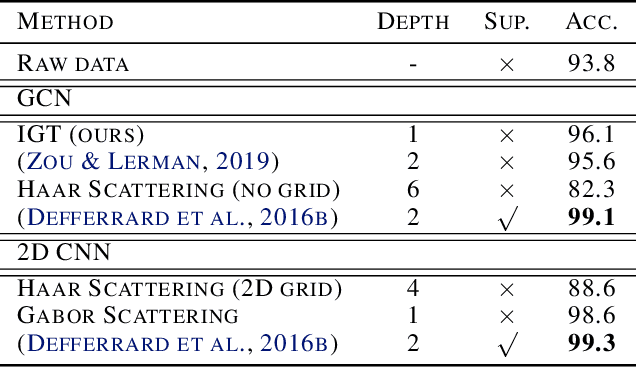
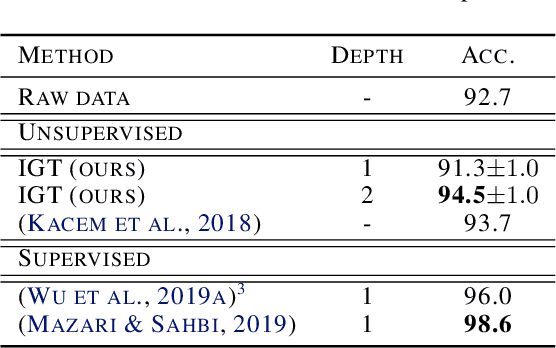
We propose the Interferometric Graph Transform (IGT), which is a new class of deep unsupervised graph convolutional neural network for building graph representations. Our first contribution is to propose a generic, complex-valued spectral graph architecture obtained from a generalization of the Euclidean Fourier transform. We show that our learned representation consists of both discriminative and invariant features, thanks to a novel greedy concave objective. From our experiments, we conclude that our learning procedure exploits the topology of the spectral domain, which is normally a flaw of spectral methods, and in particular our method can recover an analytic operator for vision tasks. We test our algorithm on various and challenging tasks such as image classification (MNIST, CIFAR-10), community detection (Authorship, Facebook graph) and action recognition from 3D skeletons videos (SBU, NTU), exhibiting a new state-of-the-art in spectral graph unsupervised settings.
Decoupled Greedy Learning of CNNs
Jan 23, 2019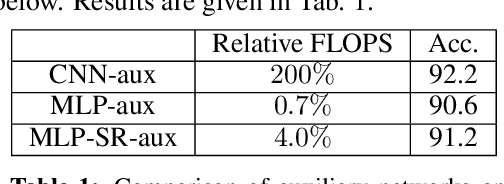
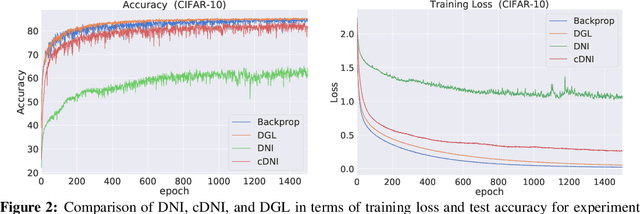
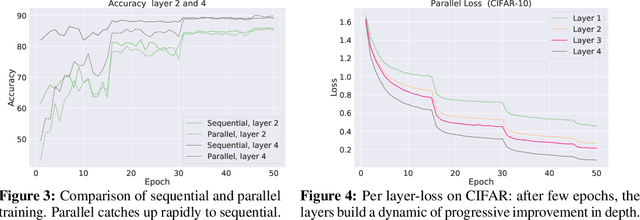

A commonly cited inefficiency of neural network training by back-propagation is the update locking problem: each layer must wait for the signal to propagate through the network before updating. We consider and analyze a training procedure, Decoupled Greedy Learning (DGL), that addresses this problem more effectively and at scales beyond those of previous solutions. It is based on a greedy relaxation of the joint training objective, recently shown to be effective in the context of Convolutional Neural Networks (CNNs) on large-scale image classification. We consider an optimization of this objective that permits us to decouple the layer training, allowing for layers or modules in networks to be trained with a potentially linear parallelization in layers. We show theoretically and empirically that this approach converges. In addition, we empirically find that it can lead to better generalization than sequential greedy optimization and even standard end-to-end back-propagation. We show that an extension of this approach to asynchronous settings, where modules can operate with large communication delays, is possible with the use of a replay buffer. We demonstrate the effectiveness of DGL on the CIFAR-10 datasets against alternatives and on the large-scale ImageNet dataset, where we are able to effectively train VGG and ResNet-152 models.
