 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoss in Translation: Learning Bilingual Word Mapping with a Retrieval Criterion
Sep 05, 2018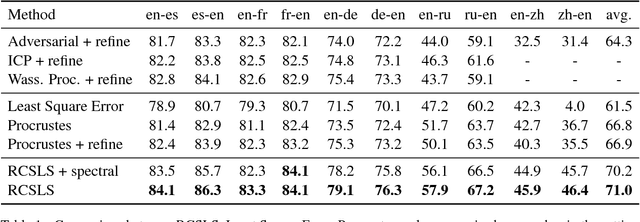
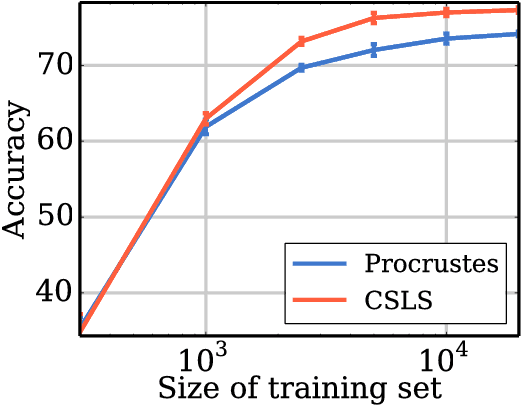
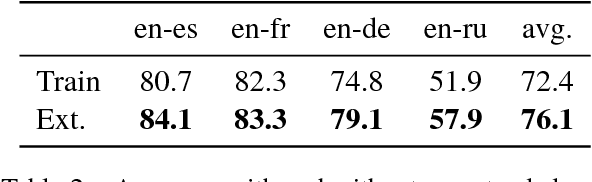
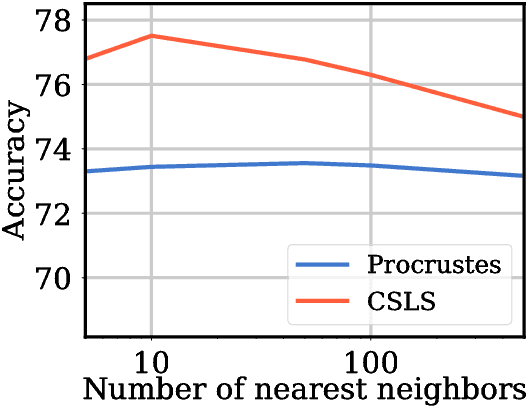
Continuous word representations learned separately on distinct languages can be aligned so that their words become comparable in a common space. Existing works typically solve a least-square regression problem to learn a rotation aligning a small bilingual lexicon, and use a retrieval criterion for inference. In this paper, we propose an unified formulation that directly optimizes a retrieval criterion in an end-to-end fashion. Our experiments on standard benchmarks show that our approach outperforms the state of the art on word translation, with the biggest improvements observed for distant language pairs such as English-Chinese.
Unsupervised Alignment of Embeddings with Wasserstein Procrustes
May 29, 2018

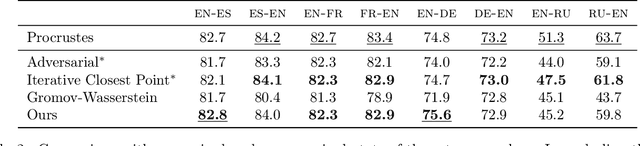

We consider the task of aligning two sets of points in high dimension, which has many applications in natural language processing and computer vision. As an example, it was recently shown that it is possible to infer a bilingual lexicon, without supervised data, by aligning word embeddings trained on monolingual data. These recent advances are based on adversarial training to learn the mapping between the two embeddings. In this paper, we propose to use an alternative formulation, based on the joint estimation of an orthogonal matrix and a permutation matrix. While this problem is not convex, we propose to initialize our optimization algorithm by using a convex relaxation, traditionally considered for the graph isomorphism problem. We propose a stochastic algorithm to minimize our cost function on large scale problems. Finally, we evaluate our method on the problem of unsupervised word translation, by aligning word embeddings trained on monolingual data. On this task, our method obtains state of the art results, while requiring less computational resources than competing approaches.
