 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUNet: A Compact Unsupervised Network for Image Classification
Jul 06, 2016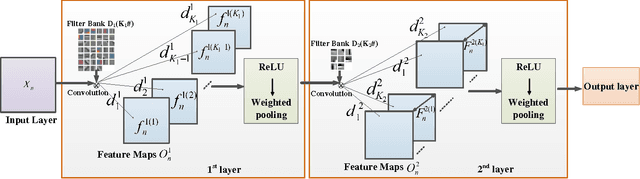
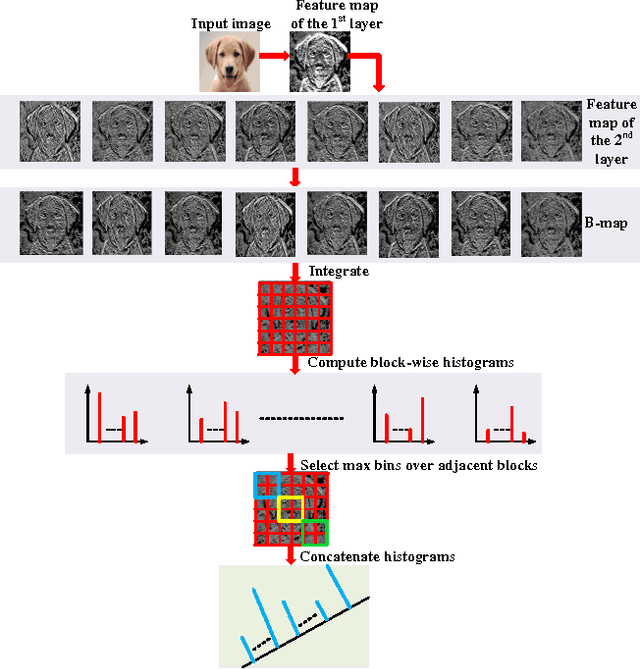


In this paper, we propose a compact network called CUNet (compact unsupervised network) to counter the image classification challenge. Different from the traditional convolutional neural networks learning filters by the time-consuming stochastic gradient descent, CUNet learns the filter bank from diverse image patches with the simple K-means, which significantly avoids the requirement of scarce labeled training images, reduces the training consumption, and maintains the high discriminative ability. Besides, we propose a new pooling method named weighted pooling considering the different weight values of adjacent neurons, which helps to improve the robustness to small image distortions. In the output layer, CUNet integrates the feature maps gained in the last hidden layer, and straightforwardly computes histograms in non-overlapped blocks. To reduce feature redundancy, we implement the max-pooling operation on adjacent blocks to select the most competitive features. Comprehensive experiments are conducted to demonstrate the state-of-the-art classification performances with CUNet on CIFAR-10, STL-10, MNIST and Caltech101 benchmark datasets.
Approximated Robust Principal Component Analysis for Improved General Scene Background Subtraction
Mar 18, 2016

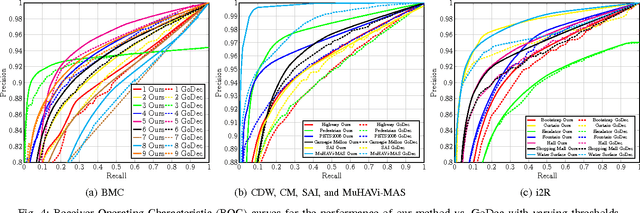
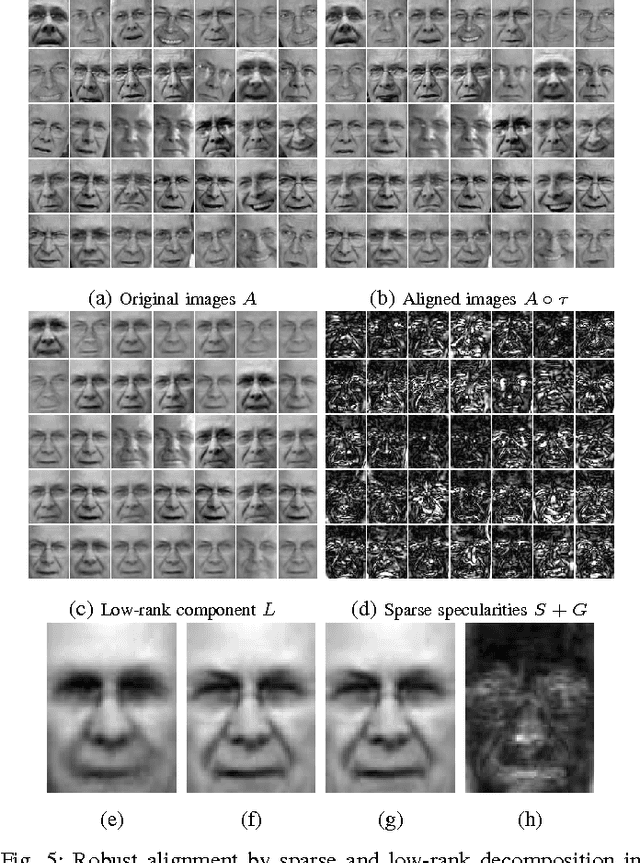
The research reported in this paper addresses the fundamental task of separation of locally moving or deforming image areas from a static or globally moving background. It builds on the latest developments in the field of robust principal component analysis, specifically, the recently reported practical solutions for the long-standing problem of recovering the low-rank and sparse parts of a large matrix made up of the sum of these two components. This article addresses a few critical issues including: embedding global motion parameters in the matrix decomposition model, i.e., estimation of global motion parameters simultaneously with