Greedy Layerwise Learning Can Scale to ImageNet
Dec 29, 2018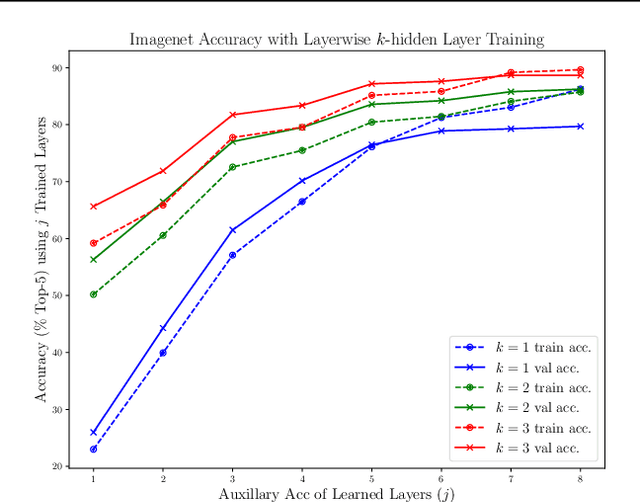
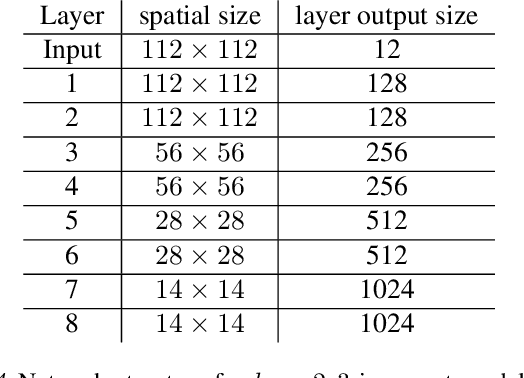
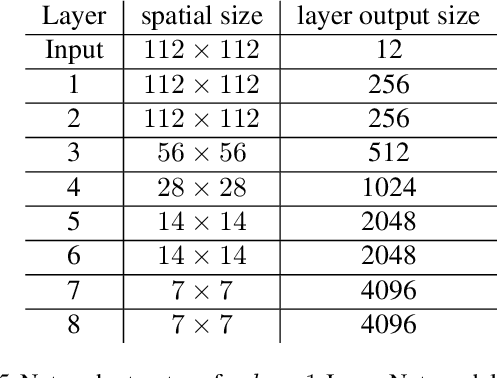
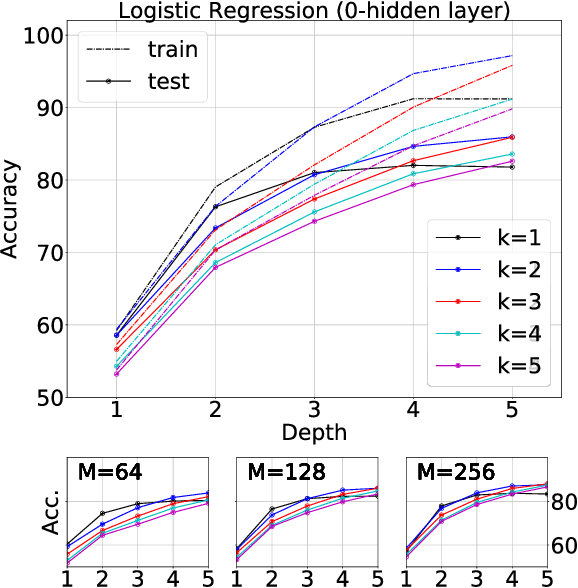
Shallow supervised 1-hidden layer neural networks have a number of favorable properties that make them easier to interpret, analyze, and optimize than their deep counterparts, but lack their representational power. Here we use 1-hidden layer learning problems to sequentially build deep networks layer by layer, which can inherit properties from shallow networks. Contrary to previous approaches using shallow networks, we focus on problems where deep learning is reported as critical for success. We thus study CNNs on image recognition tasks using the large-scale ImageNet dataset and the CIFAR-10 dataset. Using a simple set of ideas for architecture and training we find that solving sequential 1-hidden-layer auxiliary problems leads to a CNN that exceeds AlexNet performance on ImageNet. Extending our training methodology to construct individual layers by solving 2-and-3-hidden layer auxiliary problems, we obtain an 11-layer network that exceeds VGG-11 on ImageNet obtaining 89.8% top-5 single crop. To our knowledge, this is the first competitive alternative to end-to-end training of CNNs that can scale to ImageNet. We conduct a wide range of experiments to study the properties this induces on the intermediate layers.