Colorless green recurrent networks dream hierarchically
Mar 29, 2018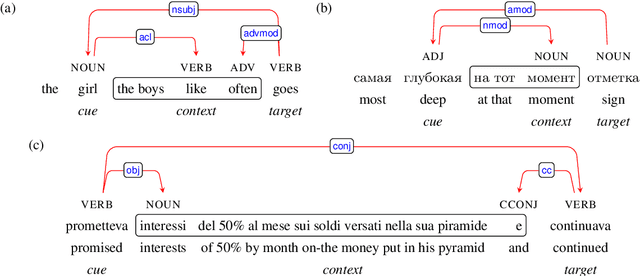
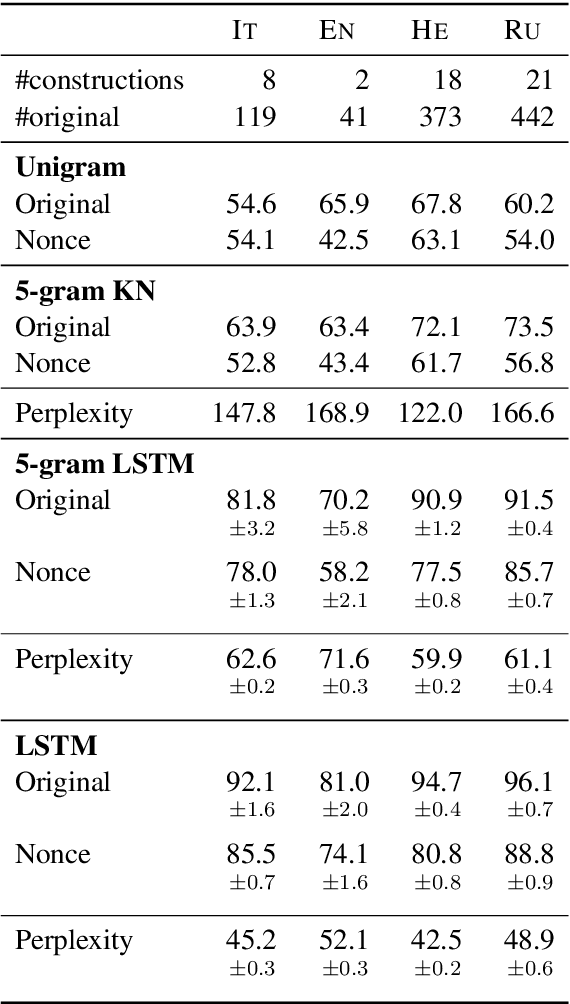
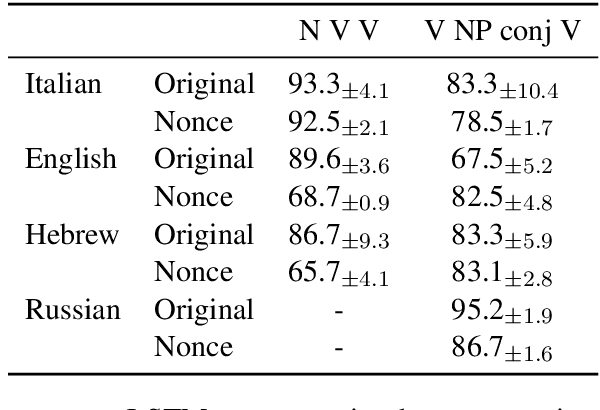
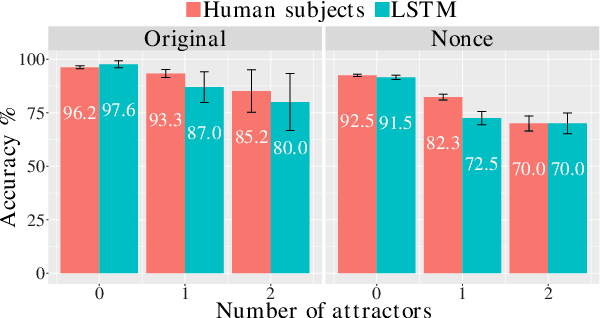
Recurrent neural networks (RNNs) have achieved impressive results in a variety of linguistic processing tasks, suggesting that they can induce non-trivial properties of language. We investigate here to what extent RNNs learn to track abstract hierarchical syntactic structure. We test whether RNNs trained with a generic language modeling objective in four languages (Italian, English, Hebrew, Russian) can predict long-distance number agreement in various constructions. We include in our evaluation nonsensical sentences where RNNs cannot rely on semantic or lexical cues ("The colorless green ideas I ate with the chair sleep furiously"), and, for Italian, we compare model performance to human intuitions. Our language-model-trained RNNs make reliable predictions about long-distance agreement, and do not lag much behind human performance. We thus bring support to the hypothesis that RNNs are not just shallow-pattern extractors, but they also acquire deeper grammatical competence.