the foreground/background separation task, considering matrix block-sparsity rather than generic matrix sparsity as natural feature in video processing applications, attenuating background ghosting effects when foreground is subtracted, and more critically providing an extremely efficient algorithm to solve the low-rank/sparse matrix decomposition task. The first aspect is important for background/foreground separation in generic video sequences where the background usually obeys global displacements originated by the camera motion in the capturing process. The second aspect exploits the fact that in video processing applications the sparse matrix has a very particular structure, where the non-zero matrix entries are not randomly distributed but they build small blocks within the sparse matrix. The next feature of the proposed approach addresses removal of ghosting effects originated from foreground silhouettes and the lack of information in the occluded background regions of the image. Finally, the proposed model also tackles algorithmic complexity by introducing an extremely efficient "SVD-free" technique that can be applied in most background/foreground separation tasks for conventional video processing.
Reflection Invariance: an important consideration of image orientation
Jun 08, 2015
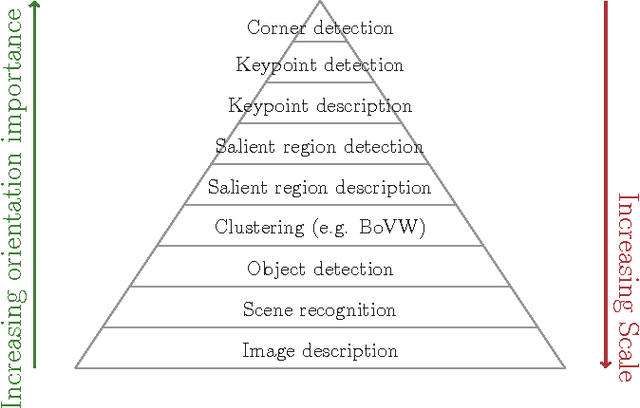
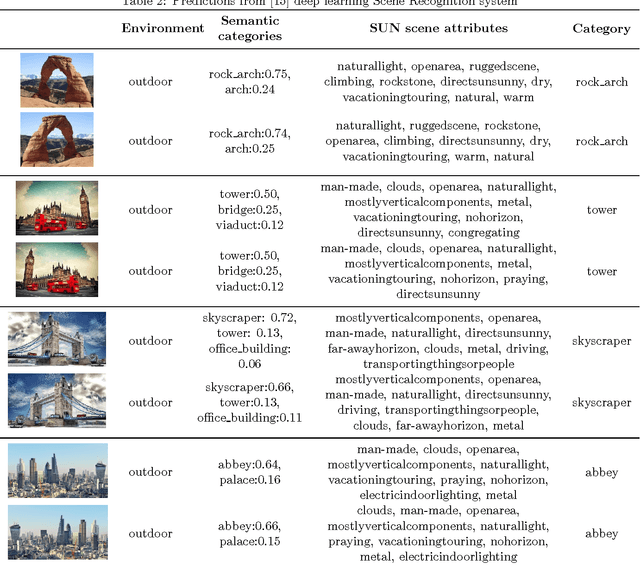
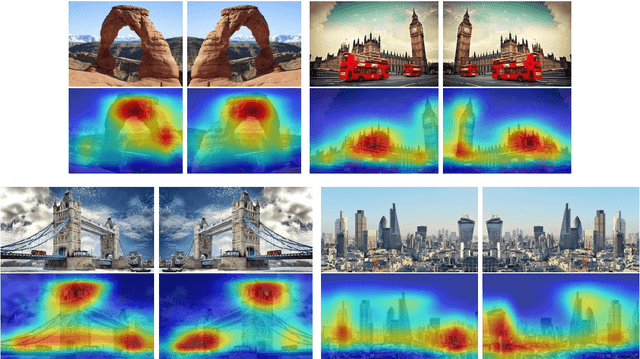
In this position paper, we consider the state of computer vision research with respect to invariance to the horizontal orientation of an image -- what we term reflection invariance. We describe why we consider reflection invariance to be an important property and provide evidence where the absence of this invariance produces surprising inconsistencies in state-of-the-art systems. We demonstrate inconsistencies in methods of object detection and scene classification when they are presented with images and the horizontal mirror of those images. Finally, we examine where some of the invariance is exhibited in feature detection and descriptors, and make a case for future consideration of reflection invariance as a measure of quality in computer vision algorithms.