Kymatio: Scattering Transforms in Python
Dec 28, 2018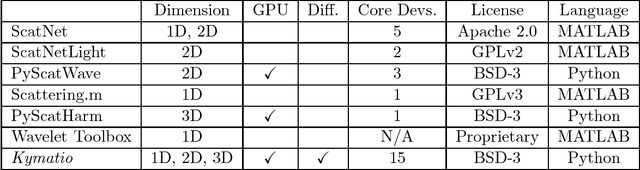
The wavelet scattering transform is an invariant signal representation suitable for many signal processing and machine learning applications. We present the Kymatio software package, an easy-to-use, high-performance Python implementation of the scattering transform in 1D, 2D, and 3D that is compatible with modern deep learning frameworks. All transforms may be executed on a GPU (in addition to CPU), offering a considerable speed up over CPU implementations. The package also has a small memory footprint, resulting inefficient memory usage. The source code, documentation, and examples are available undera BSD license at https://www.kymat.io/
Compressing the Input for CNNs with the First-Order Scattering Transform
Sep 27, 2018
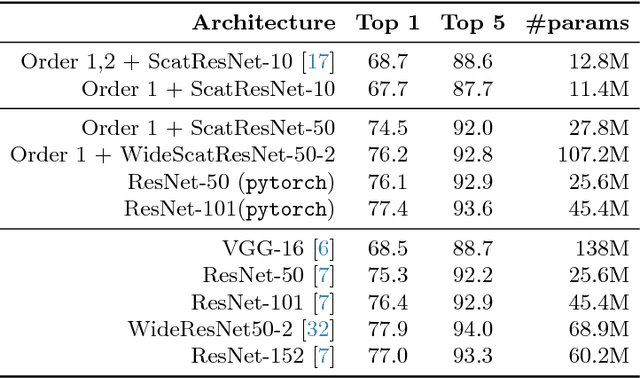
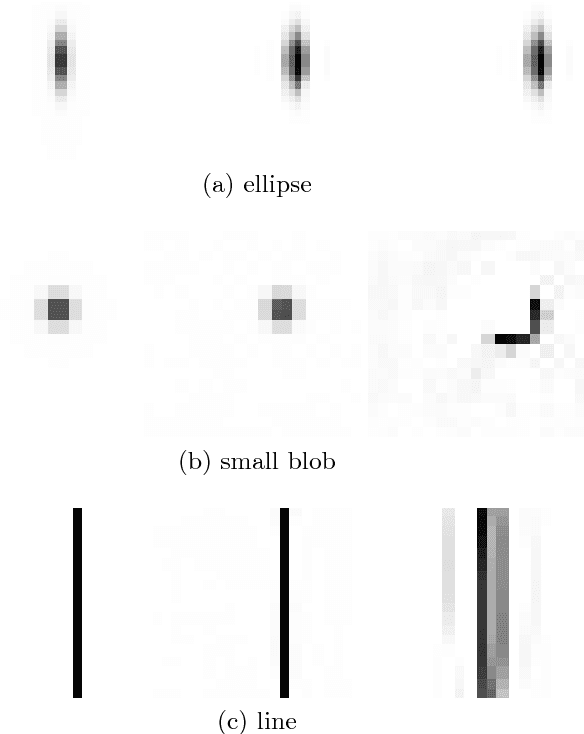
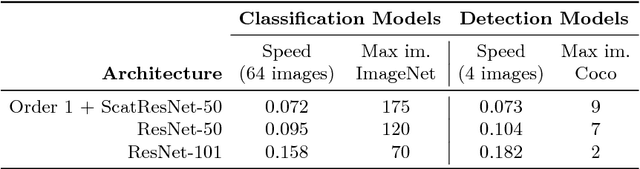
We study the first-order scattering transform as a candidate for reducing the signal processed by a convolutional neural network (CNN). We show theoretical and empirical evidence that in the case of natural images and sufficiently small translation invariance, this transform preserves most of the signal information needed for classification while substantially reducing the spatial resolution and total signal size. We demonstrate that cascading a CNN with this representation performs on par with ImageNet classification models, commonly used in downstream tasks, such as the ResNet-50. We subsequently apply our trained hybrid ImageNet model as a base model on a detection system, which has typically larger image inputs. On Pascal VOC and COCO detection tasks we demonstrate improvements in the inference speed and training memory consumption compared to models trained directly on the input image.