Learning Word Vectors for 157 Languages
Mar 28, 2018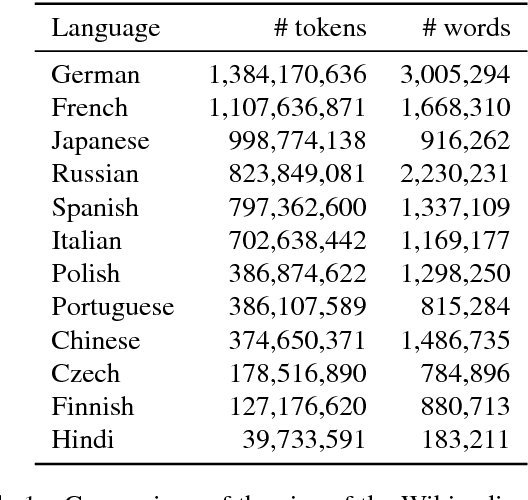
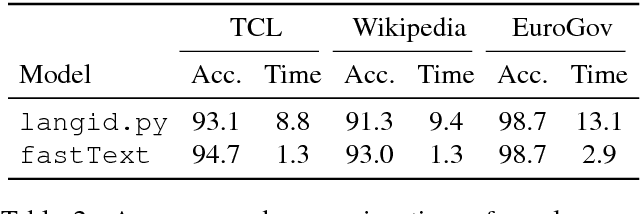
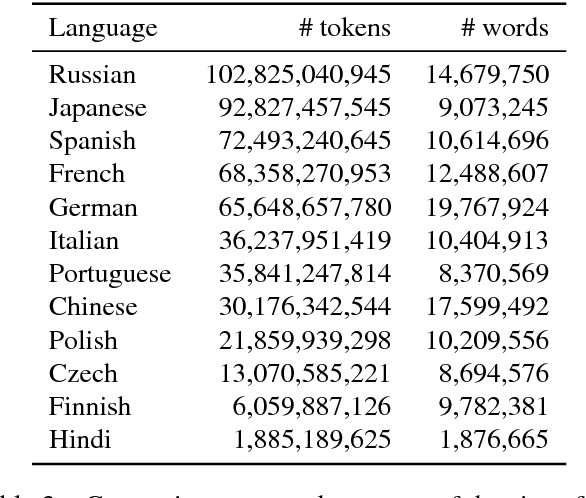
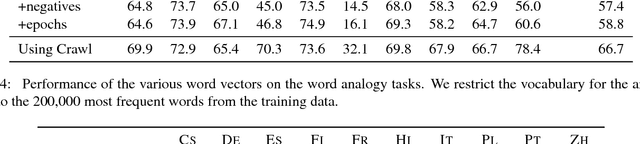
Distributed word representations, or word vectors, have recently been applied to many tasks in natural language processing, leading to state-of-the-art performance. A key ingredient to the successful application of these representations is to train them on very large corpora, and use these pre-trained models in downstream tasks. In this paper, we describe how we trained such high quality word representations for 157 languages. We used two sources of data to train these models: the free online encyclopedia Wikipedia and data from the common crawl project. We also introduce three new word analogy datasets to evaluate these word vectors, for French, Hindi and Polish. Finally, we evaluate our pre-trained word vectors on 10 languages for which evaluation datasets exists, showing very strong performance compared to previous models.
Advances in Pre-Training Distributed Word Representations
Dec 26, 2017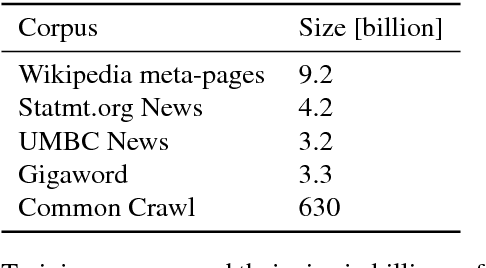

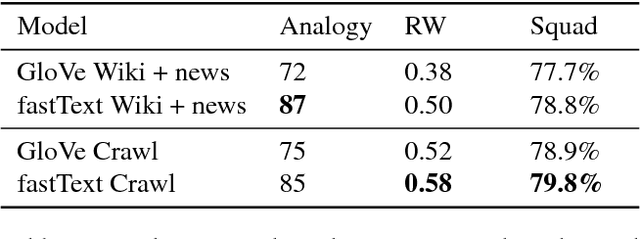
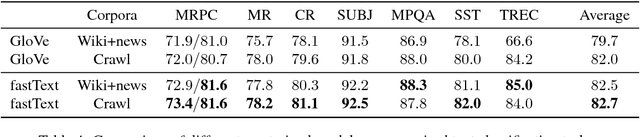
Many Natural Language Processing applications nowadays rely on pre-trained word representations estimated from large text corpora such as news collections, Wikipedia and Web Crawl. In this paper, we show how to train high-quality word vector representations by using a combination of known tricks that are however rarely used together. The main result of our work is the new set of publicly available pre-trained models that outperform the current state of the art by a large margin on a number of tasks.
Unbounded cache model for online language modeling with open vocabulary
Nov 07, 2017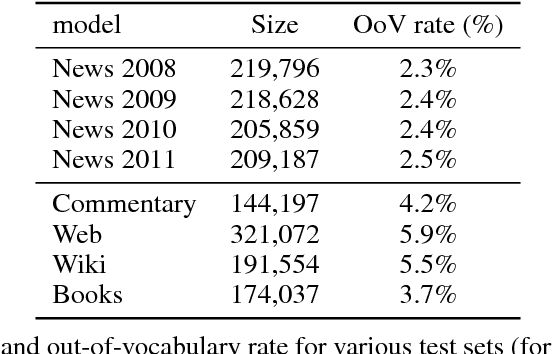
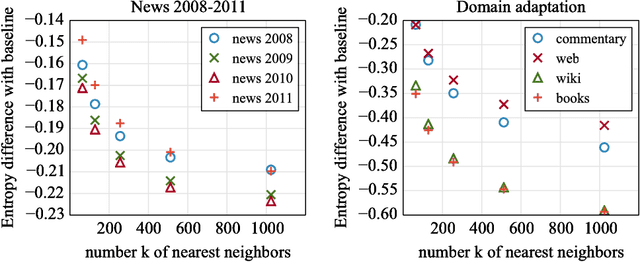
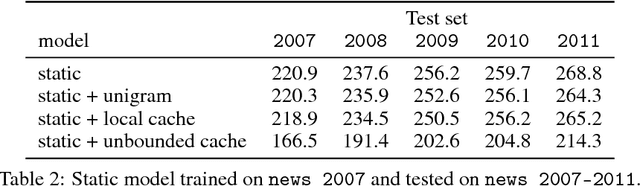
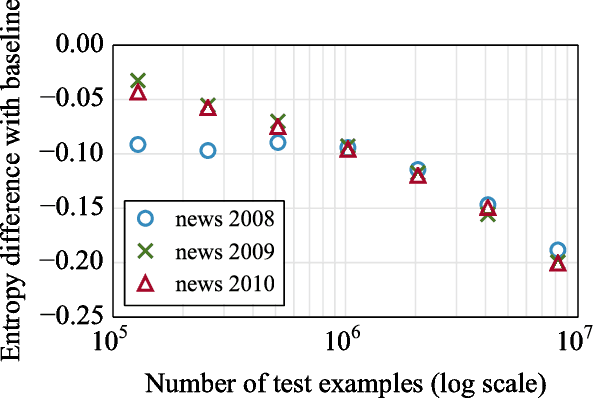
Recently, continuous cache models were proposed as extensions to recurrent neural network language models, to adapt their predictions to local changes in the data distribution. These models only capture the local context, of up to a few thousands tokens. In this paper, we propose an extension of continuous cache models, which can scale to larger contexts. In particular, we use a large scale non-parametric memory component that stores all the hidden activations seen in the past. We leverage recent advances in approximate nearest neighbor search and quantization algorithms to store millions of representations while searching them efficiently. We conduct extensive experiments showing that our approach significantly improves the perplexity of pre-trained language models on new distributions, and can scale efficiently to much larger contexts than previously proposed local cache models.