Scattering Networks for Hybrid Representation Learning
Sep 17, 2018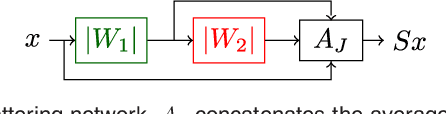
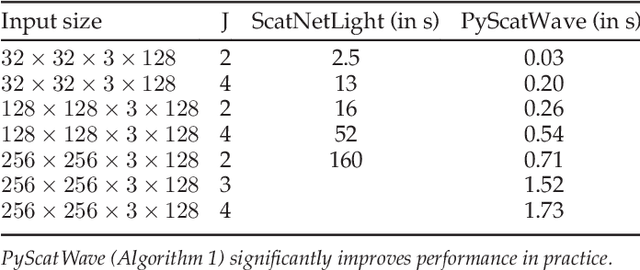
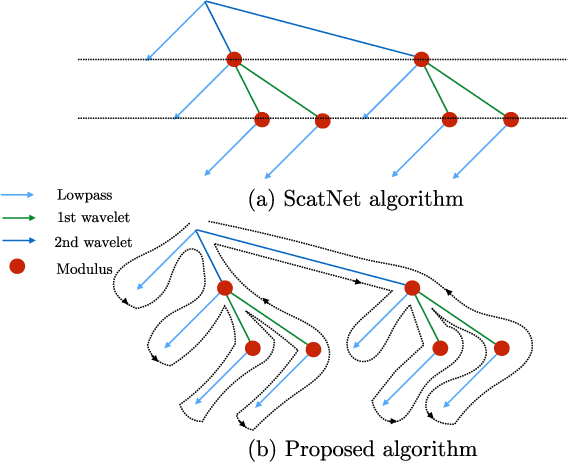
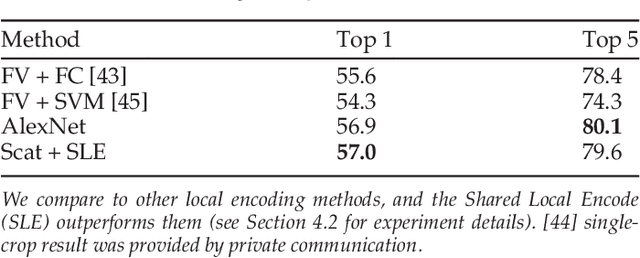
Scattering networks are a class of designed Convolutional Neural Networks (CNNs) with fixed weights. We argue they can serve as generic representations for modelling images. In particular, by working in scattering space, we achieve competitive results both for supervised and unsupervised learning tasks, while making progress towards constructing more interpretable CNNs. For supervised learning, we demonstrate that the early layers of CNNs do not necessarily need to be learned, and can be replaced with a scattering network instead. Indeed, using hybrid architectures, we achieve the best results with predefined representations to-date, while being competitive with end-to-end learned CNNs. Specifically, even applying a shallow cascade of small-windowed scattering coefficients followed by 1$\times$1-convolutions results in AlexNet accuracy on the ILSVRC2012 classification task. Moreover, by combining scattering networks with deep residual networks, we achieve a single-crop top-5 error of 11.4% on ILSVRC2012. Also, we show they can yield excellent performance in the small sample regime on CIFAR-10 and STL-10 datasets, exceeding their end-to-end counterparts, through their ability to incorporate geometrical priors. For unsupervised learning, scattering coefficients can be a competitive representation that permits image recovery. We use this fact to train hybrid GANs to generate images. Finally, we empirically analyze several properties related to stability and reconstruction of images from scattering coefficients.