Fast Linear Model for Knowledge Graph Embeddings
Oct 30, 2017



This paper shows that a simple baseline based on a Bag-of-Words (BoW) representation learns surprisingly good knowledge graph embeddings. By casting knowledge base completion and question answering as supervised classification problems, we observe that modeling co-occurences of entities and relations leads to state-of-the-art performance with a training time of a few minutes using the open sourced library fastText.
Enriching Word Vectors with Subword Information
Jun 19, 2017Continuous word representations, trained on large unlabeled corpora are useful for many natural language processing tasks. Popular models that learn such representations ignore the morphology of words, by assigning a distinct vector to each word. This is a limitation, especially for languages with large vocabularies and many rare words. In this paper, we propose a new approach based on the skipgram model, where each word is represented as a bag of character $n$-grams. A vector representation is associated to each character $n$-gram; words being represented as the sum of these representations. Our method is fast, allowing to train models on large corpora quickly and allows us to compute word representations for words that did not appear in the training data. We evaluate our word representations on nine different languages, both on word similarity and analogy tasks. By comparing to recently proposed morphological word representations, we show that our vectors achieve state-of-the-art performance on these tasks.
Efficient softmax approximation for GPUs
Jun 19, 2017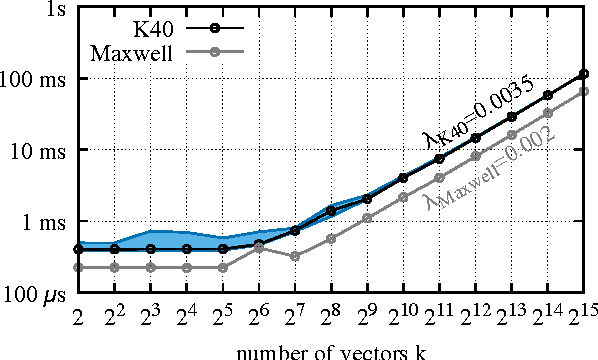
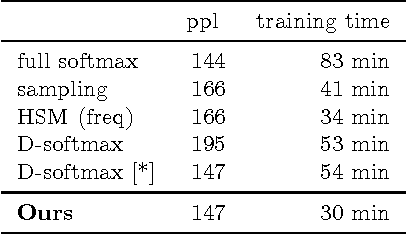
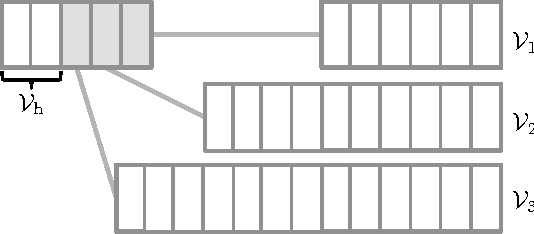
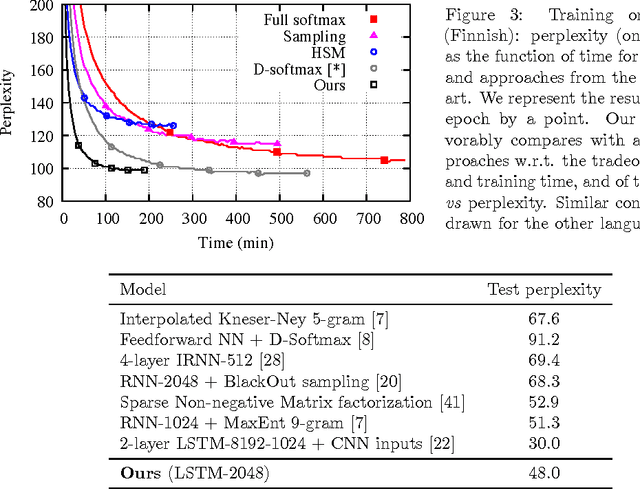
We propose an approximate strategy to efficiently train neural network based language models over very large vocabularies. Our approach, called adaptive softmax, circumvents the linear dependency on the vocabulary size by exploiting the unbalanced word distribution to form clusters that explicitly minimize the expectation of computation time. Our approach further reduces the computational time by exploiting the specificities of modern architectures and matrix-matrix vector operations, making it particularly suited for graphical processing units. Our experiments carried out on standard benchmarks, such as EuroParl and One Billion Word, show that our approach brings a large gain in efficiency over standard approximations while achieving an accuracy close to that of the full softmax. The code of our method is available at https://github.com/facebookresearch/adaptive-softmax.
Parseval Networks: Improving Robustness to Adversarial Examples
May 02, 2017
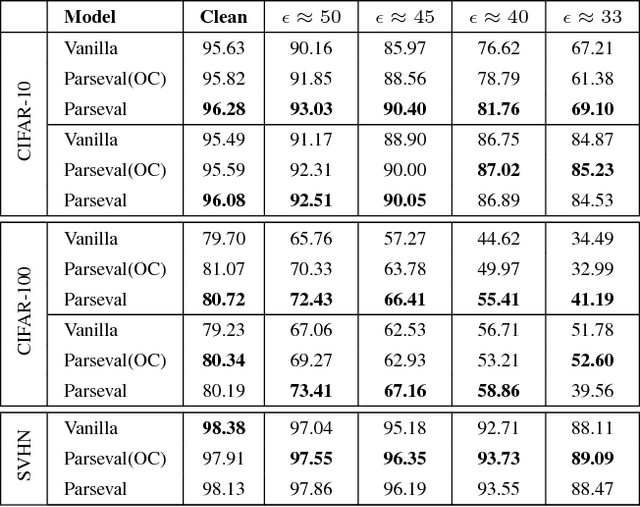
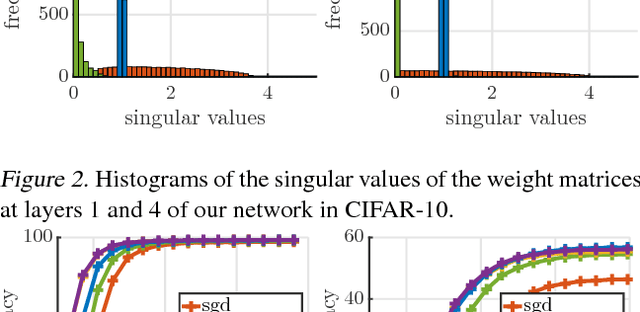
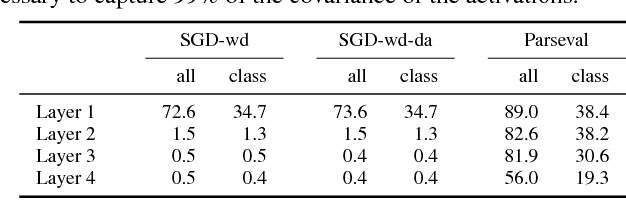
We introduce Parseval networks, a form of deep neural networks in which the Lipschitz constant of linear, convolutional and aggregation layers is constrained to be smaller than 1. Parseval networks are empirically and theoretically motivated by an analysis of the robustness of the predictions made by deep neural networks when their input is subject to an adversarial perturbation. The most important feature of Parseval networks is to maintain weight matrices of linear and convolutional layers to be (approximately) Parseval tight frames, which are extensions of orthogonal matrices to non-square matrices. We describe how these constraints can be maintained efficiently during SGD. We show that Parseval networks match the state-of-the-art in terms of accuracy on CIFAR-10/100 and Street View House Numbers (SVHN) while being more robust than their vanilla counterpart against adversarial examples. Incidentally, Parseval networks also tend to train faster and make a better usage of the full capacity of the networks.