* arXiv admin note: substantial text overlap with arXiv:1703.08961
Nonlinear Acceleration of CNNs
Jun 01, 2018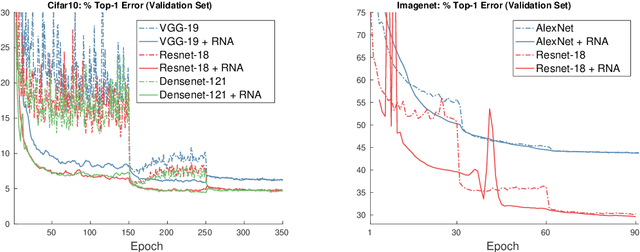
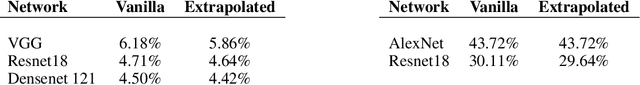
The Regularized Nonlinear Acceleration (RNA) algorithm is an acceleration method capable of improving the rate of convergence of many optimization schemes such as gradient descend, SAGA or SVRG. Until now, its analysis is limited to convex problems, but empirical observations shows that RNA may be extended to wider settings. In this paper, we investigate further the benefits of RNA when applied to neural networks, in particular for the task of image recognition on CIFAR10 and ImageNet. With very few modifications of exiting frameworks, RNA improves slightly the optimization process of CNNs, after training.
Nonlinear Acceleration of Deep Neural Networks
May 24, 2018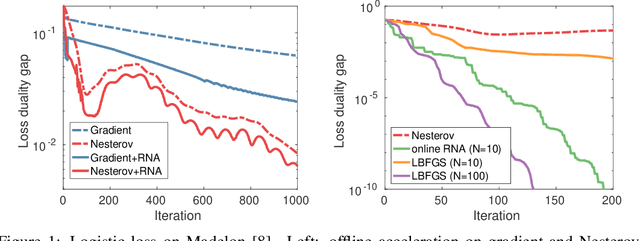
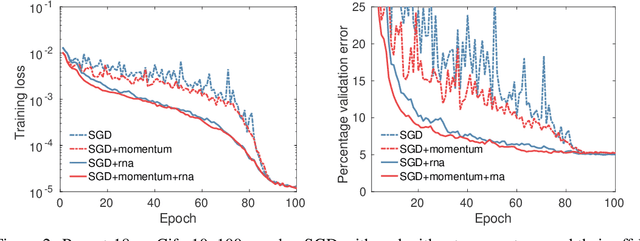

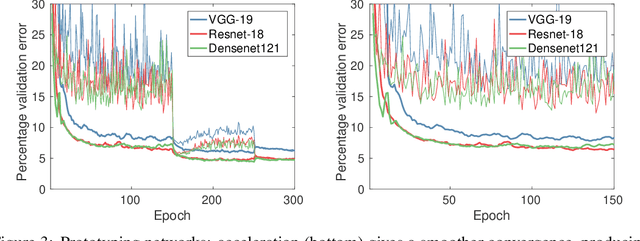
Regularized nonlinear acceleration (RNA) is a generic extrapolation scheme for optimization methods, with marginal computational overhead. It aims to improve convergence using only the iterates of simple iterative algorithms. However, so far its application to optimization was theoretically limited to gradient descent and other single-step algorithms. Here, we adapt RNA to a much broader setting including stochastic gradient with momentum and Nesterov's fast gradient. We use it to train deep neural networks, and empirically observe that extrapolated networks are more accurate, especially in the early iterations. A straightforward application of our algorithm when training ResNet-152 on ImageNet produces a top-1 test error of 20.88%, improving by 0.8% the reference classification pipeline. Furthermore, the code runs offline in this case, so it never negatively affects performance.